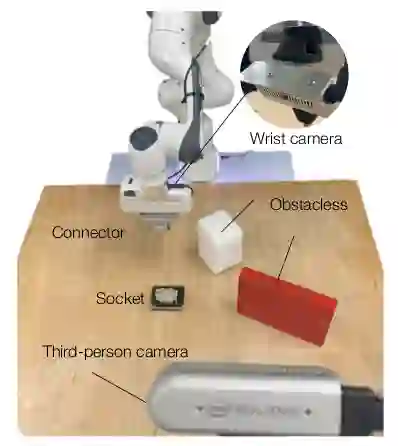
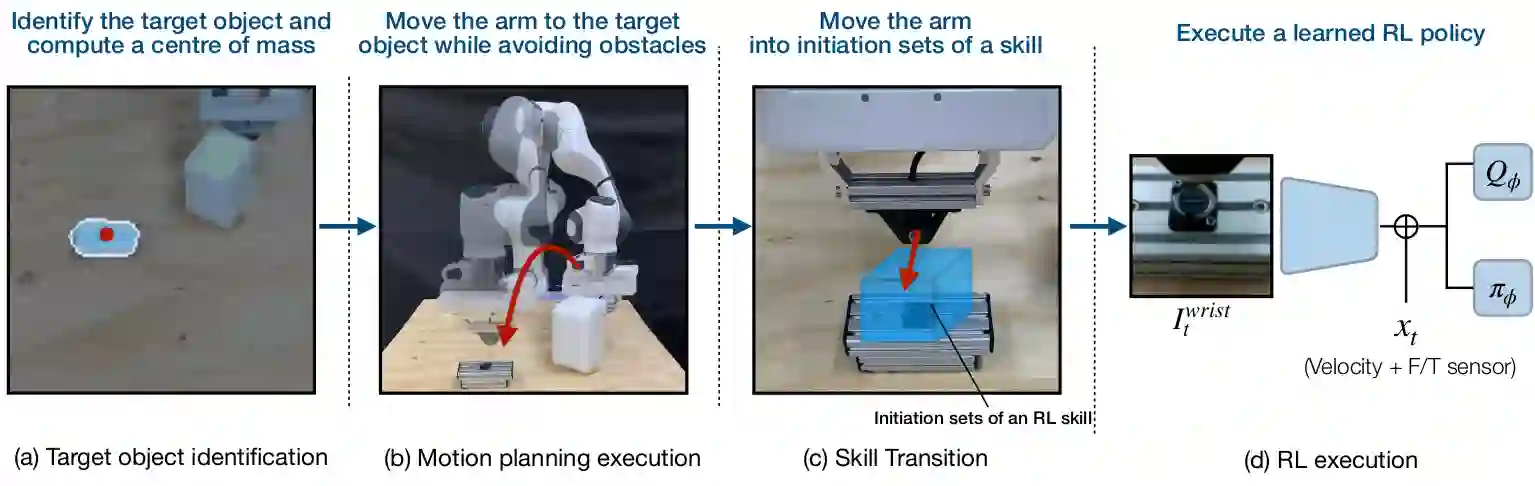
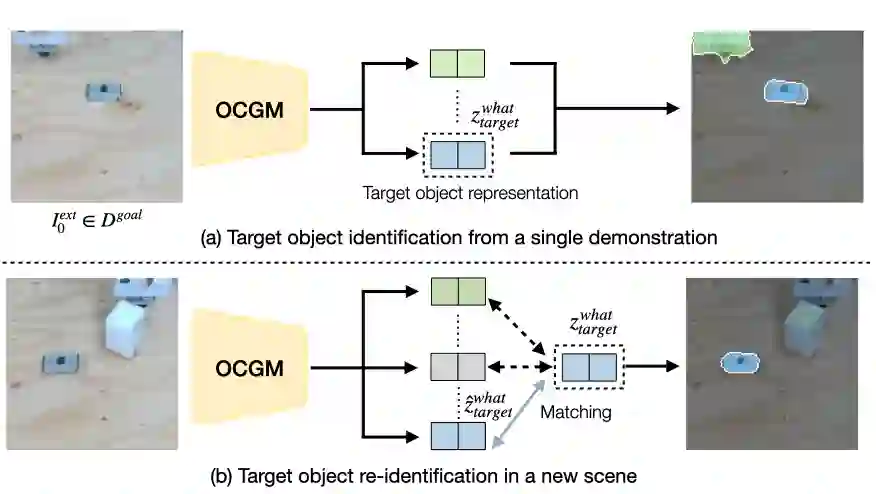
Data efficiency in robotic skill acquisition is crucial for operating robots in varied small-batch assembly settings. To operate in such environments, robots must have robust obstacle avoidance and versatile goal conditioning acquired from only a few simple demonstrations. Existing approaches, however, fall short of these requirements. Deep reinforcement learning (RL) enables a robot to learn complex manipulation tasks but is often limited to small task spaces in the real world due to sample inefficiency and safety concerns. Motion planning (MP) can generate collision-free paths in obstructed environments, but cannot solve complex manipulation tasks and requires goal states often specified by a user or object-specific pose estimator. In this work, we propose a system for efficient skill acquisition that leverages an object-centric generative model (OCGM) for versatile goal identification to specify a goal for MP combined with RL to solve complex manipulation tasks in obstructed environments. Specifically, OCGM enables one-shot target object identification and re-identification in new scenes, allowing MP to guide the robot to the target object while avoiding obstacles. This is combined with a skill transition network, which bridges the gap between terminal states of MP and feasible start states of a sample-efficient RL policy. The experiments demonstrate that our OCGM-based one-shot goal identification provides competitive accuracy to other baseline approaches and that our modular framework outperforms competitive baselines, including a state-of-the-art RL algorithm, by a significant margin for complex manipulation tasks in obstructed environments.
翻译:在机器人技能获取中,数据效率对于在多变的小批量装配环境中操作机器人至关重要。为了在这样的环境中运行,机器人必须具备鲁棒的避障能力和灵活的目标条件获取能力,且仅需少量简单演示。然而,现有方法无法满足这些要求。深度强化学习(RL)使机器人能够学习复杂操作任务,但由于样本效率低和安全问题,通常局限于现实世界中的小任务空间。运动规划(MP)可以在阻塞环境中生成无碰撞路径,但无法解决复杂操作任务,且通常需要由用户或特定物体位姿估计器指定的目标状态。在本工作中,我们提出了一种高效技能获取系统,利用以物体为中心的生成模型(OCGM)进行灵活的目标识别,以指定MP的目标,并结合RL解决阻塞环境中的复杂操作任务。具体而言,OCGM能够在新场景中一次性实现目标物体的识别与再识别,使MP能够引导机器人避开障碍物并到达目标物体。该系统与技能转换网络相结合,该网络弥补了MP终止状态与样本高效RL策略可行起始状态之间的差距。实验表明,基于OCGM的一次性目标识别在精度上与其他基线方法具有竞争力,而我们的模块化框架在阻塞环境中的复杂操作任务上,显著优于包括最先进RL算法在内的竞争基线方法。