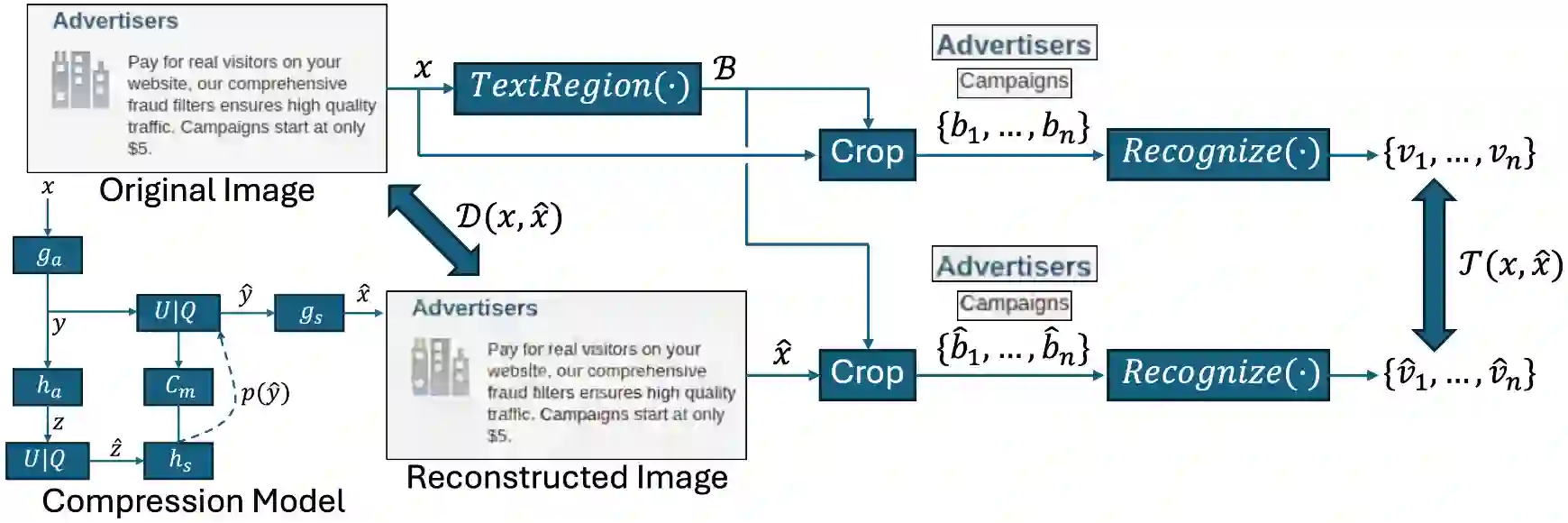
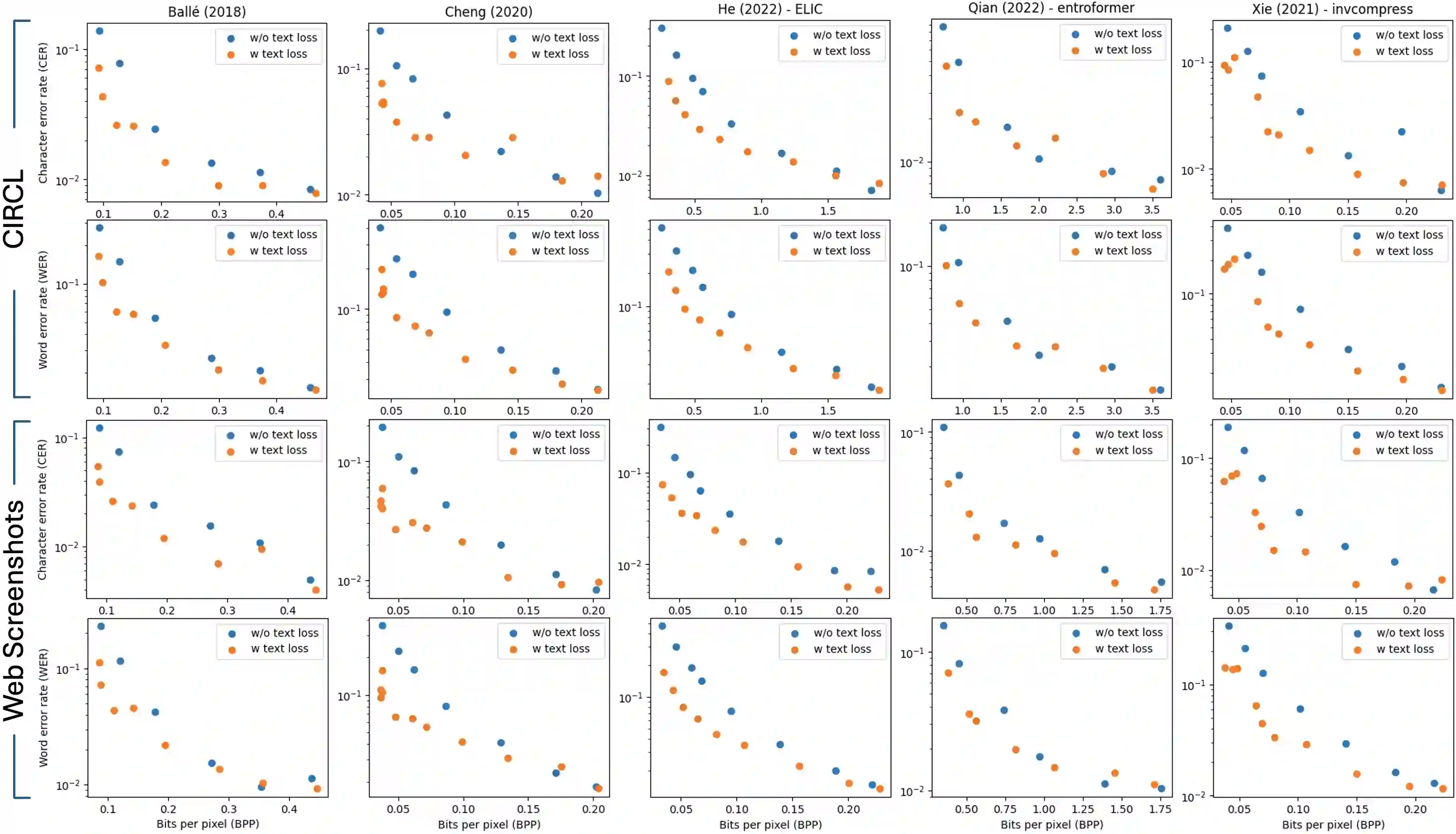
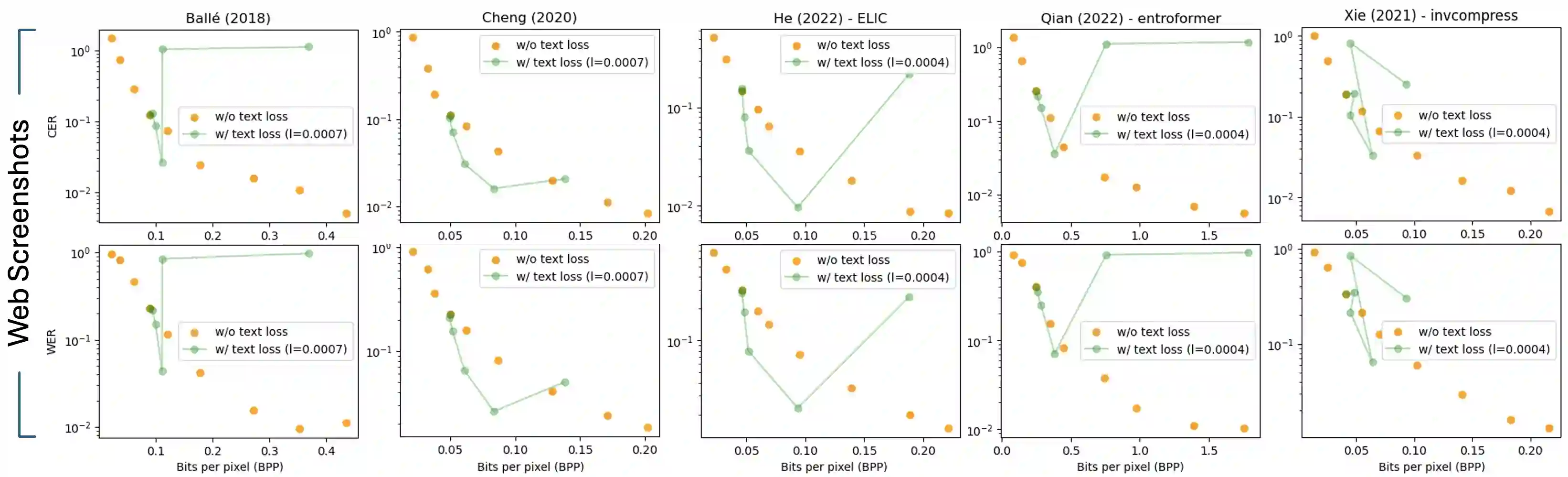
Learned image compression has gained widespread popularity for their efficiency in achieving ultra-low bit-rates. Yet, images containing substantial textual content, particularly screen-content images (SCI), often suffers from text distortion at such compressed levels. To address this, we propose to minimize a novel text logit loss designed to quantify the disparity in text between the original and reconstructed images, thereby improving the perceptual quality of the reconstructed text. Through rigorous experimentation across diverse datasets and employing state-of-the-art algorithms, our findings reveal significant enhancements in the quality of reconstructed text upon integration of the proposed loss function with appropriate