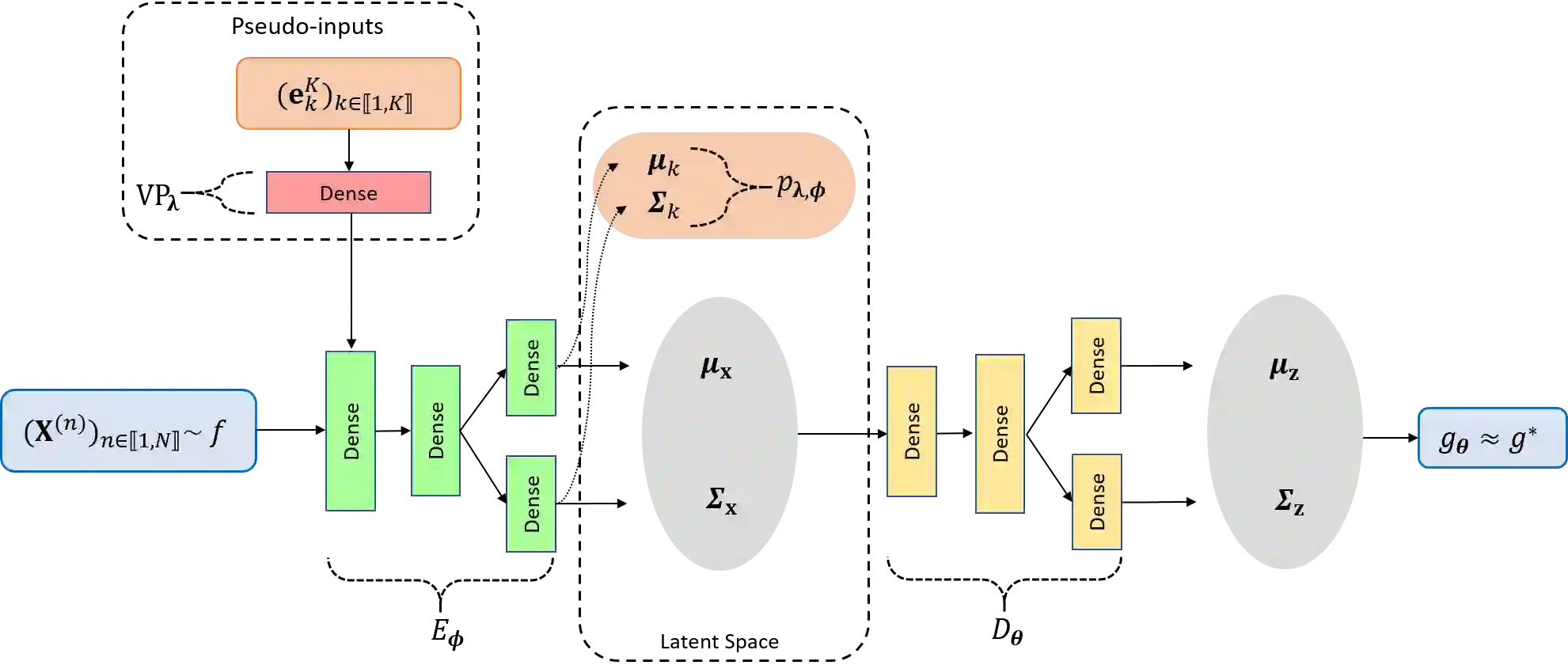
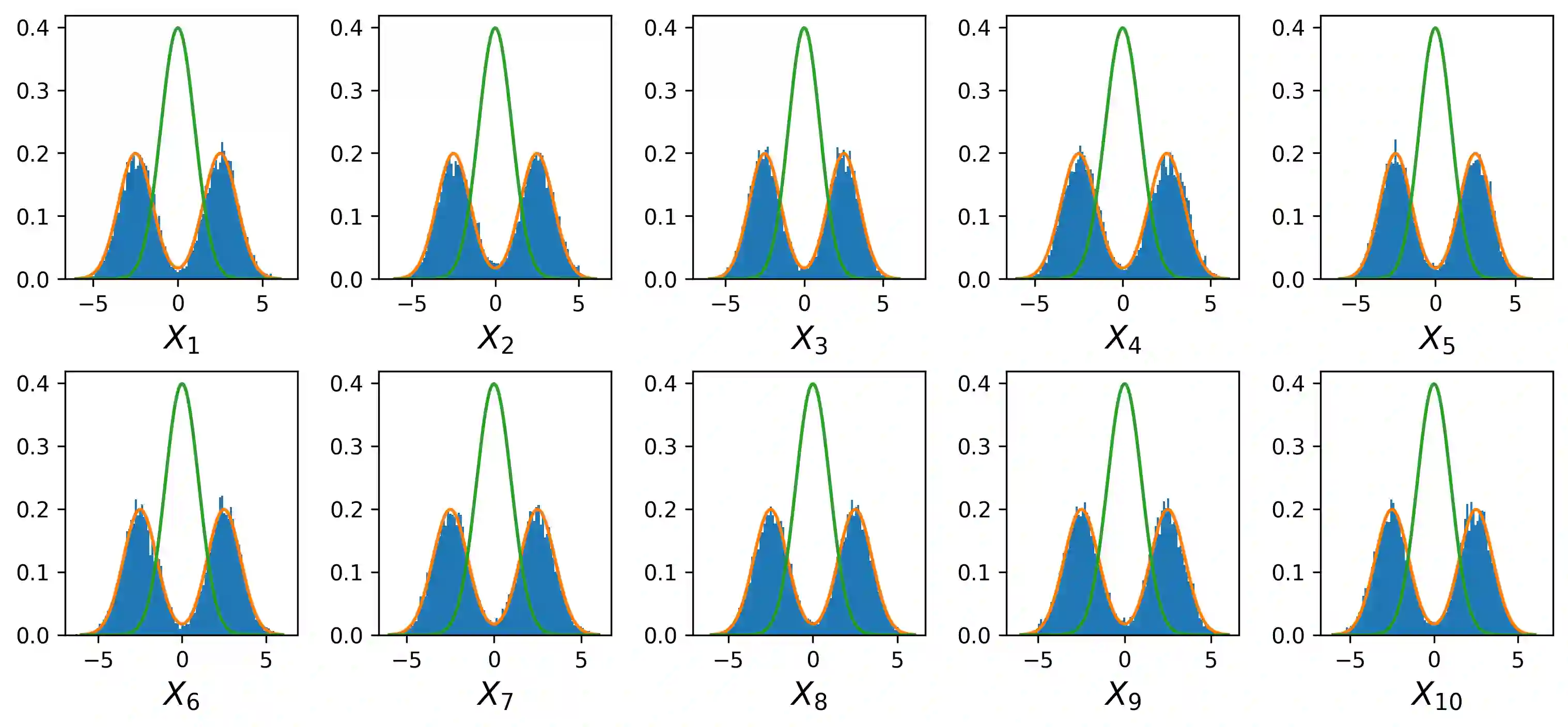
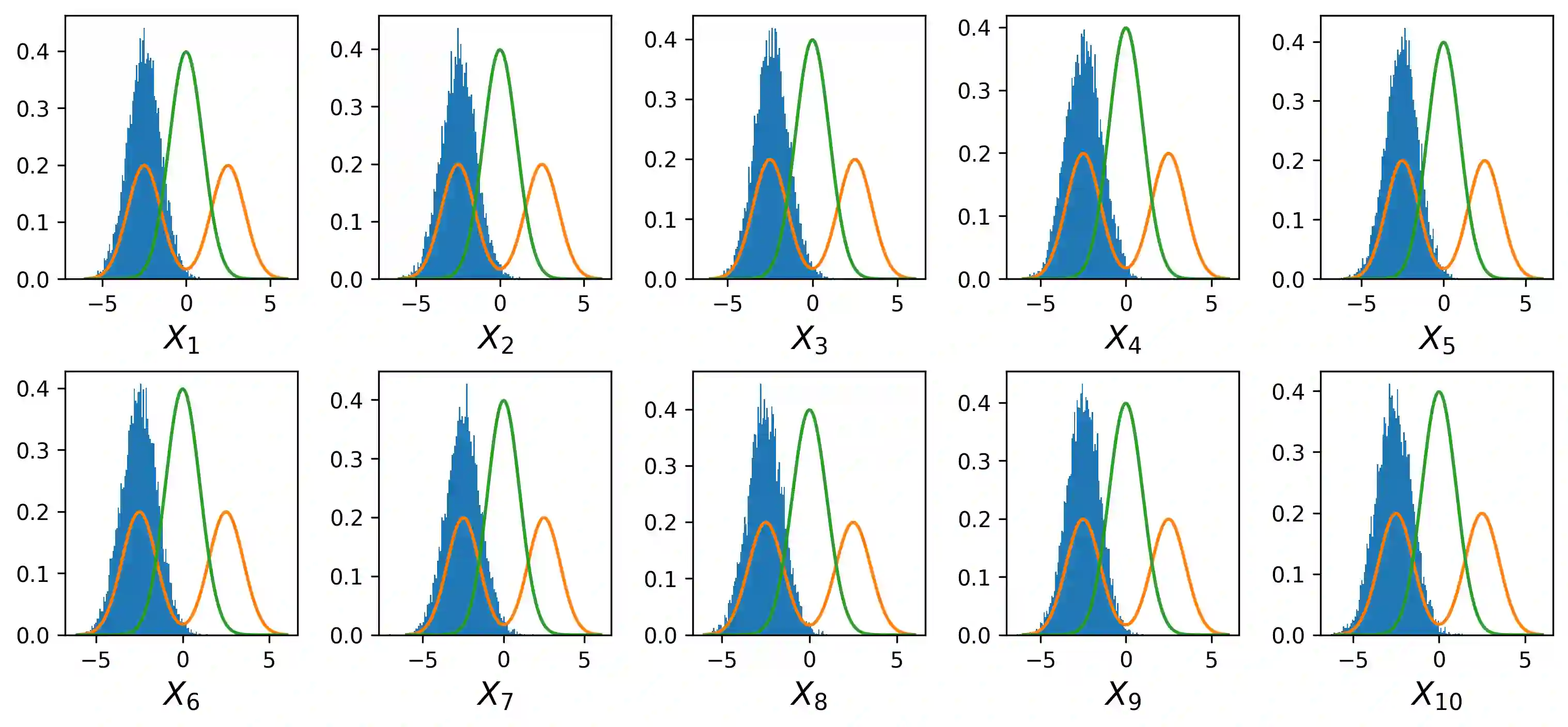
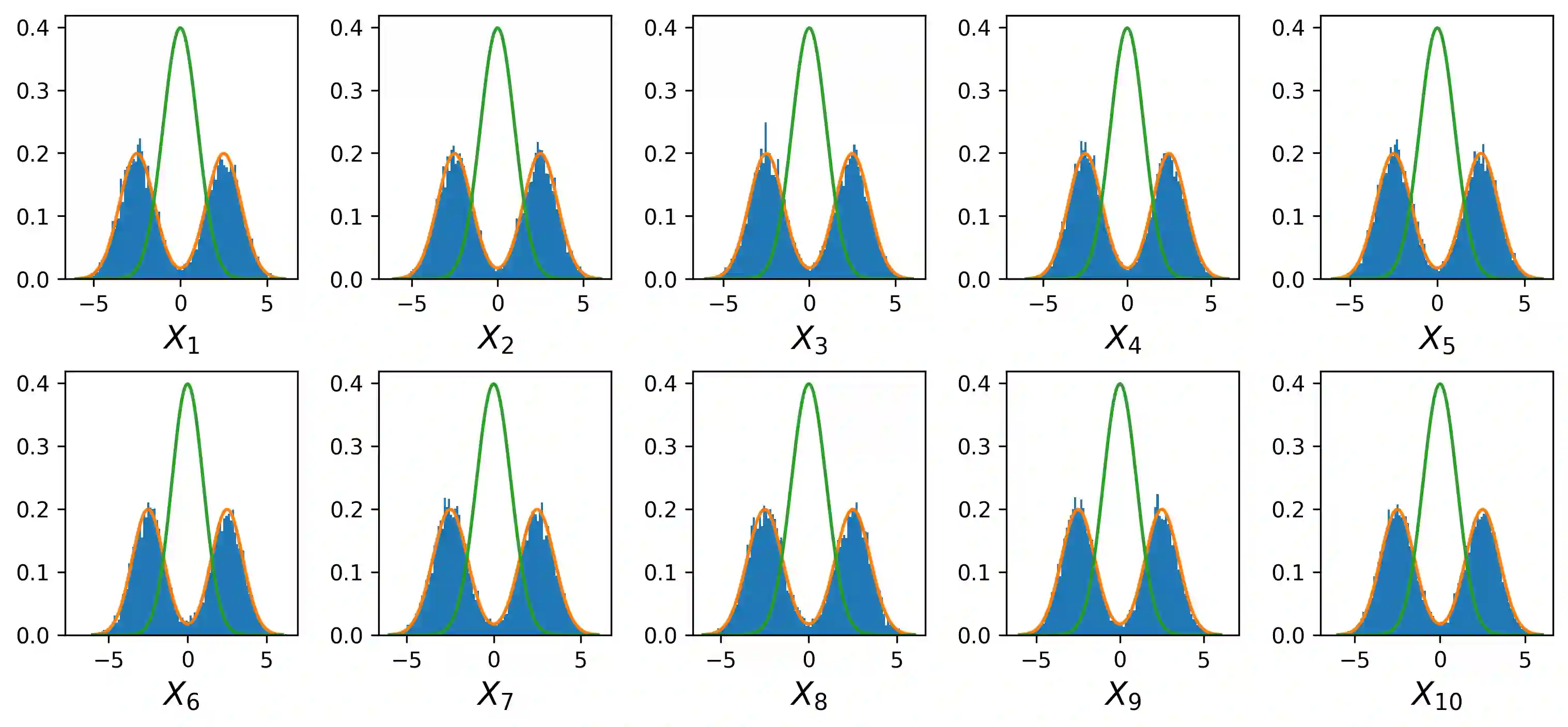
Probability density function estimation with weighted samples is the main foundation of all adaptive importance sampling algorithms. Classically, a target distribution is approximated either by a non-parametric model or within a parametric family. However, these models suffer from the curse of dimensionality or from their lack of flexibility. In this