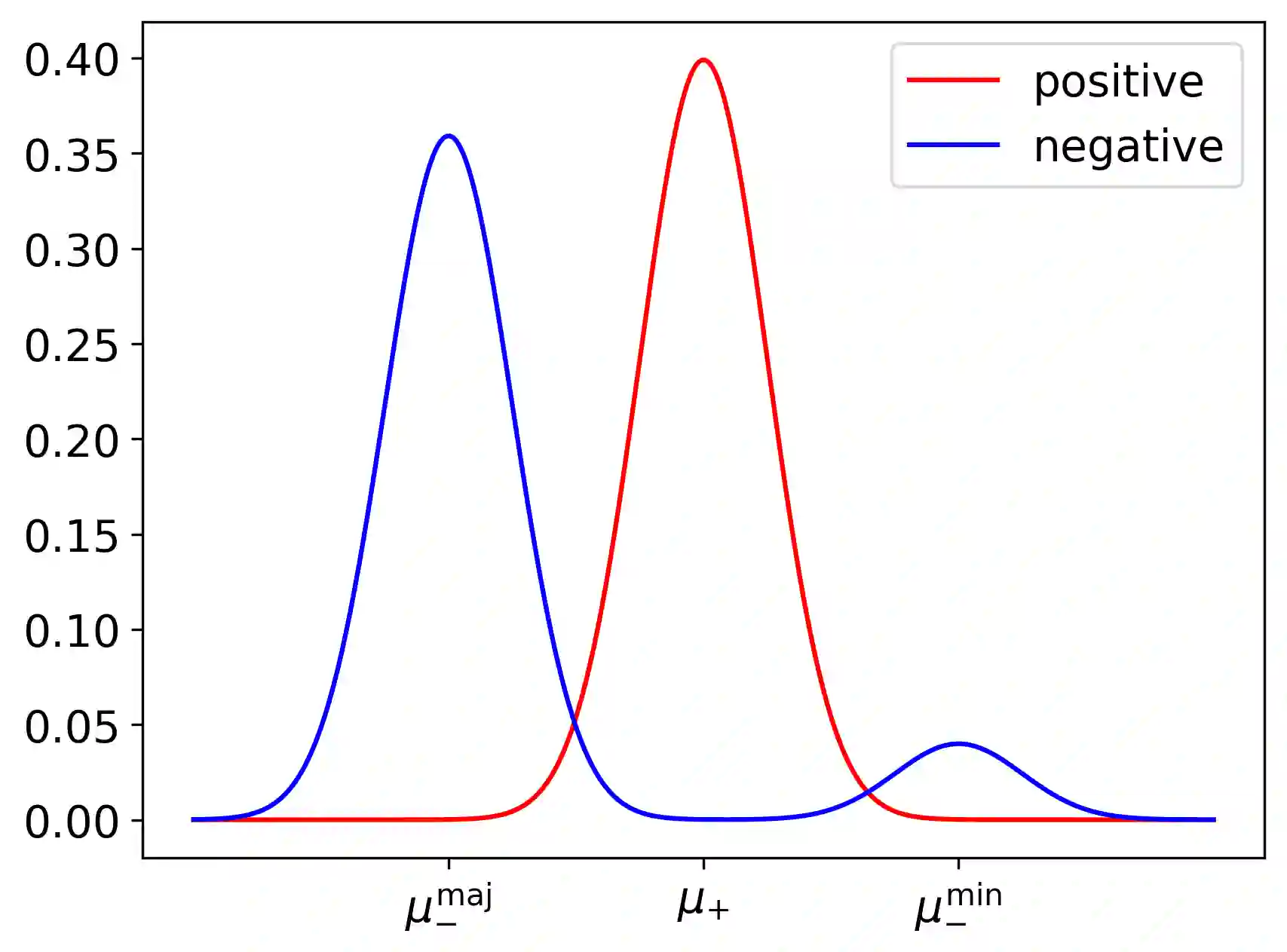
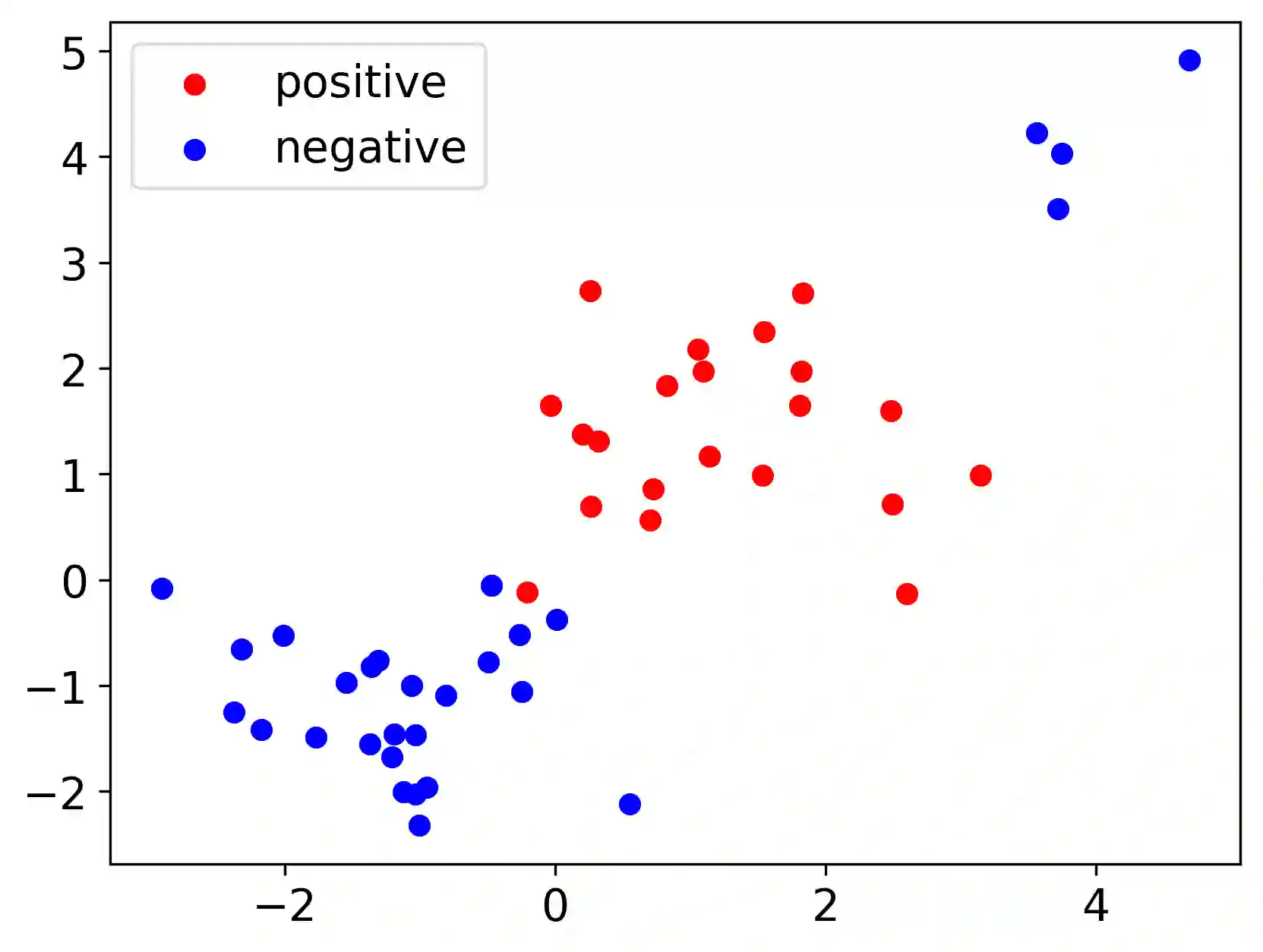
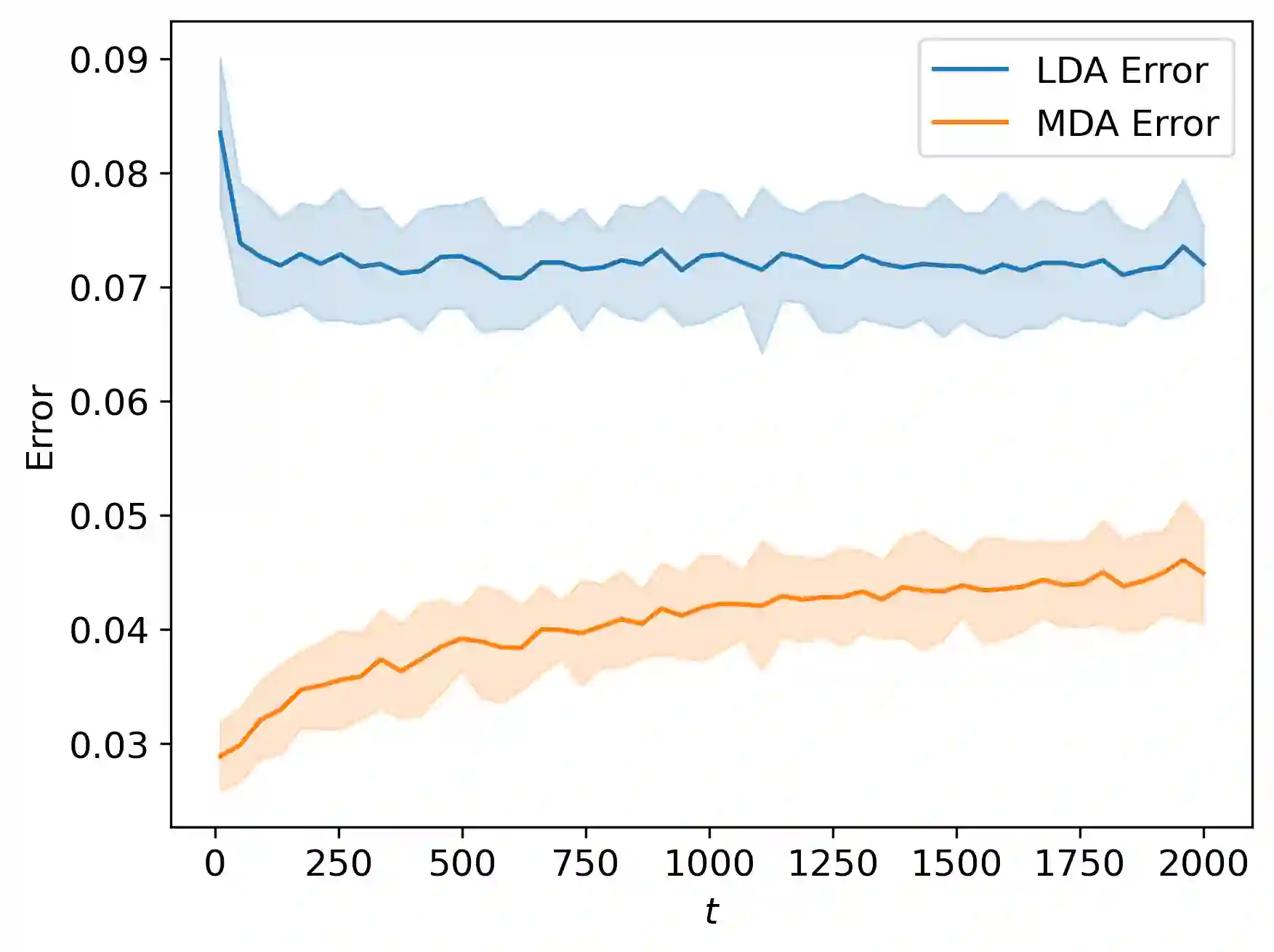
We suggest a simple Gaussian mixture model for data generation that complies with Feldman's long tail theory (2020). We demonstrate that a linear classifier cannot decrease the generalization error below a certain level in the proposed model, whereas a nonlinear classifier with a memorization capacity can. This confirms that for long-tailed distributions, rare training examples must be considered for optimal generalization to new data. Finally, we show that the performance gap between linear and nonlinear models can be lessened as the tail becomes shorter in the subpopulation frequency distribution, as confirmed by experiments on synthetic and real data.
翻译:我们提出了一种符合Feldman长尾理论(2020)的简单高斯混合数据生成模型。研究证明,在该模型中线性分类器无法将泛化误差降低到某一阈值以下,而具有记忆能力的非线性分类器则可实现这一目标。这一结果证实:对于长尾分布,必须考虑稀有训练样本才能实现对新数据的最优泛化。最后,我们通过合成数据与真实数据的实验表明,当子群体频率分布中的尾部变短时,线性与非线性模型之间的性能差距会随之减小。