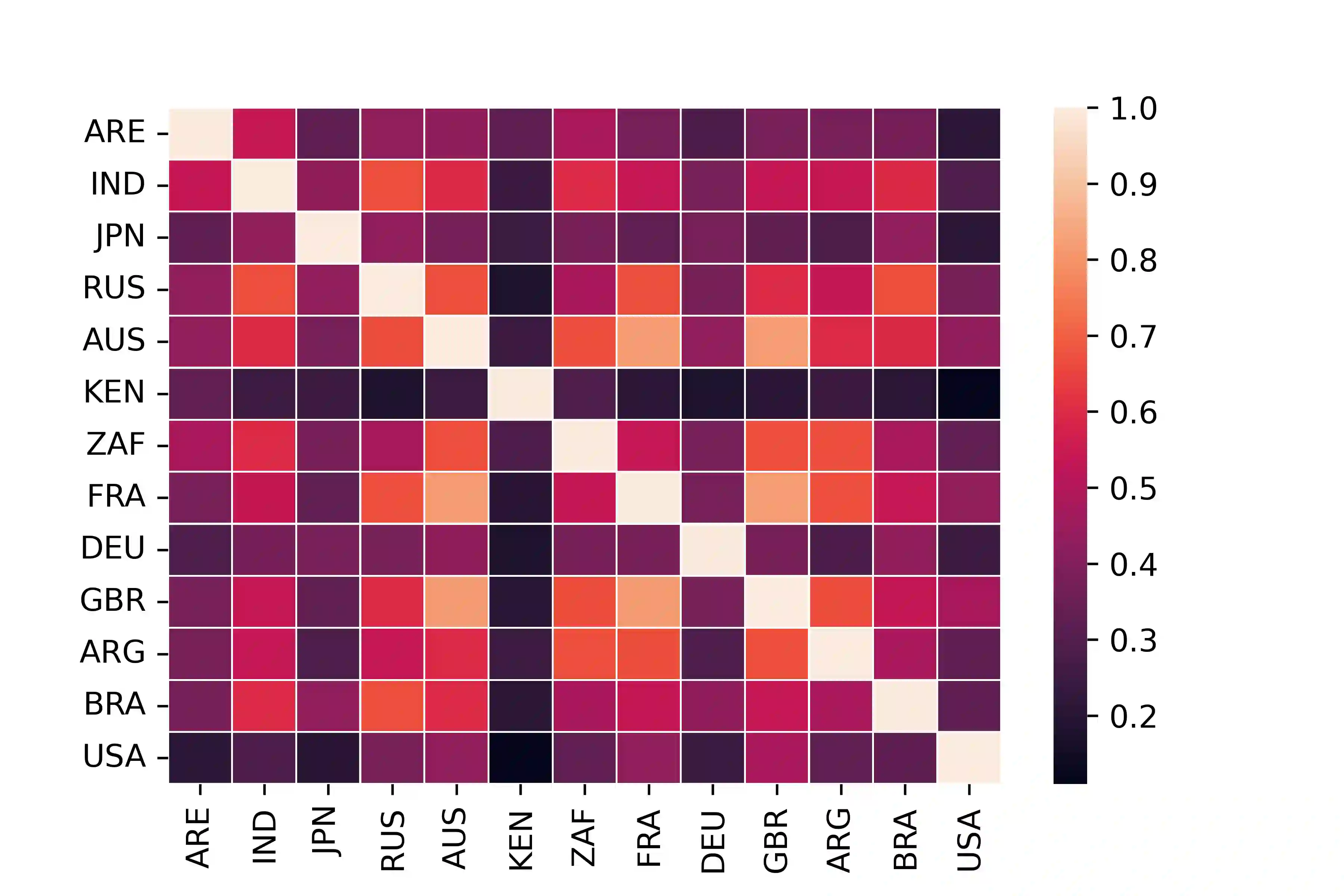
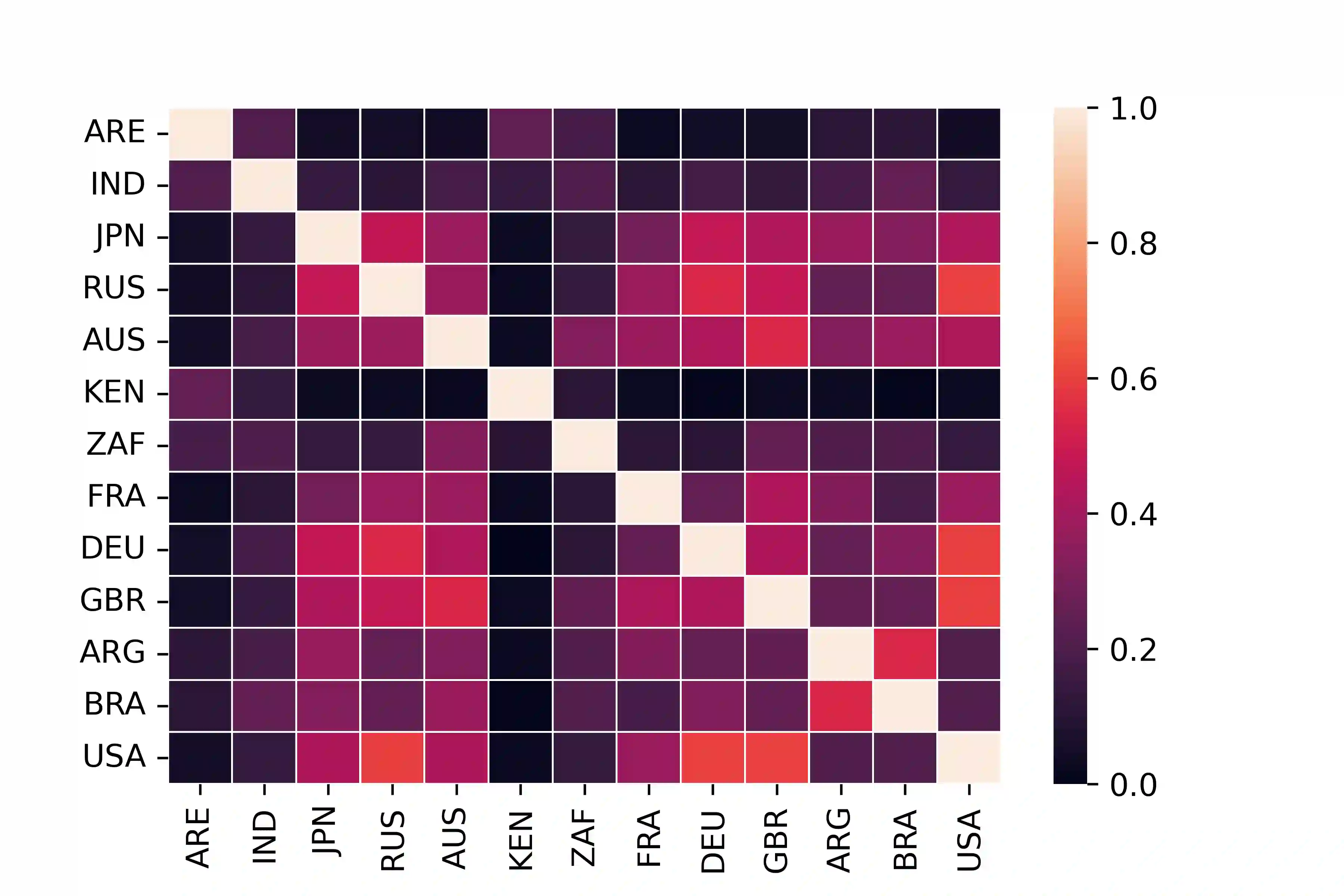
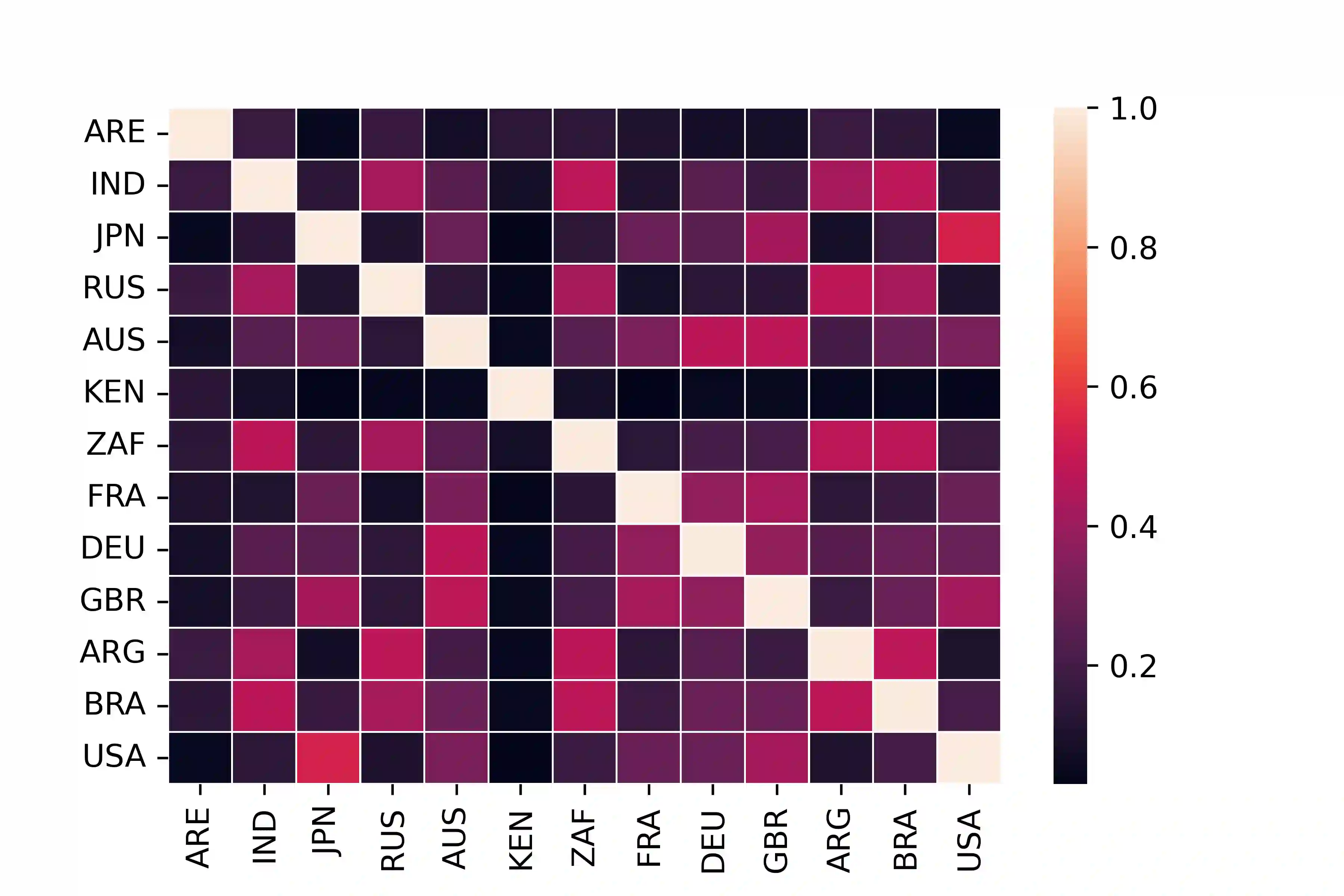
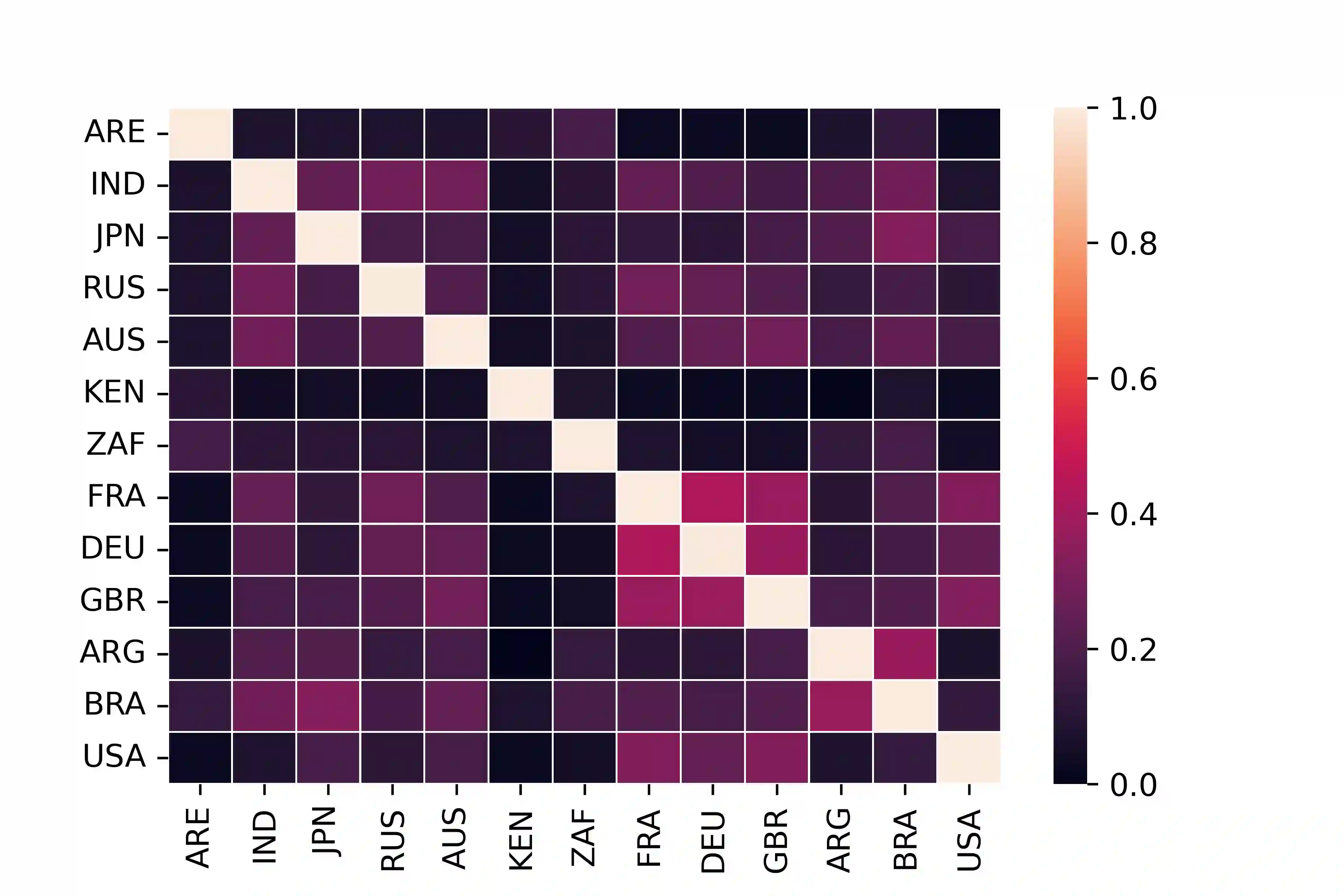
With the widespread use of knowledge graphs (KG) in various automated AI systems and applications, it is very important to ensure that information retrieval algorithms leveraging them are free from societal biases. Previous works have depicted biases that persist in KGs, as well as employed several metrics for measuring the biases. However, such studies lack the systematic exploration of the sensitivity of the bias measurements, through varying