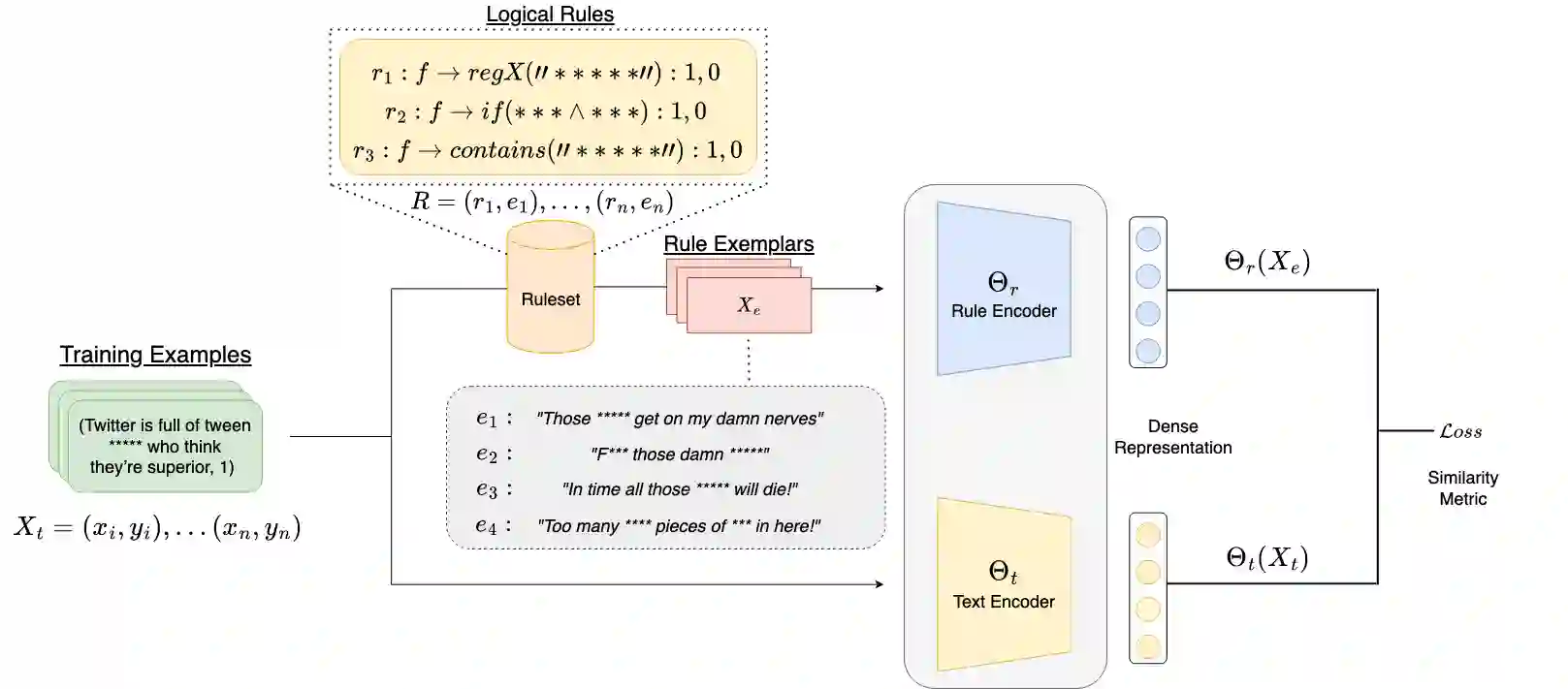
Classic approaches to content moderation typically apply a rule-based heuristic approach to flag content. While rules are easily customizable and intuitive for humans to interpret, they are inherently fragile and lack the flexibility or robustness needed to moderate the vast amount of undesirable content found online today. Recent advances in deep learning have demonstrated the promise of using highly effective deep neural models to overcome these challenges. However, despite the improved performance, these data-driven models lack transparency and explainability, often leading to mistrust from everyday users and a lack of adoption by many platforms. In this paper, we present Rule By Example (RBE): a novel exemplar-based contrastive learning approach for learning from logical rules for the task of textual content moderation. RBE is capable of providing rule-grounded predictions, allowing for more explainable and customizable predictions compared to typical deep learning-based approaches. We demonstrate that our approach is capable of learning rich rule embedding representations using only a few data examples. Experimental results on 3 popular hate speech classification datasets show that RBE is able to outperform state-of-the-art deep learning classifiers as well as the use of rules in both supervised and unsupervised settings while providing explainable model predictions via rule-grounding.
翻译:传统的内容审核方法通常采用基于规则的启发式策略来标记内容。尽管规则易于定制且对人类解释直观,但它们本质脆弱,缺乏应对如今网络上大量不良内容所需的灵活性和鲁棒性。近期深度学习的进展表明,使用高效的深度神经模型有望克服这些挑战。然而,尽管性能有所提升,这些数据驱动模型缺乏透明度和可解释性,常导致日常用户的不信任以及许多平台的不采纳。本文提出"以例示规"(RBE):一种新颖的基于示例的对比学习方法,用于从逻辑规则中学习文本内容审核任务。RBE能够提供基于规则的预测,相比典型的深度学习方法,其预测更具可解释性和可定制性。我们证明,该方法仅使用少量数据示例就能学习丰富的规则嵌入表示。在三个流行的仇恨言论分类数据集上的实验结果表明,在监督和无监督设置下,RBE均能超越最先进的深度学习分类器以及基于规则的方法,同时通过规则归因提供可解释的模型预测。