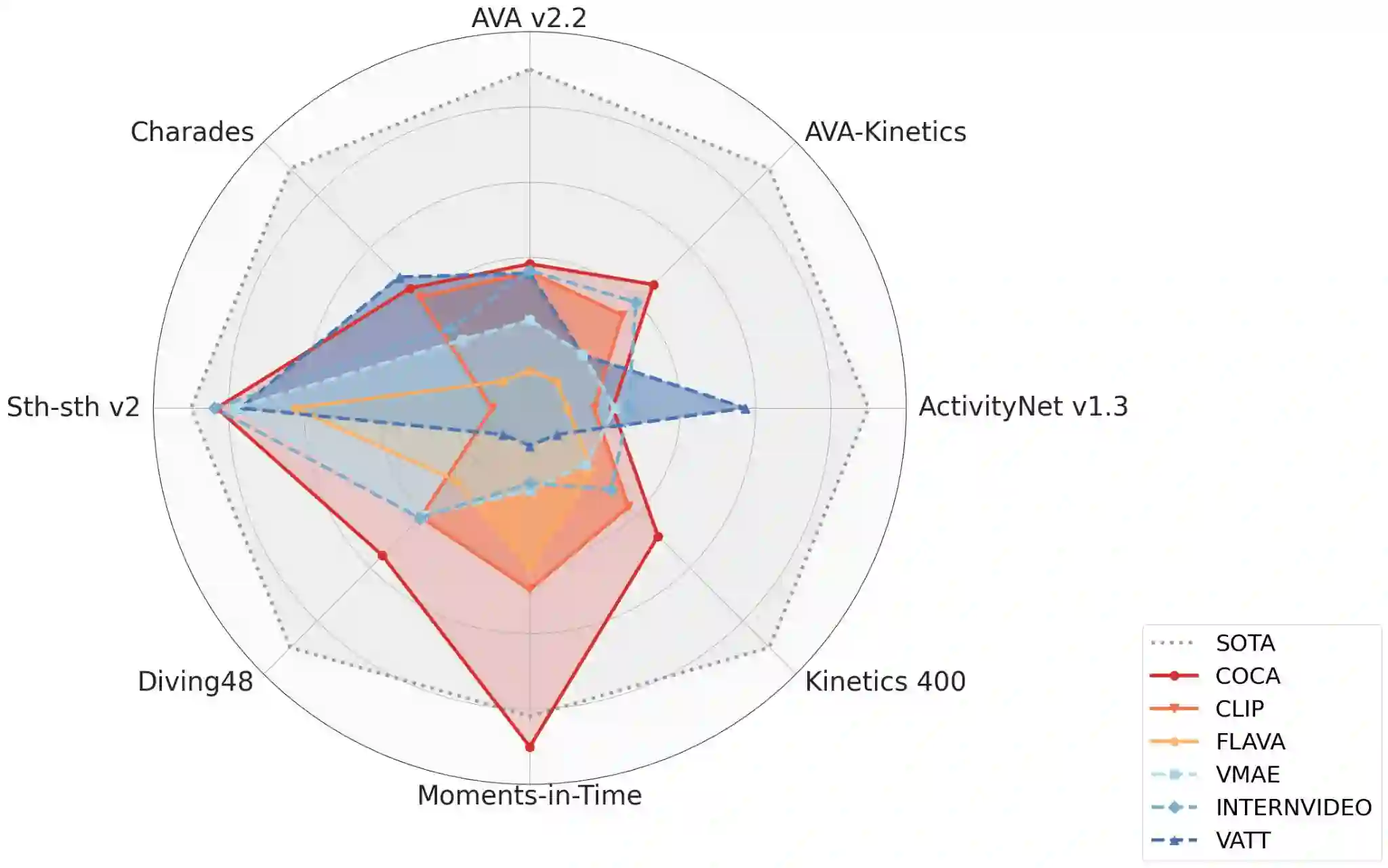
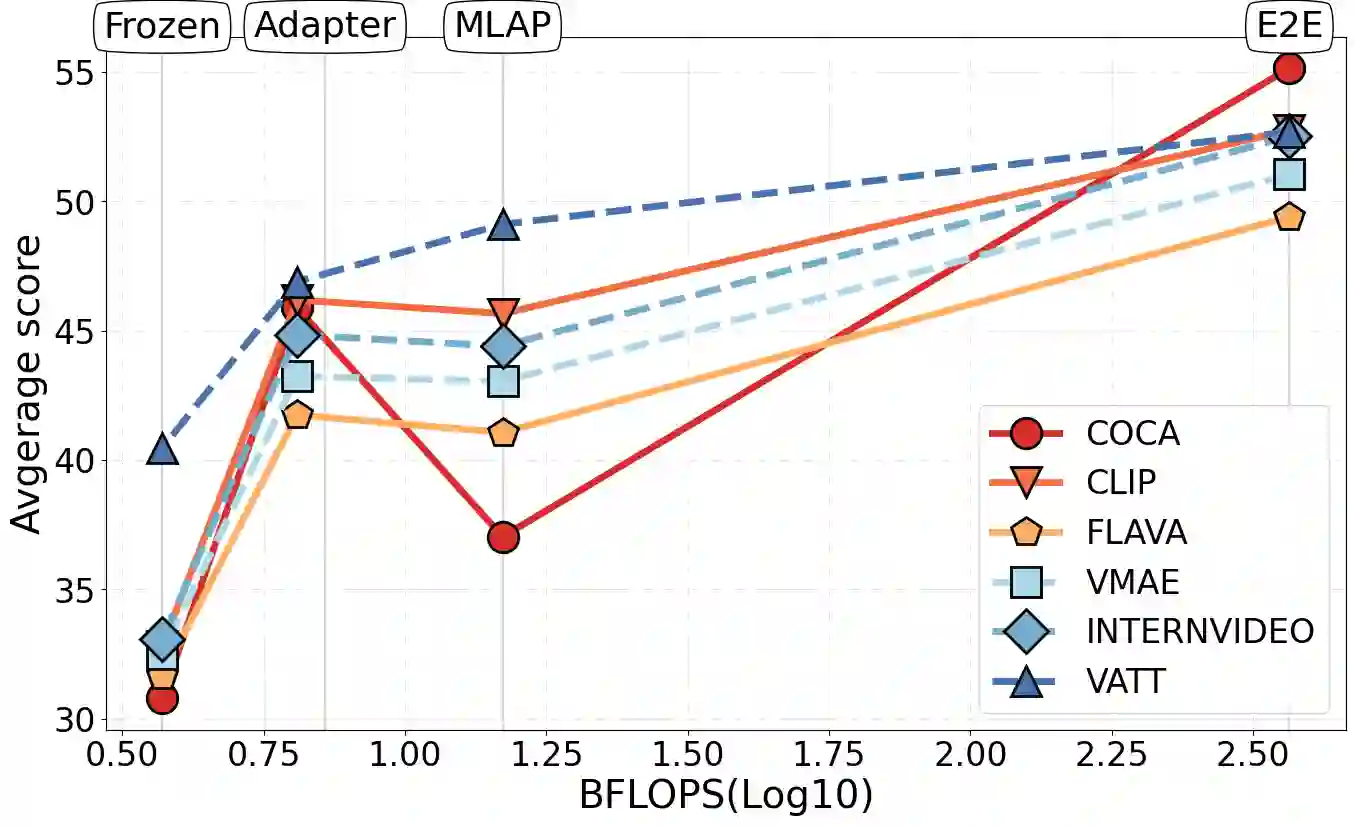
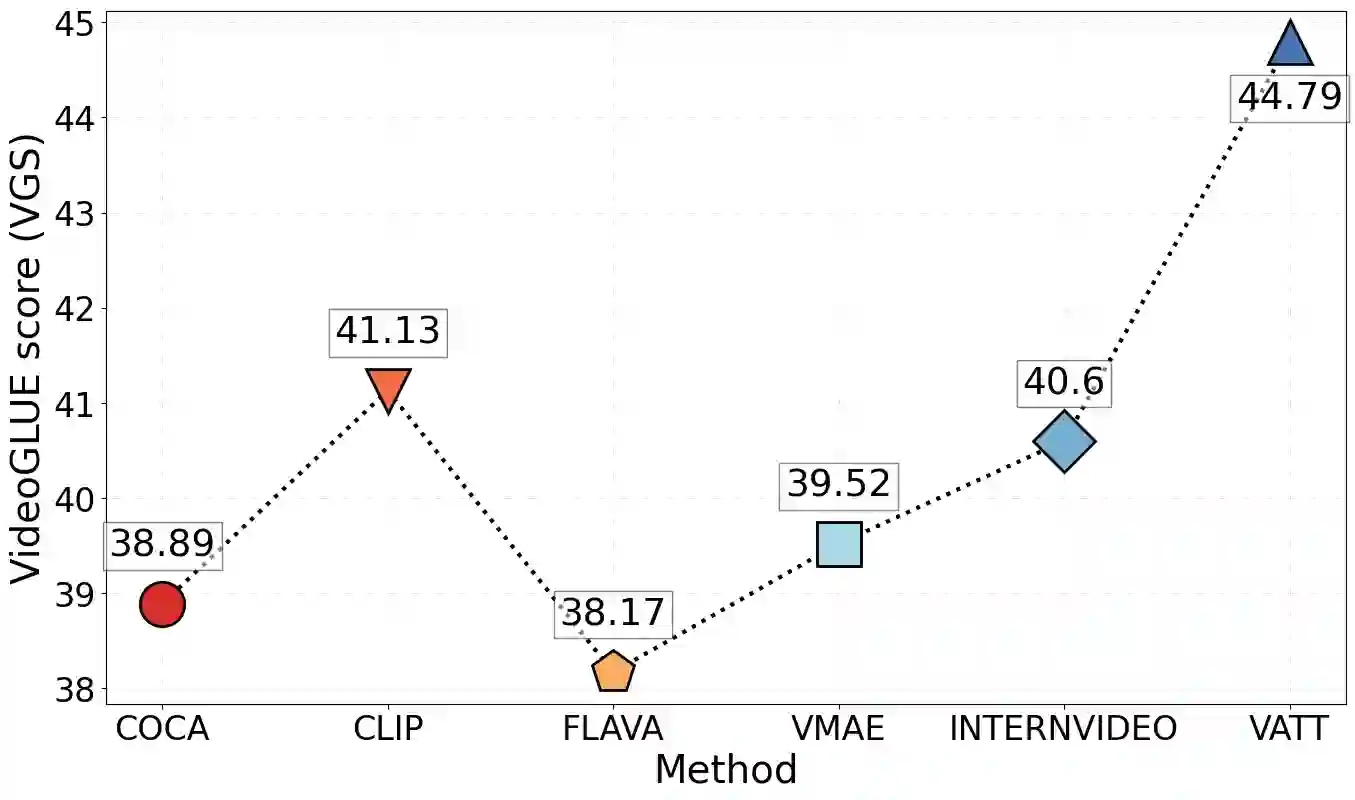
We evaluate existing foundation models video understanding capabilities using a carefully designed experiment protocol consisting of three hallmark tasks (action recognition, temporal localization, and spatiotemporal localization), eight datasets well received by the community, and four adaptation methods tailoring a foundation model (FM) for a downstream task. Moreover, we propose a scalar VideoGLUE score (VGS) to measure an FMs efficacy and efficiency when adapting to general video understanding tasks. Our