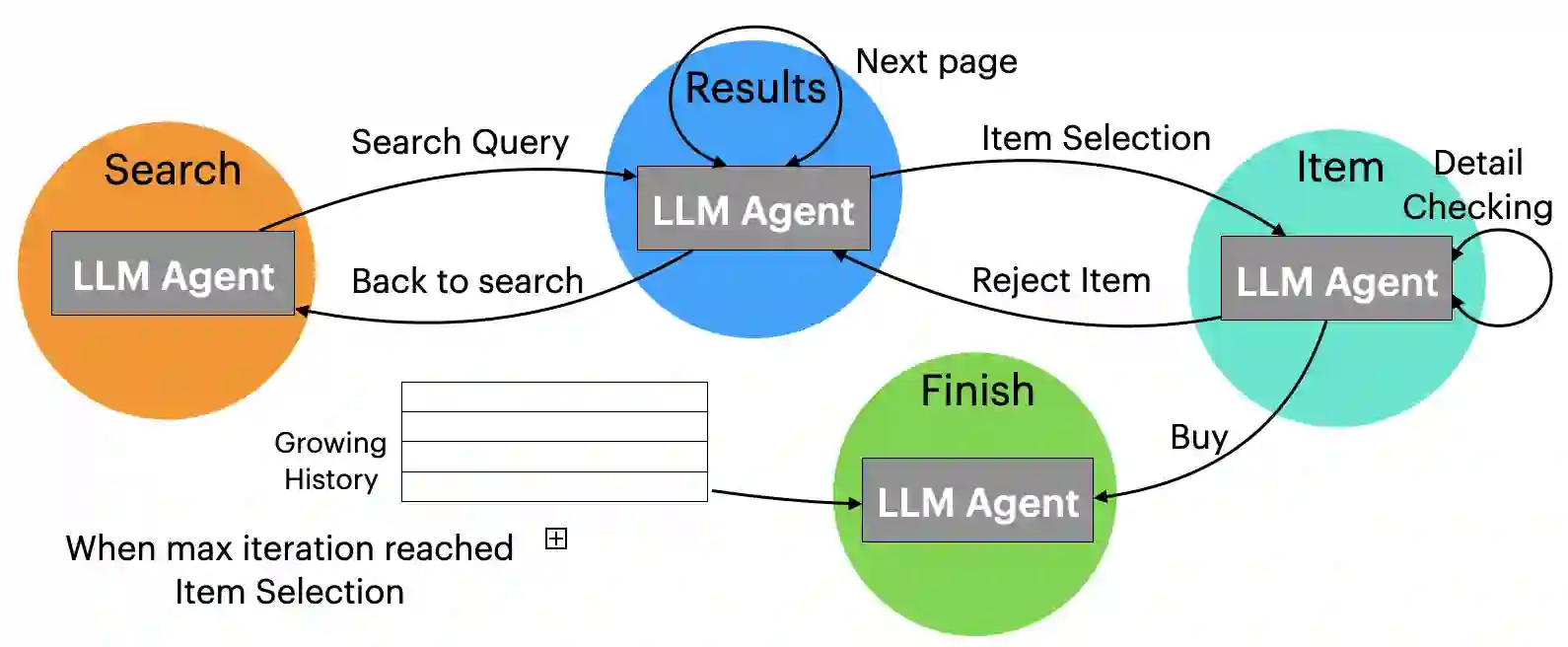
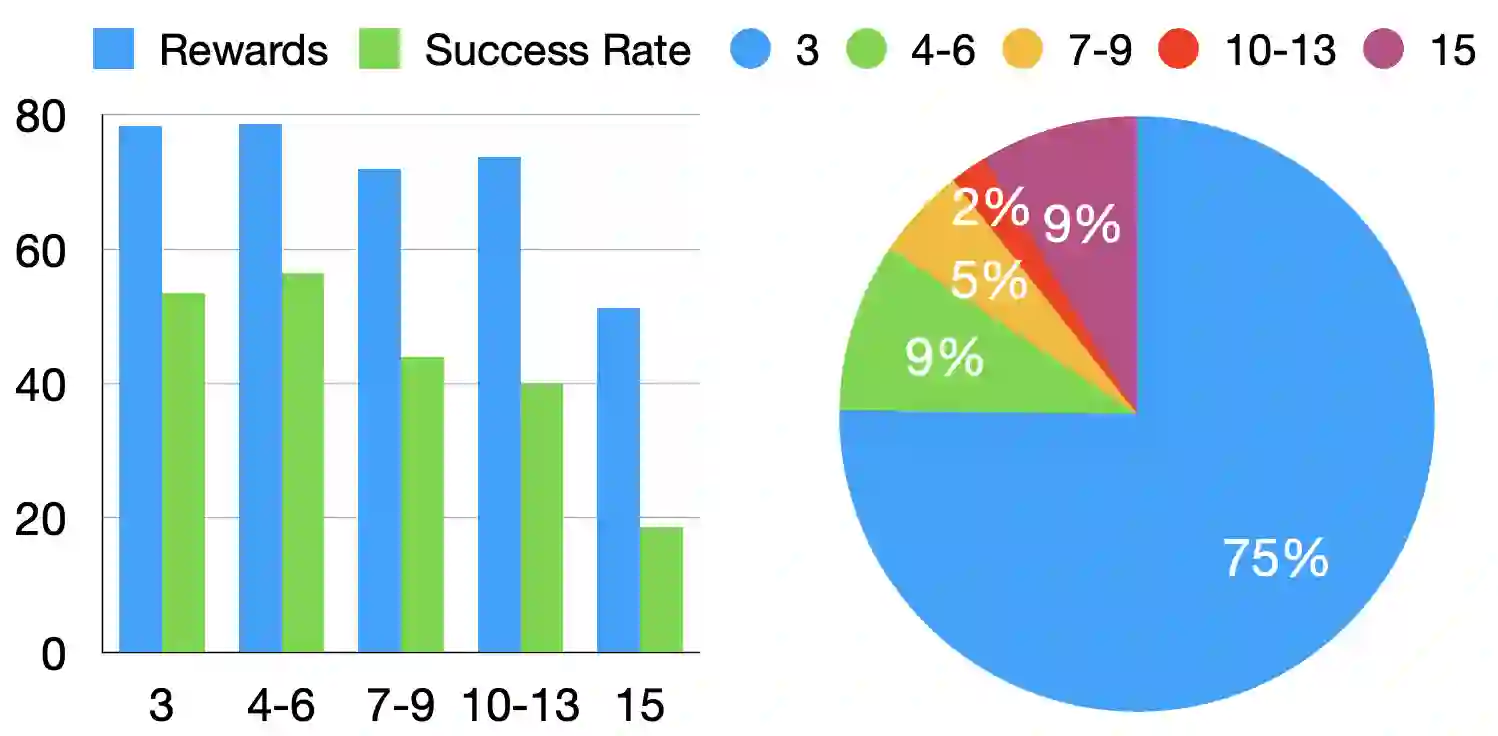
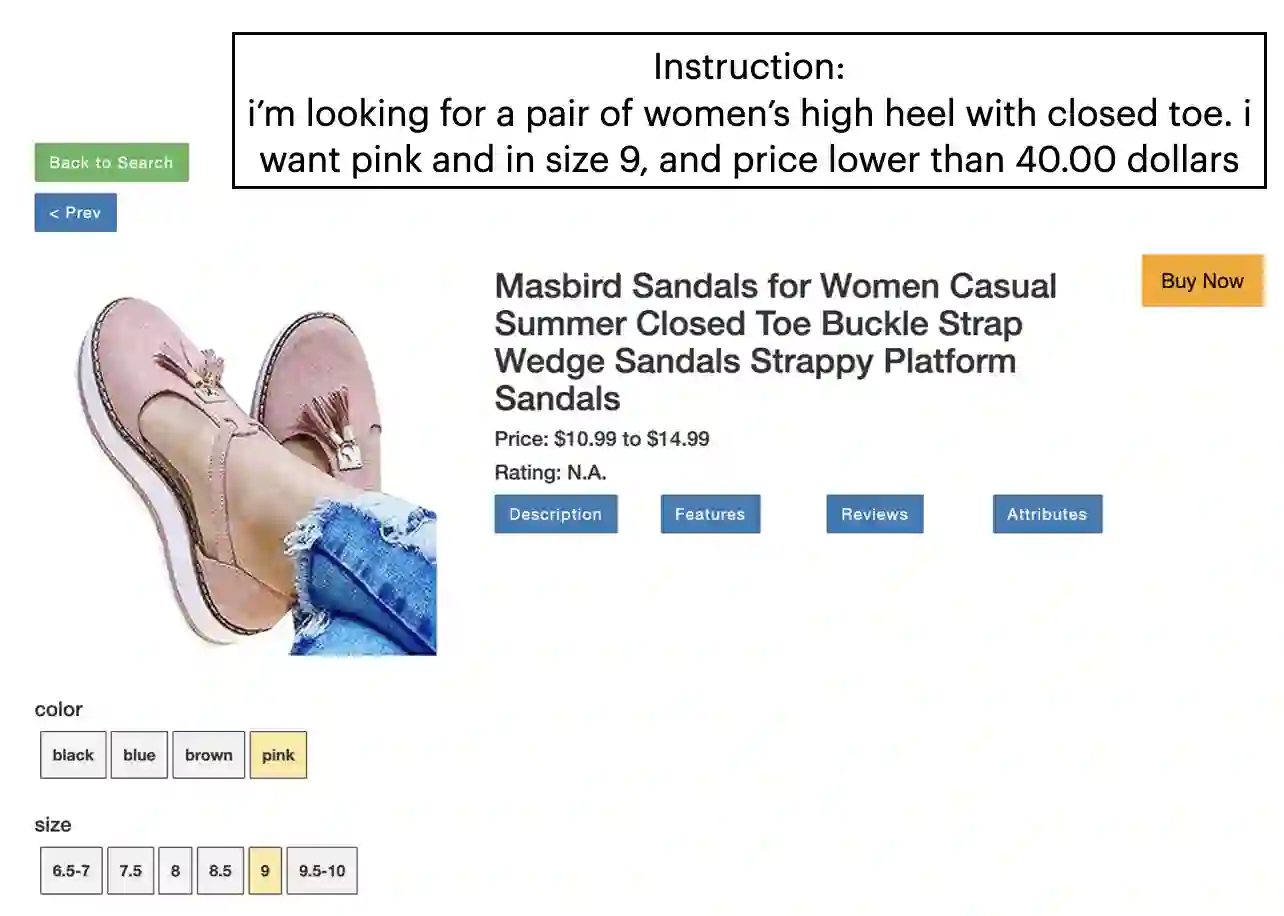
Large language models (LLMs) have been successfully adapted for interactive decision-making tasks like web navigation. While achieving decent performance, previous methods implicitly assume a forward-only execution mode for the model, where they only provide oracle trajectories as in-context examples to guide the model on how to reason in the environment. Consequently, the model