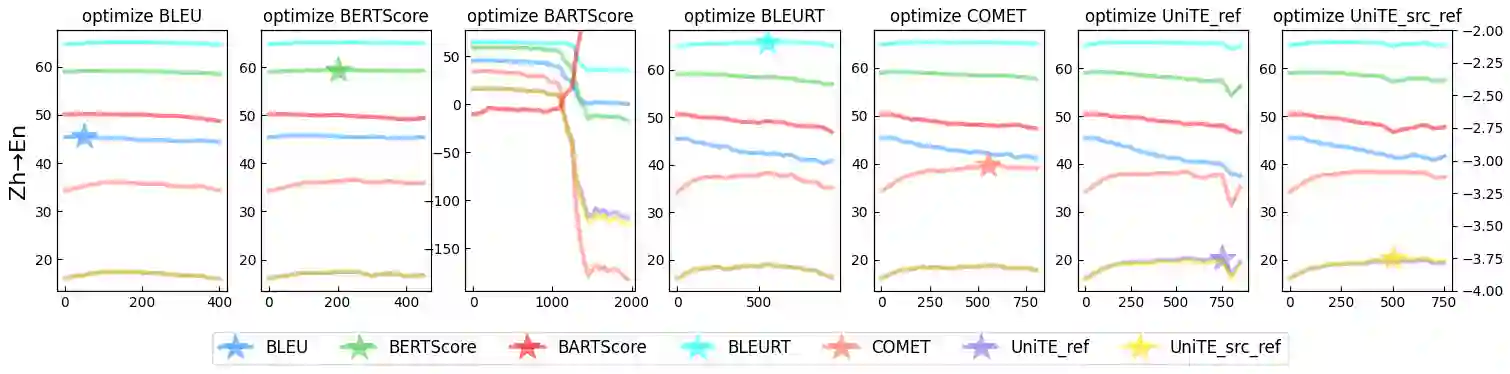
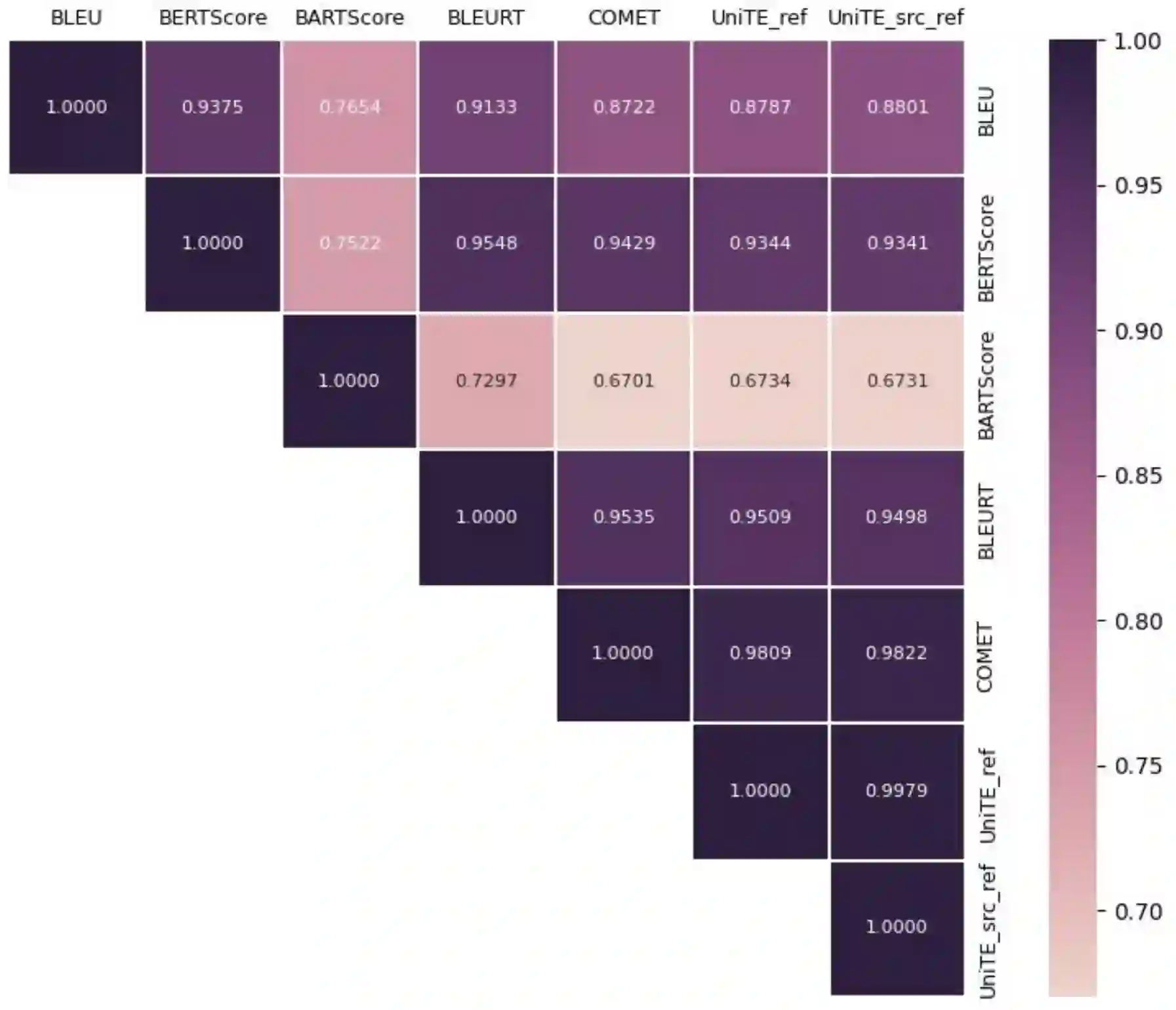
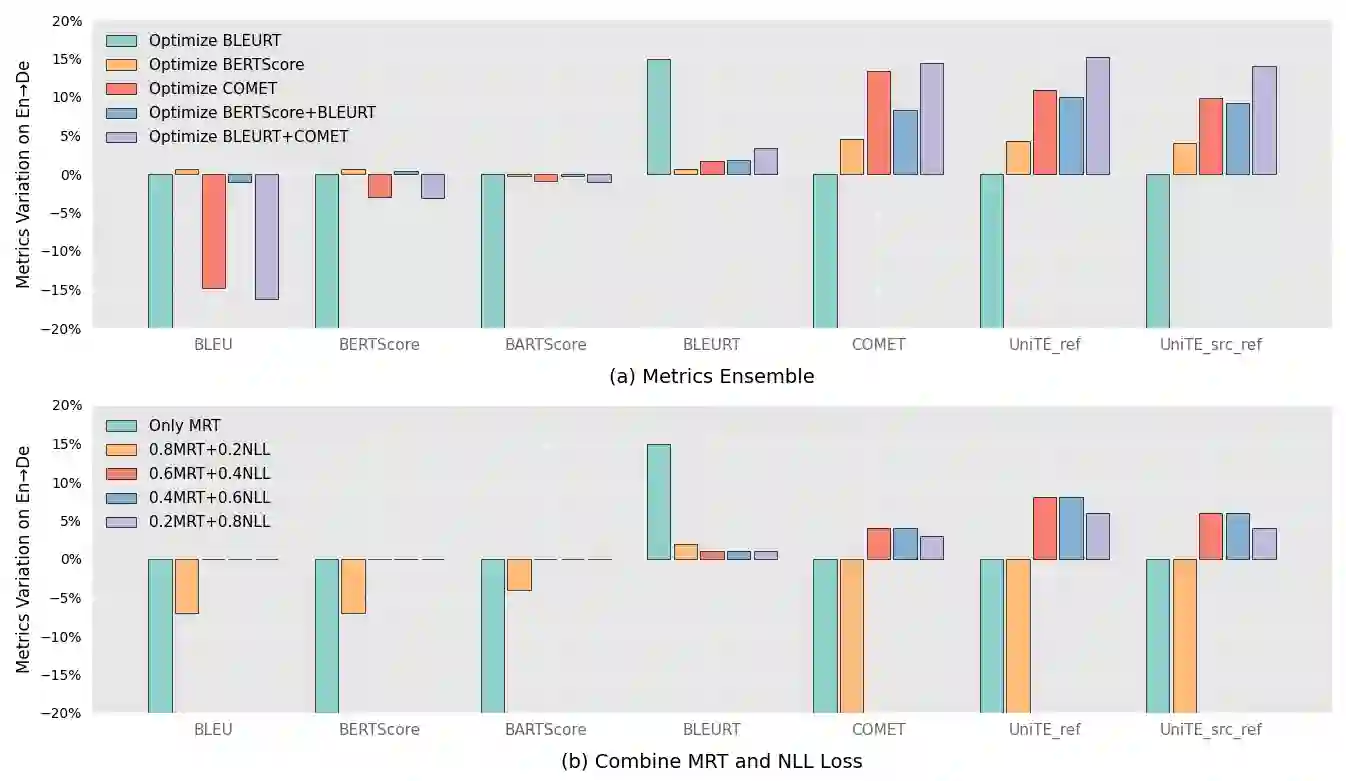
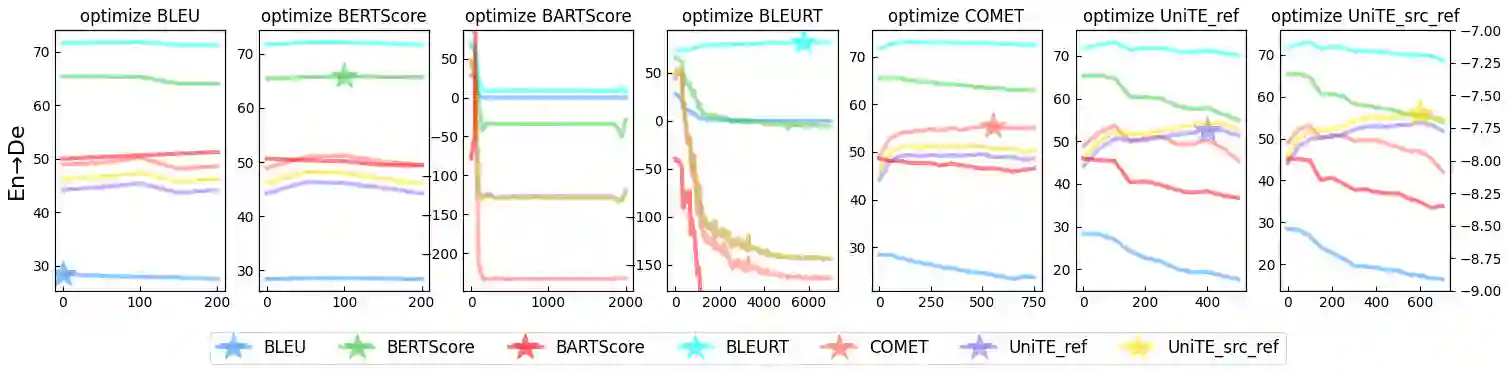
Automatic metrics play a crucial role in machine translation. Despite the widespread use of n-gram-based metrics, there has been a recent surge in the development of pre-trained model-based metrics that focus on measuring sentence semantics. However, these neural metrics, while achieving higher correlations with human evaluations, are often considered to be black boxes with potential biases that are difficult to