sources of data, or the embedding algorithms used. To address this research gap, in this work, we present a holistic analysis of bias measurement on the knowledge graph. First, we attempt to reveal data biases that surface in Wikidata for thirteen different demographics selected from seven continents. Next, we attempt to unfold the variance in the detection of biases by two different knowledge graph embedding algorithms - TransE and ComplEx. We conduct our extensive experiments on a large number of occupations sampled from the thirteen demographics with respect to the sensitive attribute, i.e., gender. Our results show that the inherent data bias that persists in KG can be altered by specific algorithm bias as incorporated by KG embedding learning algorithms. Further, we show that the choice of the state-of-the-art KG embedding algorithm has a strong impact on the ranking of biased occupations irrespective of gender. We observe that the similarity of the biased occupations across demographics is minimal which reflects the socio-cultural differences around the globe. We believe that this full-scale audit of the bias measurement pipeline will raise awareness among the community while deriving insights related to design choices of data and algorithms both and refrain from the popular dogma of ``one-size-fits-all''.
翻译:随着知识图谱在各类自动化AI系统及应用中的广泛使用,确保基于知识图谱的信息检索算法不受社会偏见影响至关重要。已有研究揭示了知识图谱中存在的偏见,并采用了多种度量方法对其进行测量。然而,这些研究缺乏通过改变数据来源或嵌入算法来系统探索偏见测量敏感性的工作。为填补这一研究空白,本文对知识图谱中的偏见测量进行了整体性分析。首先,我们尝试揭示从七大洲选取的13个不同人口统计群体在维基数据中呈现的数据偏见。其次,我们通过两种不同的知识图谱嵌入算法——TransE和ComplEx——来揭示偏见检测结果的差异性。我们针对这13个人口统计群体中的大量职业样本,围绕敏感属性(即性别)开展了大规模实验。结果表明,知识图谱中固有的数据偏见可通过知识图谱嵌入学习算法引入的特定算法偏见而改变。此外,我们发现,无论性别如何,先进知识图谱嵌入算法的选择会对偏见职业的排序产生显著影响。我们还观察到,不同人口统计群体中偏见职业的相似性极低,这反映了全球各地的社会文化差异。我们相信,这项对偏见测量管道的全面审计将提高社区的认知水平,同时引导人们在设计数据和算法相关方案时避免陷入"一刀切"的流行教条。