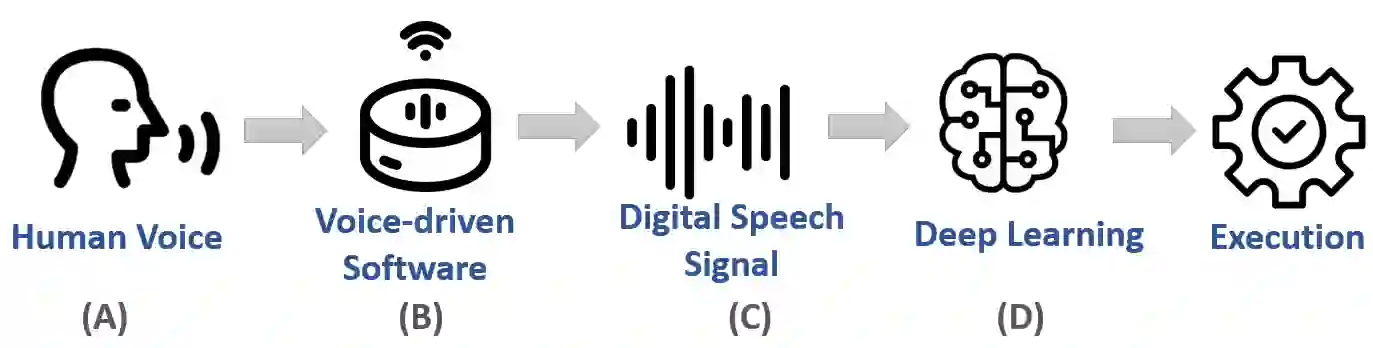
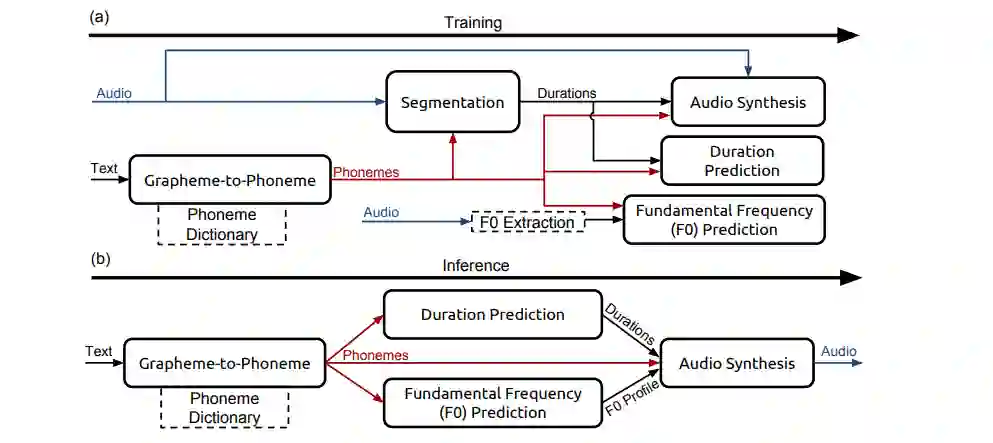
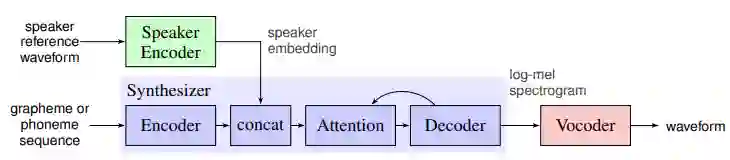
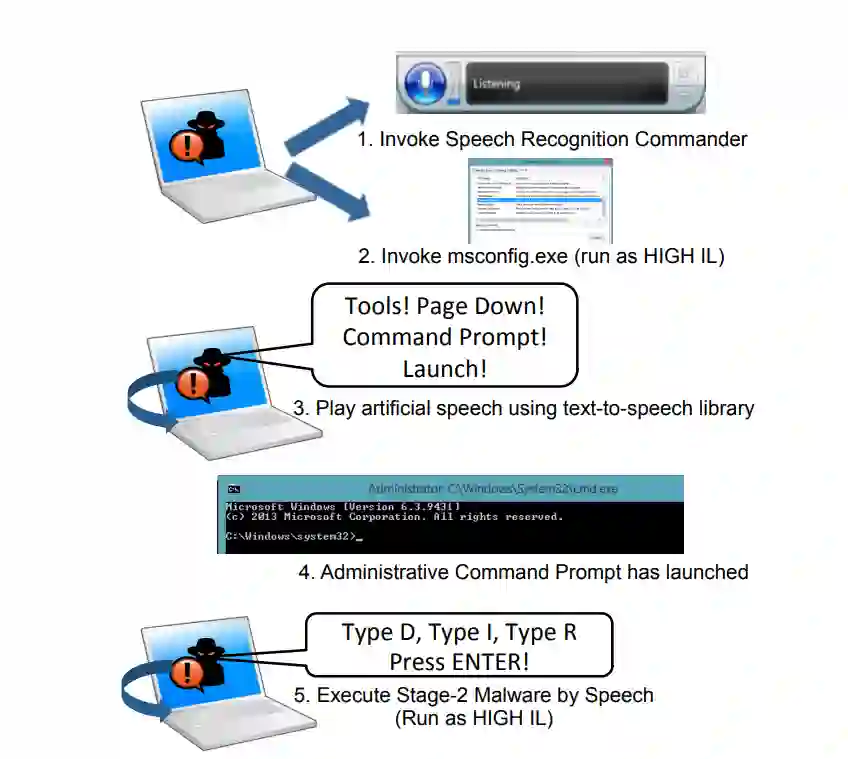
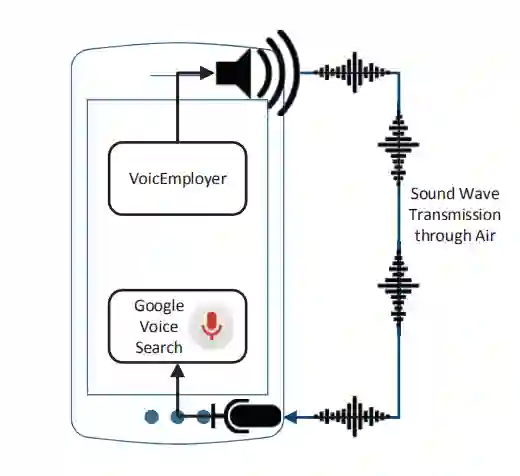
In contemporary society, voice-controlled devices, such as smartphones and home assistants, have become pervasive due to their advanced capabilities and functionality. The always-on nature of their microphones offers users the convenience of readily accessing these devices. However, recent research and events have revealed that such voice-controlled devices are prone to various forms of malicious attacks, hence making it a growing concern for both users and researchers to safeguard against such attacks. Despite the numerous studies that have investigated adversarial attacks and privacy preservation for images, a conclusive study of this nature has not been conducted for the audio domain. Therefore, this paper aims to examine existing approaches for privacy-preserving and privacy-attacking