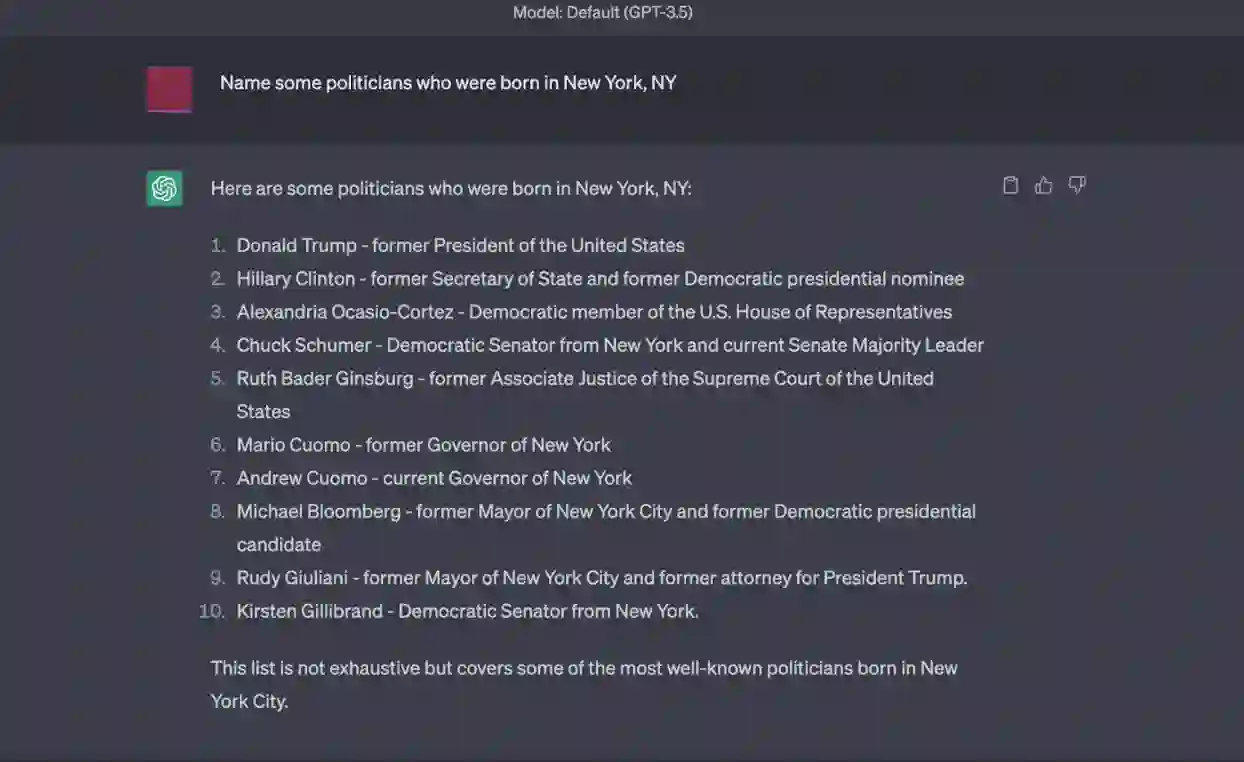
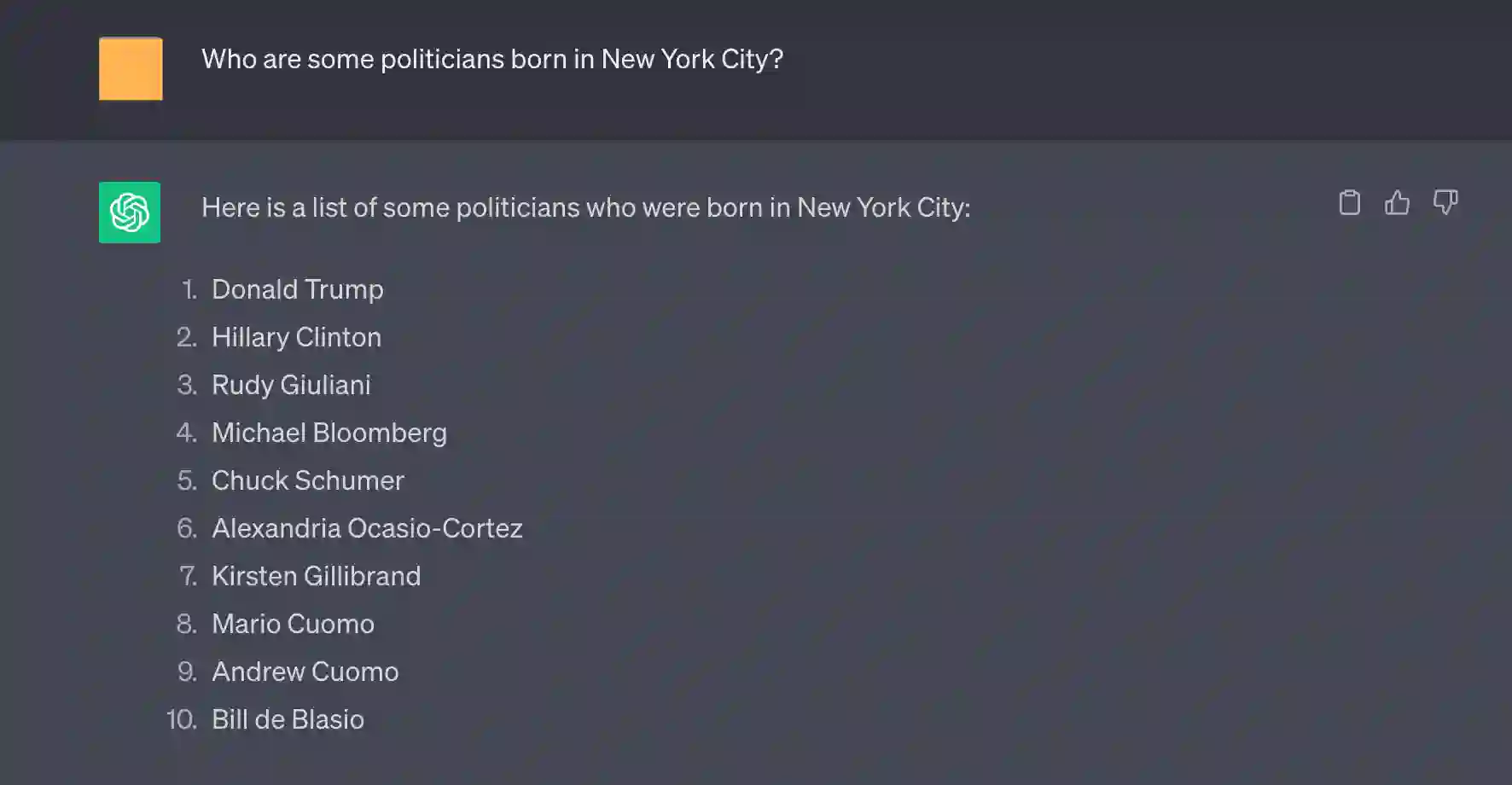
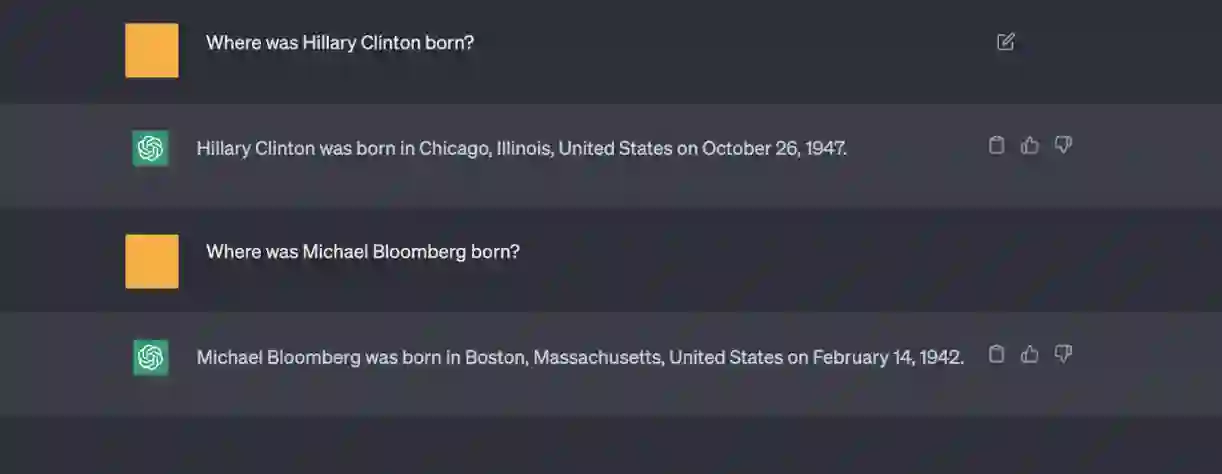
Generation of plausible yet incorrect factual information, termed hallucination, is an unsolved issue in large language models. We study the ability of language models to deliberate on the responses they give in order to correct their mistakes. We develop the Chain-of-Verification (CoVe) method whereby the model first (i) drafts an initial response; then (ii) plans verification questions to fact-check its draft; (iii) answers those questions independently so the answers are not biased by other responses; and (iv) generates its final verified response. In experiments, we show CoVe decreases hallucinations across a variety of tasks, from list-based questions from Wikidata, closed book MultiSpanQA and longform text generation.
翻译:生成看似合理但实际错误的虚假信息(即幻觉)是大型语言模型中尚未解决的问题。我们研究语言模型通过自我反思纠正自身回答错误的能力。我们提出链式验证(Chain-of-Verification, CoVe)方法,该方法首先让模型(i)草拟初步回答;(ii)规划验证性问题以事实核查其草稿;(iii)独立回答这些问题以避免其他回答带来的偏差;最后(iv)生成经过验证的最终回答。实验表明,CoVe在多种任务中均能减少幻觉现象,包括基于Wikidata的列表型问题、闭卷MultiSpanQA任务以及长文本生成任务。