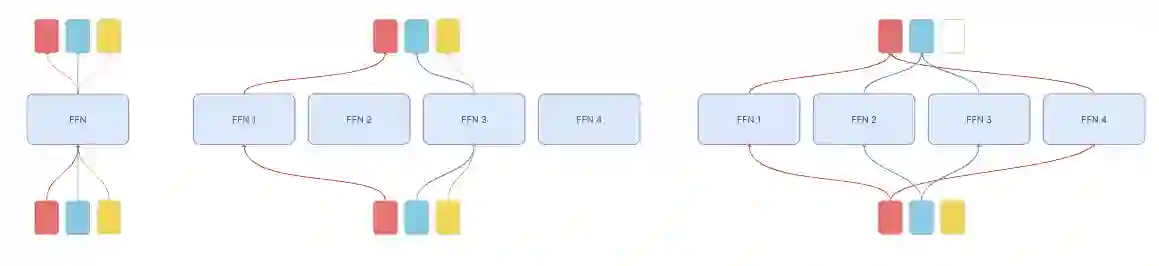
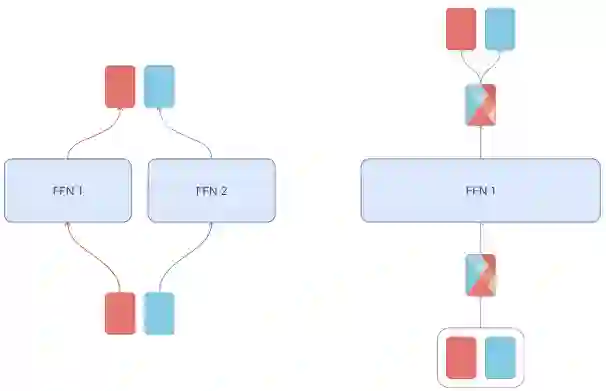
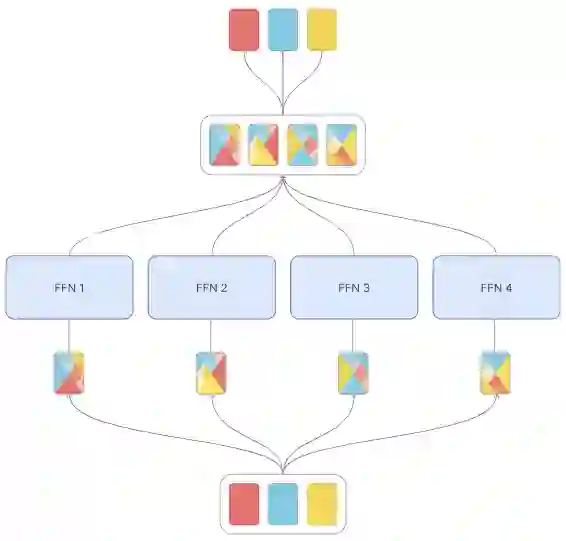
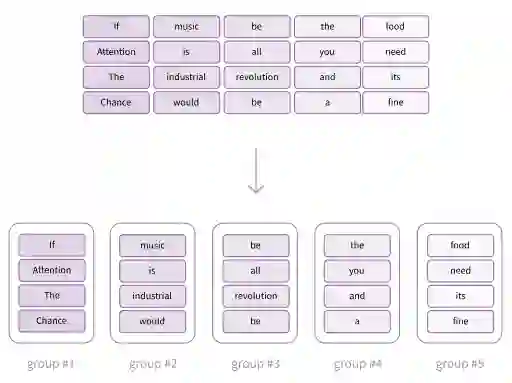
Despite the promise of Mixture of Experts (MoE) models in increasing parameter counts of Transformer models while maintaining training and inference costs, their application carries notable drawbacks. The key strategy of these models is to, for each processed token, activate at most a few experts - subsets of an extensive feed-forward layer. But this approach is not without its challenges. The operation of matching experts and tokens is discrete, which makes MoE models prone to issues like training instability and uneven expert utilization. Existing techniques designed to address these concerns, such as auxiliary losses or balance-aware matching, result either in lower model performance or are more difficult to train. In response to these issues, we propose Mixture of Tokens, a fully-differentiable model that retains the benefits of MoE architectures while avoiding the aforementioned difficulties. Rather than routing tokens to experts, this approach mixes tokens from different examples prior to feeding them to experts, enabling the model to learn from all token-expert combinations. Importantly, this mixing can be disabled to avoid mixing of different sequences during inference. Crucially, this method is fully compatible with both masked and causal Large Language Model training and inference.
翻译:尽管混合专家(MoE)模型在增加Transformer模型参数数量的同时保持训练和推理成本方面具有前景,但它们的应用存在显著缺陷。这些模型的核心策略是:对于每个处理的令牌,最多激活少量专家——即广泛前馈层的子集。然而,这种方法并非没有挑战。专家与令牌的匹配操作是离散的,这使得MoE模型容易受到训练不稳定和专家利用率不均等问题的影响。为应对这些挑战而设计的现有技术(如辅助损失或平衡感知匹配)要么导致模型性能下降,要么使其训练更加困难。针对这些问题,我们提出了令牌混合模型——一种完全可微分的模型,它保留了MoE架构的优势,同时避免了上述困难。该方法不是将令牌路由到专家,而是在将令牌输入专家之前混合不同样本的令牌,从而使模型能够从所有令牌-专家组合中学习。重要的是,这种混合可以在推理时禁用,以避免不同序列的混合。关键的是,该方法与掩码和因果大型语言模型的训练与推理完全兼容。