weighting. Notably, we achieve a Bjontegaard delta (BD) rate of -32.64% for Character Error Rate (CER) and -28.03% for Word Error Rate (WER) on average by applying the text logit loss for two screenshot datasets. Additionally, we present quantitative metrics tailored for evaluating text quality in image compression tasks. Our findings underscore the efficacy and potential applicability of our proposed text logit loss function across various text-aware image compression contexts.
翻译:学习型图像压缩因其在实现超低比特率方面的高效性而广受欢迎。然而,包含大量文本内容的图像,尤其是屏幕内容图像(SCI),在此类压缩水平下常出现文本失真。为解决这一问题,我们提出最小化一种新颖的文本逻辑损失函数,该函数旨在量化原始图像与重建图像之间的文本差异,从而提升重建文本的感知质量。通过在多种数据集上进行严谨的实验,并采用先进的算法,我们的研究结果表明,在引入所提出的损失函数并赋予适当权重后,重建文本的质量显著提高。值得注意的是,通过将文本逻辑损失应用于两个屏幕截图数据集,我们平均实现了字符错误率(CER)的Bjontegaard delta(BD)率为-32.64%,词错误率(WER)为-28.03%。此外,我们提出了针对图像压缩任务中文本质量评估的定量指标。我们的发现强调了所提出的文本逻辑损失函数在各种文本感知型图像压缩场景中的有效性和潜在适用性。