could not handle more challenging scenarios not covered in the in-context examples, e.g., mistakes, leading to sub-optimal performance. To address this issue, we propose to model the interactive task as state space exploration, where the LLM agent transitions among a pre-defined set of states by performing actions to complete the task. This formulation enables flexible backtracking, allowing the model to recover from errors easily. We evaluate our proposed LLM Agent with State-Space ExploRation (LASER) on both the WebShop task and amazon.com. Experimental results show that LASER significantly outperforms previous methods and closes the gap with human performance on the web navigation task.
翻译:大型语言模型(LLMs)已成功应用于交互式决策任务,如网页导航。尽管取得了不错的表现,以往方法隐含地假设模型采用仅前向的执行模式,即仅通过提供示例轨迹作为上下文示例,指导模型在环境中进行推理。因此,模型无法处理上下文示例中未涵盖的更复杂场景(例如错误),导致性能次优。为解决这一问题,我们提出将交互式任务建模为状态空间探索:LLM智能体通过执行动作在预定义状态集中转移,以完成任务。该公式支持灵活的回溯机制,使模型能够轻松从错误中恢复。我们在WebShop任务和amazon.com上评估了所提出的带有状态空间探索的LLM智能体(LASER)。实验结果表明,LASER显著优于以往方法,并在网页导航任务中缩小了与人类表现的差距。