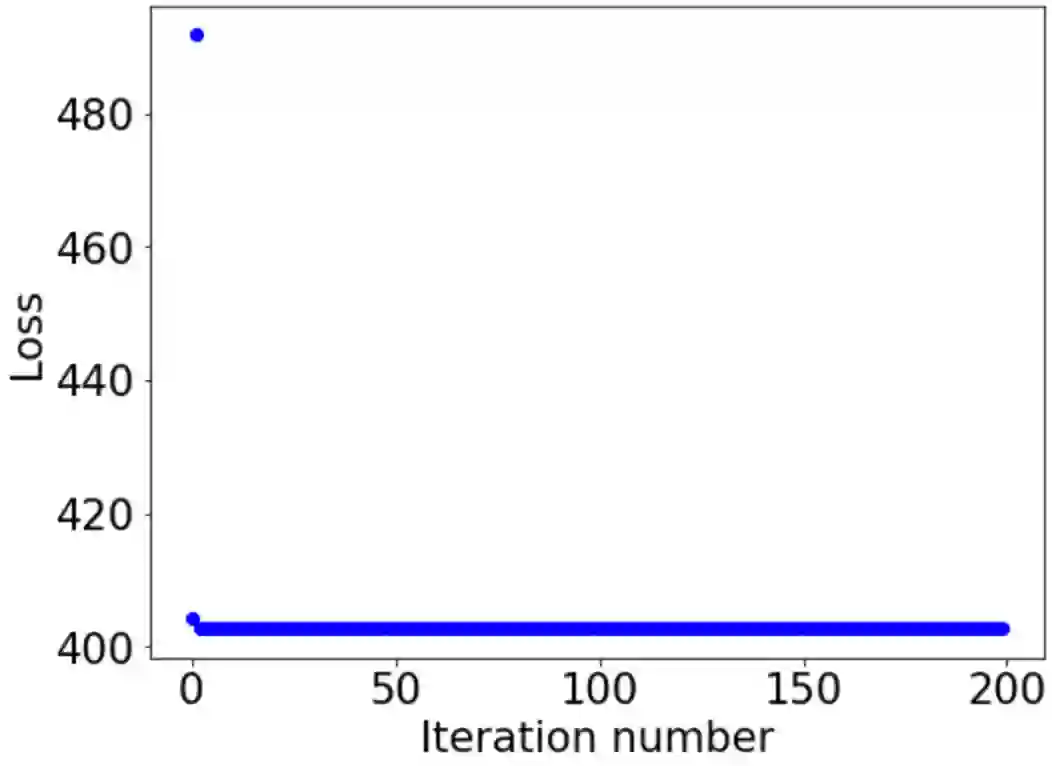
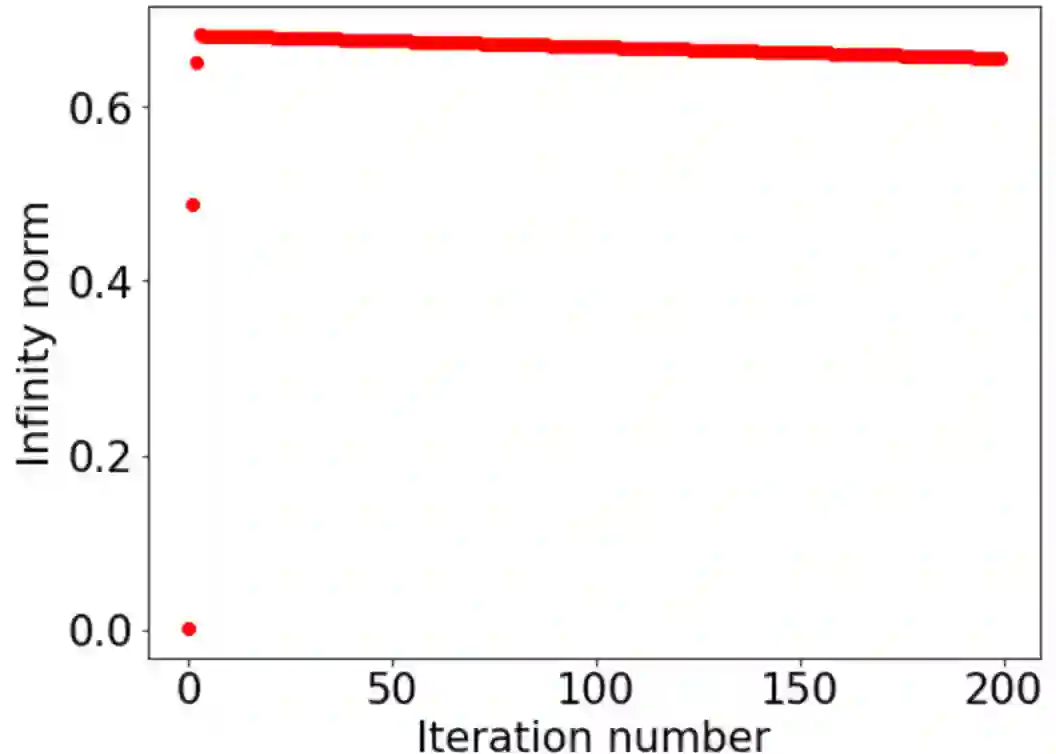
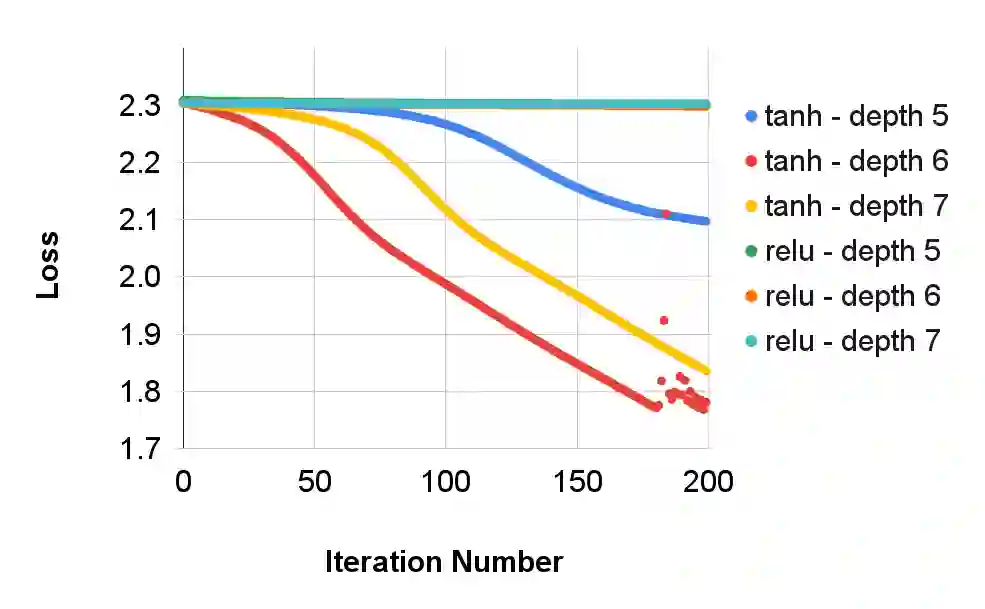
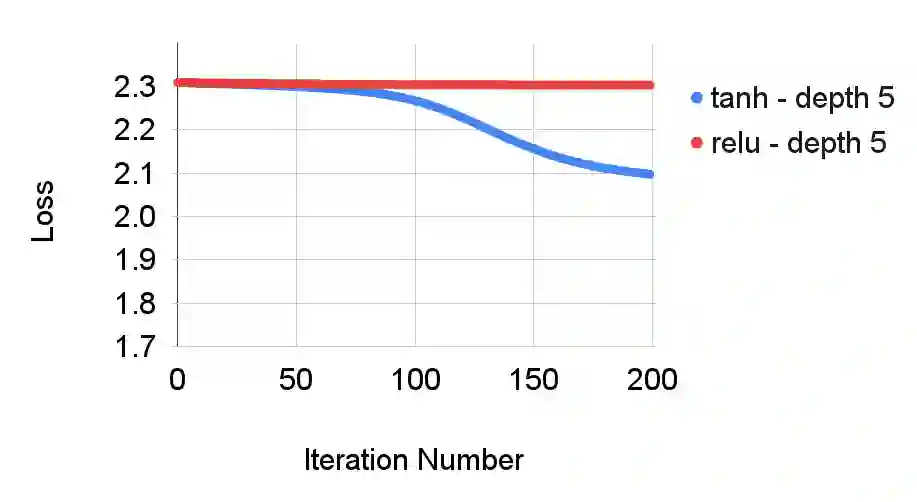
This paper investigates how non-differentiability affects three different aspects of the neural network training process. We first analyze fully connected neural networks with ReLU activations, for which we show that the continuously differentiable neural networks converge faster than non-differentiable neural networks. Next, we analyze the problem of $L_{1}$ regularization and show that the solutions produced by deep learning solvers are incorrect and counter-intuitive even for the $L_{1}$ penalized linear model. Finally, we analyze the Edge of Stability problem, where we show that all convex, non-smooth, Lipschitz continuous functions display unstable convergence, and provide an example of a result derived using twice differentiable functions which fails in the once differentiable setting. More generally, our results suggest that accounting for the non-linearity of neural networks in the training process is essential for us to develop better algorithms, and to get a better understanding of the training process in general.
翻译:本文研究了不可微性如何影响神经网络训练过程的三个不同方面。首先,我们分析了使用ReLU激活函数的全连接神经网络,结果表明连续可微的神经网络比不可微的神经网络收敛更快。其次,我们分析了$L_{1}$正则化问题,并证明深度学习求解器产生的解即使对于$L_{1}$惩罚线性模型也是错误且反直觉的。最后,我们分析了"稳定性边缘"问题,结果表明所有凸、非光滑、Lipschitz连续函数均表现出不稳定的收敛性,并提供了一个利用二次可微函数推导但在一阶可微场景中失效的结果实例。更广泛而言,我们的结果提示,在训练过程中考虑神经网络的非线性特性对于开发更优算法以及整体上更深入理解训练过程至关重要。