main findings are as follows. First, task-specialized models significantly outperform the six FMs studied in this work, in sharp contrast to what FMs have achieved in natural language and image understanding. Second,video-native FMs, whose pretraining data contains the video modality, are generally better than image-native FMs in classifying motion-rich videos, localizing actions in time, and understanding a video of more than one action. Third, the video-native FMs can perform well on video tasks under light adaptations to downstream tasks(e.g., freezing the FM backbones), while image-native FMs win in full end-to-end finetuning. The first two observations reveal the need and tremendous opportunities to conduct research on video-focused FMs, and the last confirms that both tasks and adaptation methods matter when it comes to the evaluation of FMs.
翻译:我们通过精心设计的实验方案评估了现有基础模型的视频理解能力,该方案包含三个标志性任务(动作识别、时间定位和时空定位)、八个社区广泛认可的数据集,以及四种将基础模型(FM)适配至下游任务的方法。此外,我们提出标量VideoGLUE评分(VGS)来衡量基础模型在适配通用视频理解任务时的效能与效率。主要发现如下:首先,任务专用模型显著优于本研究中考察的六种基础模型,这与基础模型在自然语言和图像理解领域取得的成就形成鲜明对比。其次,视频原生基础模型(其预训练数据包含视频模态)在分类富含动作的视频、对动作进行时间定位以及理解包含多个动作的视频方面通常优于图像原生基础模型。第三,视频原生基础模型在轻量化适配下游任务(例如冻结FM骨干网络)时能够良好执行视频任务,而图像原生基础模型则在全端到端微调中胜出。前两项观察揭示了开展视频聚焦型基础模型研究的必要性和巨大机遇,最后一项则证实了任务与适配方法在评估基础模型时均具有关键作用。