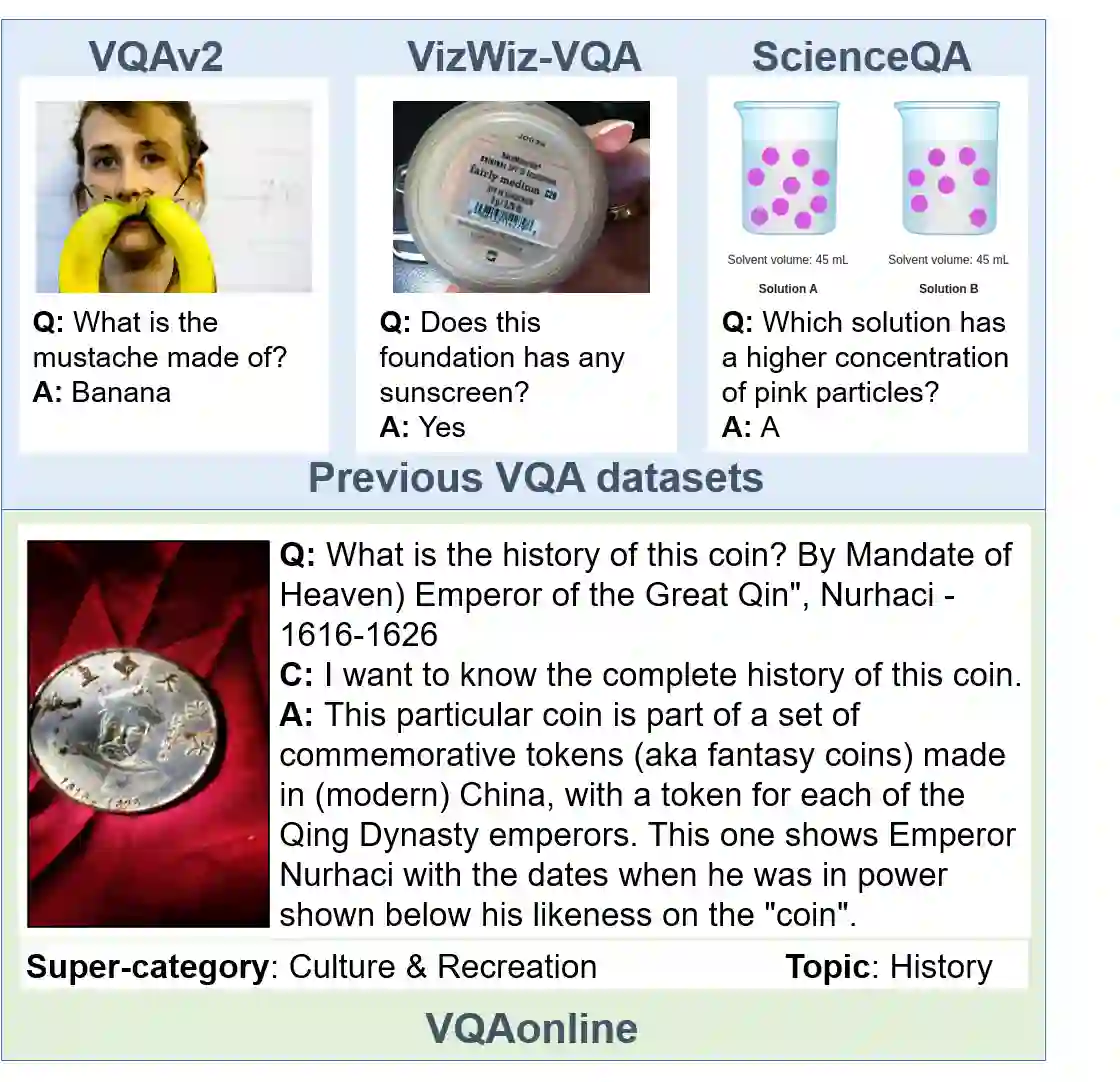
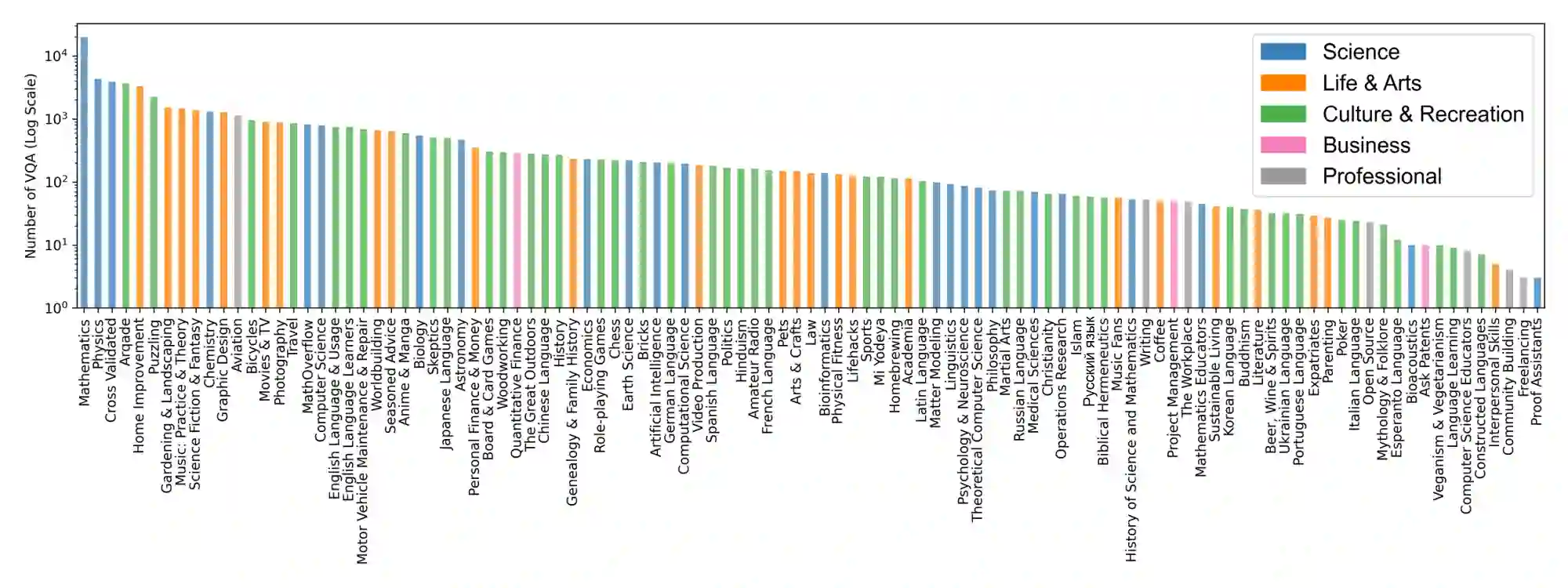
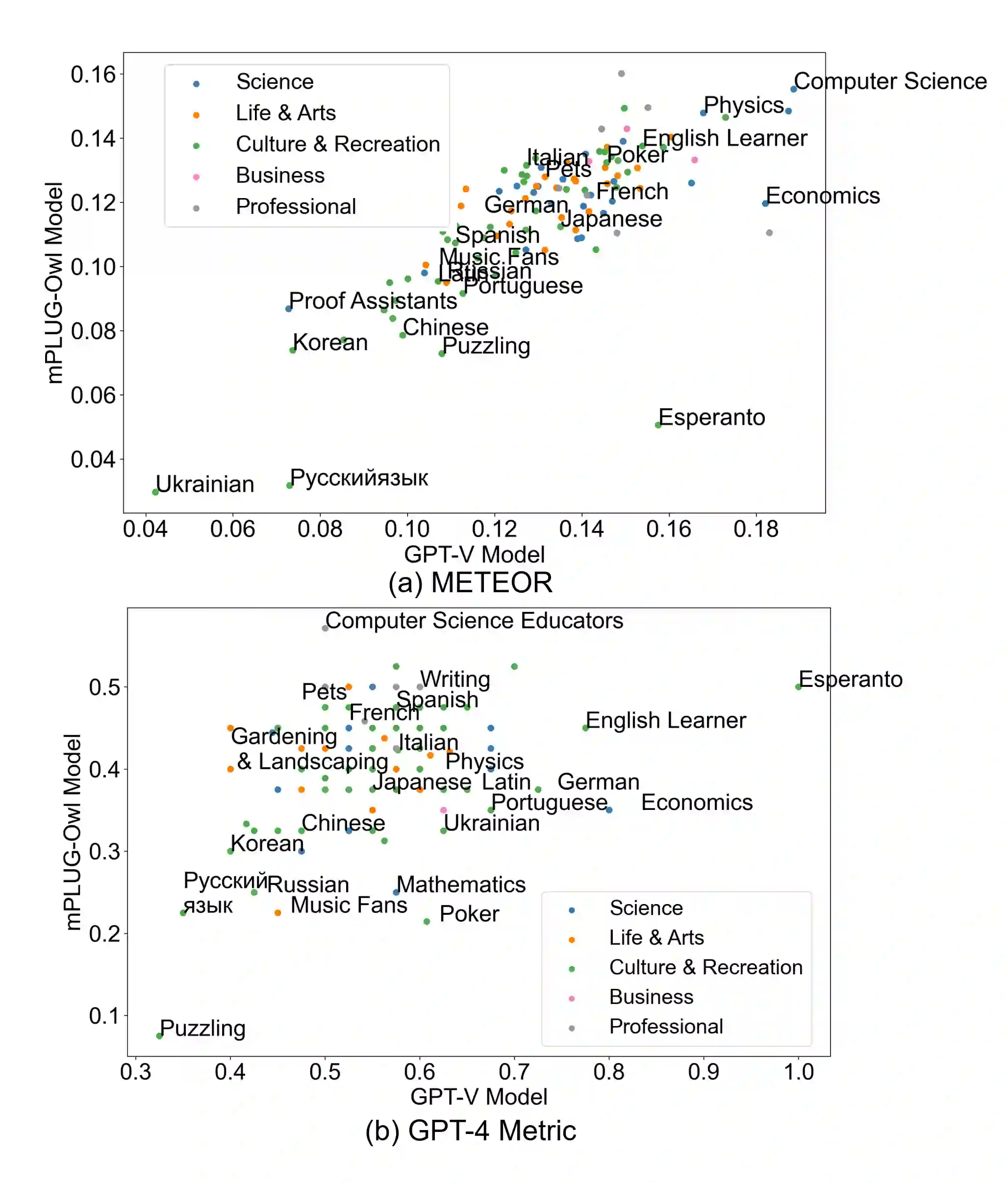
Visual Question Answering (VQA) entails answering questions about images. We introduce the first VQA dataset in which all contents originate from an authentic use case. Sourced from online question answering community forums, we call it VQAonline. We then characterize our dataset and how it relates to eight other VQA datasets. Observing that answers in our dataset tend to be much longer (e.g., with a mean of 173 words) and thus incompatible with standard VQA evaluation metrics, we next analyze which of the six popular metrics for longer text evaluation align best with human judgments. We then use the best-suited metrics to evaluate six state-of-the-art vision and language foundation models on VQAonline and reveal where they struggle most. The dataset can be found publicly at https://vqaonline.github.io/.
翻译:视觉问答(VQA)涉及对图像进行提问并给出答案。我们推出了首个所有内容均源自真实用例的VQA数据集。该数据集来自在线问答社区论坛,我们称之为VQAonline。随后,我们对该数据集进行了特征描述,并将其与其他八种VQA数据集进行了对比。注意到我们数据集中的答案往往更长(例如,平均长度为173个词),因此与标准VQA评估指标不兼容,我们随后分析了六种用于较长文本评估的流行指标中哪些与人类判断最为吻合。接着,我们利用最适配的指标在VQAonline上评估了六种最先进的视觉与语言基础模型,并揭示了它们最薄弱的环节。该数据集可在https://vqaonline.github.io/上公开获取。