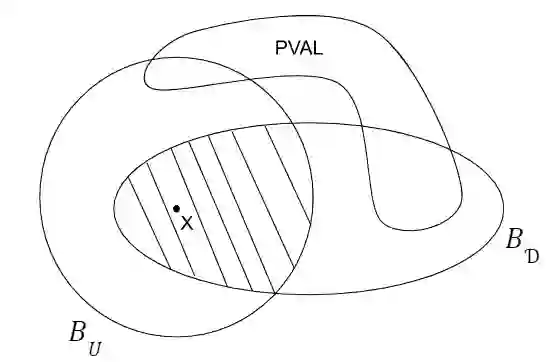
Motivated by the fact that input distributions are often unknown in advance, distribution-free property testing considers a setting where the algorithmic task is to accept functions $f : [n] \to \{0,1\}$ with a certain property P and reject functions that are $\eta$-far from P, where the distance is measured according to an arbitrary and unknown input distribution $D \sim [n]$. As usual in property testing, the tester can only make a sublinear number of input queries, but as the distribution is unknown, we also allow a sublinear number of samples from the distribution D. In this work we initiate the study of distribution-free interactive proofs of proximity (df-IPPs) in which the distribution-free testing algorithm is assisted by an all powerful but untrusted prover. Our main result is that for any problem P $\in$ NC, any proximity parameter $\eta > 0$, and any (trade-off) parameter $t\leq\sqrt{n}$, we construct a df-IPP for P with respect to $\eta$, that has query and sample complexities $t+O(1/\eta)$, and communication complexity $\tilde{O}(n/t + 1/\eta)$. For t as above and sufficiently large $\eta$ (namely, when $\eta > t/n$), this result matches the parameters of the best-known general purpose IPPs in the standard uniform setting. Moreover, for such t, its parameters are optimal up to poly-logarithmic factors under reasonable cryptographic assumptions for the same regime of $\eta$ as the uniform setting, i.e., when $\eta \geq 1/t$. For small $\eta$ (i.e., $\eta< t/n$), our protocol has communication complexity $\Omega(1/\eta)$, which is worse than the $\tilde{O}(n/t)$ communication complexity of the uniform IPPs (with the same query complexity). To improve on this gap, we show that for IPPs over specialised, but large distribution families, such as sufficiently smooth distributions and product distributions, the communication complexity reduces to $\tilde{O}(n/t^{1-o(1)})$.
翻译:受限于输入分布通常事先未知这一事实,无分布性质检验考虑如下设定:算法任务需接受具有特定性质P的函数$f : [n] \to \{0,1\}$,并拒绝与P相距$\eta$的函数,其中距离根据任意且未知的输入分布$D \sim [n]$度量。与标准性质检验相同,检验器仅能进行次线性次输入查询,但由于分布未知,我们还允许从分布D中抽取次线性数量的样本。本文首次研究无分布交互式邻近证明(df-IPP),其中无分布检验算法由全能但不可信的证明者辅助。主要结果表明:对任意属于NC的问题P、任意邻近参数$\eta > 0$以及任意(权衡)参数$t\leq\sqrt{n}$,我们均可针对P构造关于参数$\eta$的df-IPP,其查询复杂度和样本复杂度均为$t+O(1/\eta)$,通信复杂度为$\tilde{O}(n/t + 1/\eta)$。对于上述t及足够大的$\eta$(即$\eta > t/n$时),该结果匹配标准均匀设定下最优通用IPP的参数。此外,在此类t下,其参数在合理密码学假设下对于与均匀设定相同的$\eta$区间(即$\eta \geq 1/t$)达到最优(至多相差多对数因子)。对于较小的$\eta$(即$\eta< t/n$),我们的协议通信复杂度为$\Omega(1/\eta)$,劣于均匀IPP的$\tilde{O}(n/t)$通信复杂度(查询复杂度相同)。为弥补这一差距,我们证明:当IPP针对特定但广泛分布族(如充分光滑分布和乘积分布)时,通信复杂度可降至$\tilde{O}(n/t^{1-o(1)})$。