contribution, we suggest to use as the approximating model a distribution parameterised by a variational autoencoder. We extend the existing framework to the case of weighted samples by introducing a new objective function. The flexibility of the obtained family of distributions makes it as expressive as a non-parametric model, and despite the very high number of parameters to estimate, this family is much more efficient in high dimension than the classical Gaussian or Gaussian mixture families. Moreover, in order to add flexibility to the model and to be able to learn multimodal distributions, we consider a learnable prior distribution for the variational autoencoder latent variables. We also introduce a new pre-training procedure for the variational autoencoder to find good starting weights of the neural networks to prevent as much as possible the posterior collapse phenomenon to happen. At last, we explicit how the resulting distribution can be combined with importance sampling, and we exploit the proposed procedure in existing adaptive importance sampling algorithms to draw points from a target distribution and to estimate a rare event probability in high dimension on two multimodal problems.
翻译:概率密度函数的加权样本估算是所有自适应重要性采样算法的主要基础。经典方法中,目标分布通过非参数模型或参数族进行逼近。然而,这些模型要么受维度灾难限制,要么缺乏灵活性。本文提出利用变分自编码器参数化的分布作为逼近模型。我们通过引入新的目标函数,将现有框架扩展至加权样本场景。所获得的分布族兼具非参数模型的表达力,尽管需估计参数数量极高,但在高维情形下比传统高斯或高斯混合族显著高效。此外,为增强模型灵活性并支持多模态分布学习,我们为变分自编码器的隐变量引入可学习先验分布。同时提出新的预训练流程,为神经网络寻找优质初始权重,以最大限度防止后验坍塌现象。最后,我们阐明所得分布如何与重要性采样结合,并将所提方案融入现有自适应重要性采样算法中,用于从目标分布采样点,并在两个多模态问题上实现高维稀有事件概率估计。