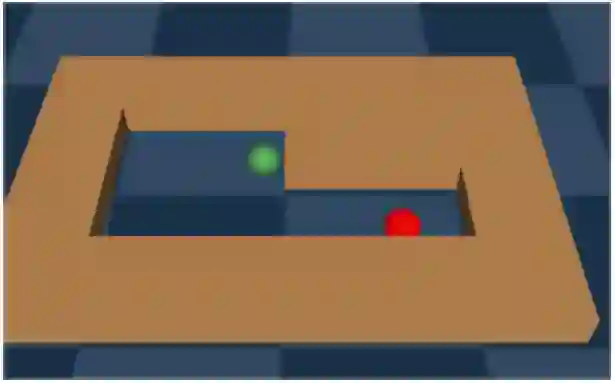
We address the challenge of offline reinforcement learning using realistic data, specifically non-expert data collected through sub-optimal behavior policies. Under such circumstance, the learned policy must be safe enough to manage \textit{distribution shift} while maintaining sufficient flexibility to deal with non-expert (bad) demonstrations from offline data.To tackle this issue, we introduce a novel method called Outcome-Driven Action Flexibility (ODAF), which seeks to reduce reliance on the empirical action distribution of the behavior policy, hence reducing the negative impact of those bad demonstrations.To be specific, a new conservative reward mechanism is developed to deal with {\it distribution shift} by evaluating actions according to whether their outcomes meet safety requirements - remaining within the state support area, rather than solely depending on the actions' likelihood based on offline data.Besides theoretical justification, we provide empirical evidence on widely used MuJoCo and various maze benchmarks, demonstrating that our ODAF method, implemented using uncertainty quantification techniques, effectively tolerates unseen transitions for improved "trajectory stitching," while enhancing the agent's ability to learn from realistic non-expert data.
翻译:我们针对使用现实数据(特别是通过次优行为策略收集的非专家数据)进行离线强化学习的挑战展开研究。在此情况下,习得的策略必须具备足够的安全性以处理\textit{分布偏移},同时保持充分的灵活性以应对离线数据中的非专家(不良)演示。为解决此问题,我们提出了一种名为结果驱动动作灵活性(ODAF)的新方法,旨在减少对行为策略经验动作分布的依赖,从而降低这些不良演示的负面影响。具体而言,我们开发了一种新的保守奖励机制,通过根据动作结果是否满足安全要求(保持在状态支撑区域内)来评估动作,而非仅仅依赖基于离线数据的动作似然性,以此处理{\it 分布偏移}问题。除理论论证外,我们在广泛使用的MuJoCo及多种迷宫基准测试上提供了实证证据,表明采用不确定性量化技术实现的ODAF方法能有效容忍未见过的状态转移以改进"轨迹拼接",同时增强智能体从现实非专家数据中学习的能力。