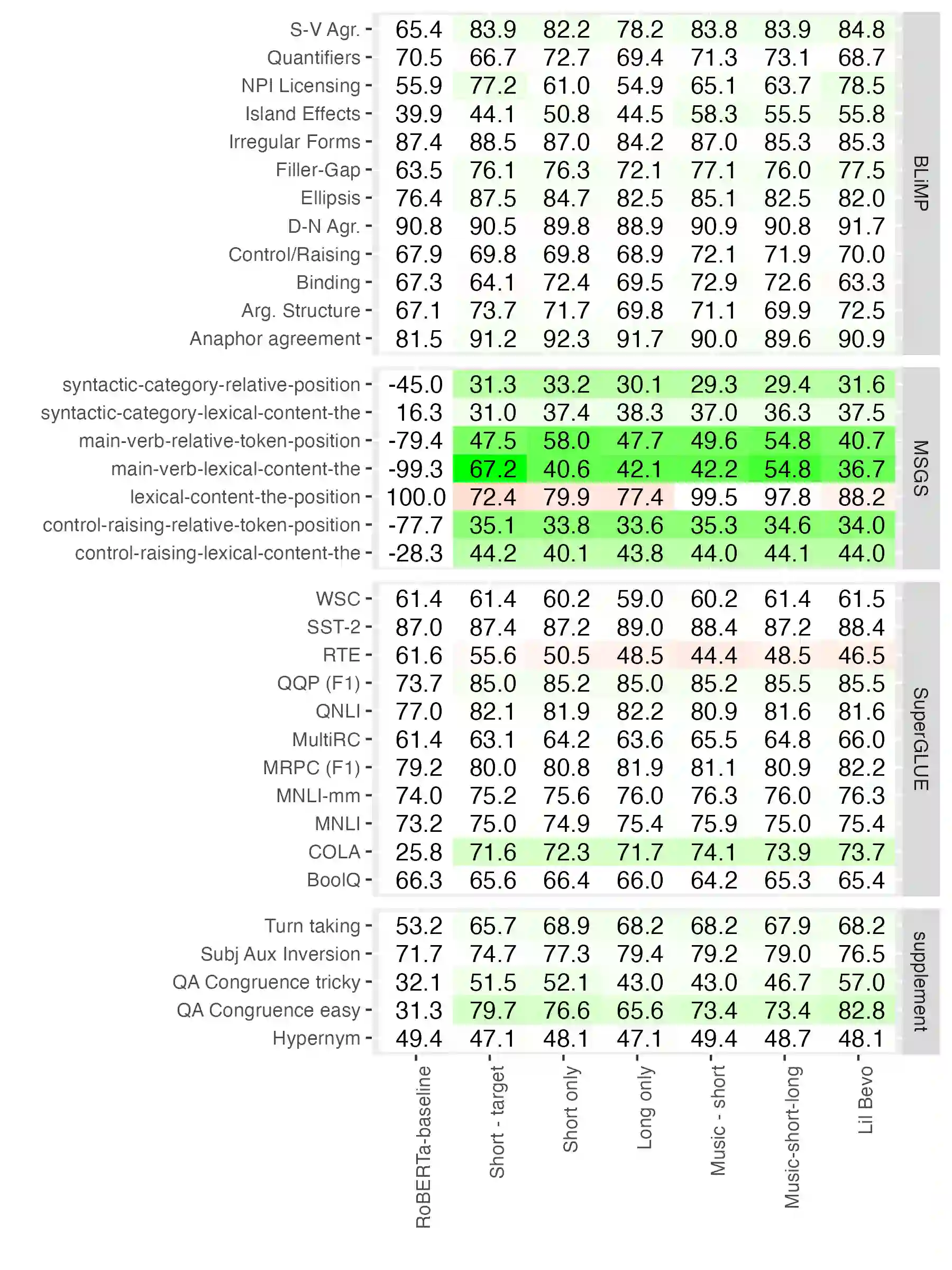
We present Lil-Bevo, our submission to the BabyLM Challenge. We pretrained our masked language models with three ingredients: an initial pretraining with music data, training on shorter sequences before training on longer ones, and masking specific tokens to target some of the BLiMP subtasks. Overall, our baseline models performed above chance, but far below the performance levels of larger LLMs trained on more data. We found that training on short sequences performed better than training on longer sequences.Pretraining on music may help performance marginally, but, if so, the effect seems small. Our targeted Masked Language Modeling augmentation did not seem to improve model performance in general, but did seem to help on some of the specific BLiMP tasks that we were targeting (e.g., Negative Polarity Items). Training performant LLMs on small amounts of data is a difficult but potentially informative task. While some of our techniques showed some promise, more work is needed to explore whether they can improve performance more than the modest gains here. Our code is available at https://github.com/venkatasg/Lil-Bevo and out models at https://huggingface.co/collections/venkatasg/babylm-653591cdb66f4bf68922873a
翻译:我们提出了Lil-Bevo,这是我们参与BabyLM挑战赛的成果。我们采用三种策略对掩码语言模型进行预训练:首先使用音乐数据进行初始预训练,其次在长序列训练前先进行短序列训练,最后针对特定BLiMP子任务掩码特定词元。总体而言,我们的基线模型表现优于随机水平,但远低于基于更多数据训练的大型语言模型的性能水平。我们发现短序列训练的效果优于长序列训练。音乐预训练可能对性能有边际提升,但即便存在这种影响,其效果似乎也很有限。我们定向的掩码语言模型增强方法并未普遍改善模型性能,但在我们针对的特定BLiMP任务(如负极性项目)上似乎有所帮助。基于少量数据训练高性能语言模型是一项艰巨但富有启发意义的任务。尽管部分技术展现了潜力,但仍需进一步研究以探讨其能否实现超越本文所述有限增益的性能提升。我们的代码见https://github.com/venkatasg/Lil-Bevo,模型见https://huggingface.co/collections/venkatasg/babylm-653591cdb66f4bf68922873a