strategies for audio and speech. To achieve this goal, we classify the attack and defense scenarios into several categories and provide detailed analysis of each approach. We also interpret the dissimilarities between the various approaches, highlight their contributions, and examine their limitations. Our investigation reveals that voice-controlled devices based on neural networks are inherently susceptible to specific types of attacks. Although it is possible to enhance the robustness of such models to certain forms of attack, more sophisticated approaches are required to comprehensively safeguard user privacy.
翻译:在当代社会,智能手机和智能家居助手等语音控制设备因其先进的功能和特性而变得无处不在。这些设备麦克风始终开启的特性为用户提供了随时访问的便利。然而,近年来的研究和事件表明,此类语音控制设备易受多种恶意攻击,因此如何防范此类攻击已成为用户和研究人员日益关注的焦点。尽管已有大量研究探讨了图像领域的对抗攻击与隐私保护,但在音频领域尚未有类似的系统性研究。为此,本文旨在系统梳理针对音频与语音的隐私保护与隐私攻击策略的现有方法。我们通过将攻击与防御场景划分为多个类别,并对每种方法进行详细分析来实现这一目标。同时,我们阐释了不同方法之间的差异,强调了它们的贡献,并审视了其局限性。研究结果表明,基于神经网络的语音控制设备天生易受特定类型的攻击。虽然可以增强这类模型对某些攻击形式的鲁棒性,但若要全面保护用户隐私,仍需要更复杂的技术手段。