detect. In this study, we systematically analyze and compare various mainstream and cutting-edge automatic metrics from the perspective of their guidance for training machine translation systems. Through Minimum Risk Training (MRT), we find that certain metrics exhibit robustness defects, such as the presence of universal adversarial translations in BLEURT and BARTScore. In-depth analysis suggests two main causes of these robustness deficits: distribution biases in the training datasets, and the tendency of the metric paradigm. By incorporating token-level constraints, we enhance the robustness of evaluation metrics, which in turn leads to an improvement in the performance of machine translation systems. Codes are available at \url{https://github.com/powerpuffpomelo/fairseq_mrt}.
翻译:自动评估指标在机器翻译中扮演着至关重要的角色。尽管基于n-gram的指标被广泛使用,但近年来,专注于衡量句子语义的预训练模型指标得到了迅速发展。然而,这些神经指标虽然与人类评估的相关性更高,但通常被视为难以检测潜在偏差的黑盒模型。在本研究中,我们从引导机器翻译系统训练的角度,系统性地分析并比较了多种主流及前沿自动指标。通过最小风险训练(MRT),我们发现某些指标存在鲁棒性缺陷,例如BLEURT和BARTScore中存在通用对抗翻译。深入分析表明,这些鲁棒性缺陷主要由两个原因导致:训练数据集的分布偏差,以及指标范式的倾向性。通过引入词元级约束,我们增强了评估指标的鲁棒性,进而提升了机器翻译系统的性能。代码已开源在\url{https://github.com/powerpuffpomelo/fairseq_mrt}。