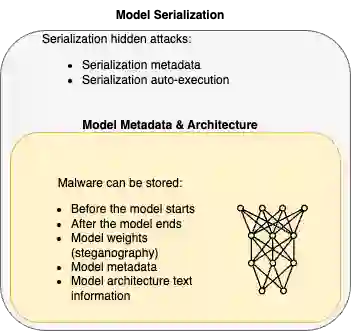
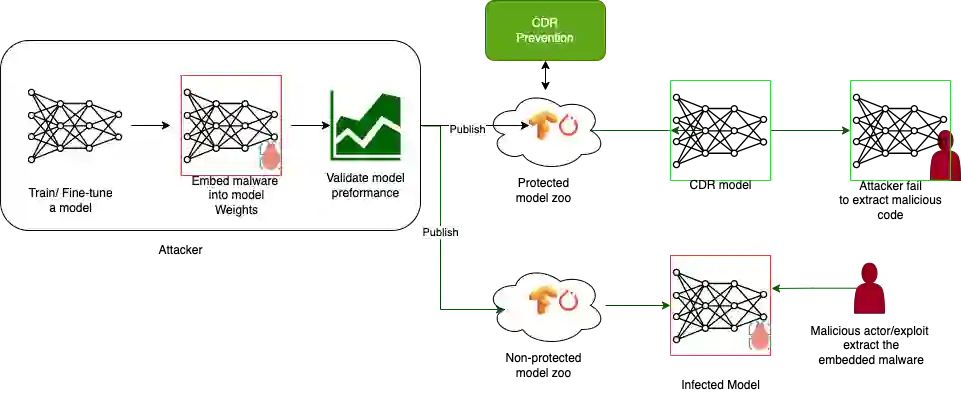
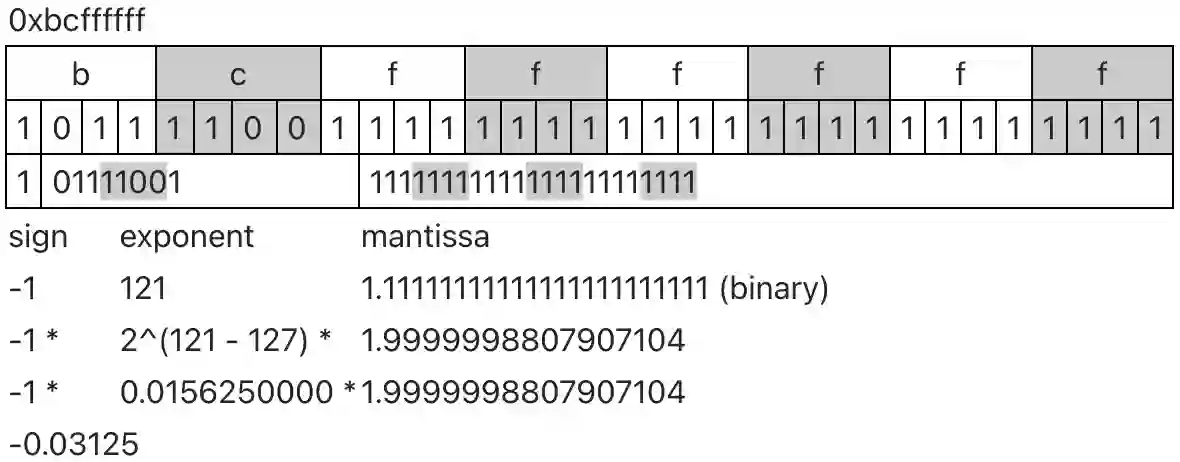
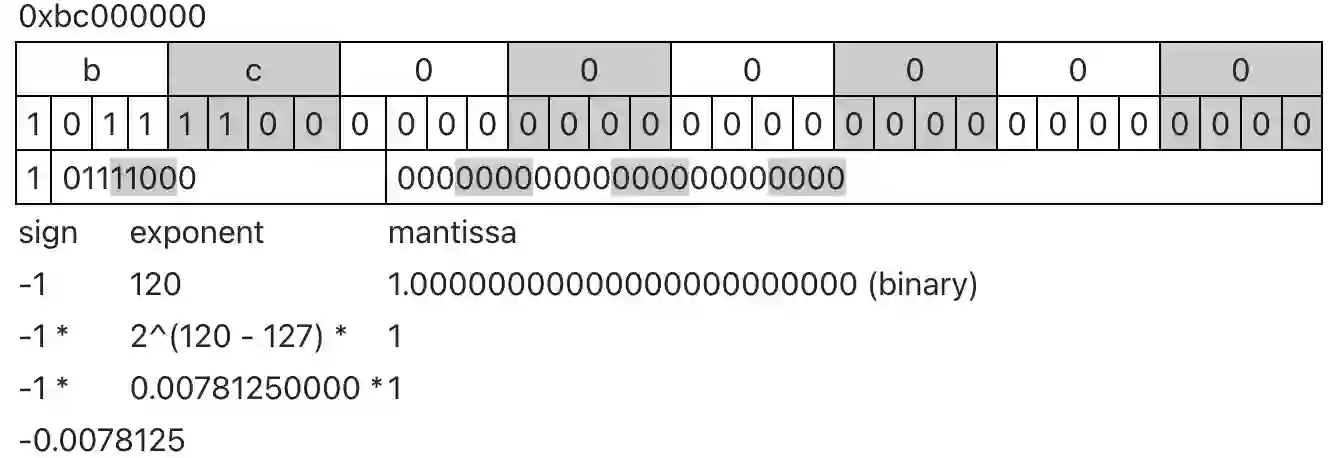
Similar to the revolution of open source code sharing, Artificial Intelligence (AI) model sharing is gaining increased popularity. However, the fast adaptation in the industry, lack of awareness, and ability to exploit the models make them significant attack vectors. By embedding malware in neurons, the malware can be delivered covertly, with minor or no impact on the neural network's performance. The covert attack will use the Least Significant Bits (LSB) weight attack since LSB has a minimal effect on the model accuracy, and as a result, the user will not notice it. Since there are endless ways to hide the attacks, we focus on a zero-trust prevention strategy based on AI model attack disarm and reconstruction. We proposed three types of model steganography weight disarm defense mechanisms. The first two are based on random bit substitution noise, and the other on model weight quantization. We demonstrate a 100\% prevention rate while the methods introduce a minimal decrease in model accuracy based on Qint8 and K-LRBP methods, which is an essential factor for improving AI security.
翻译:与开源代码共享的革命类似,人工智能模型共享正日益普及。然而,行业中的快速适应、安全意识缺失以及利用模型的能力,使得这些模型成为重要的攻击向量。通过将恶意软件嵌入神经元,攻击者可以隐蔽地传递恶意软件,且对神经网络的性能几乎不产生影响。由于最低有效位对模型准确性的影响微乎其微,隐蔽攻击将采用最低有效位权重攻击,因此用户难以察觉。鉴于隐藏攻击的方式无穷无尽,我们聚焦于基于人工智能模型攻击解除与重构的零信任防御策略。我们提出了三种类型的模型隐写权重解除防御机制:前两种基于随机比特替换噪声,另一种基于模型权重量化。我们证明了基于Qint8和K-LRBP方法的防御机制可实现100%的防御率,同时模型精度仅出现极小下降,这对于提升人工智能安全性至关重要。