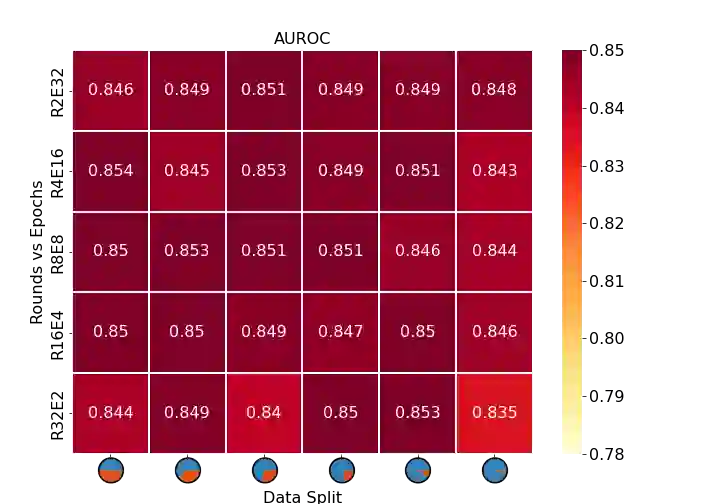
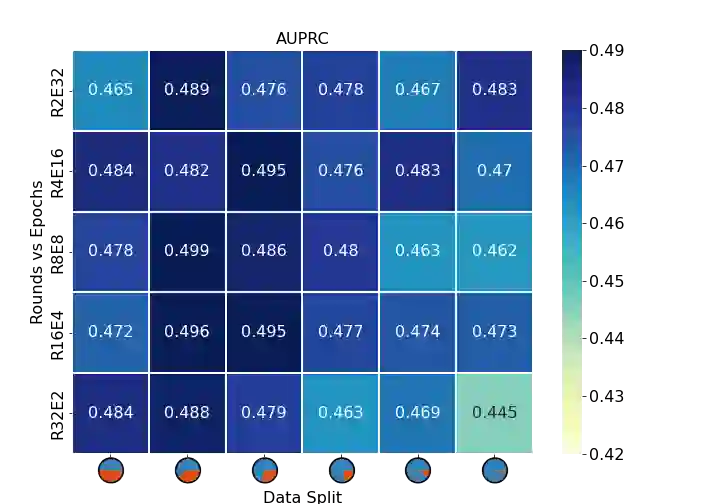
Background: Federated learning methods offer the possibility of training machine learning models on privacy-sensitive data sets, which cannot be easily shared. Multiple regulations pose strict requirements on the storage and usage of healthcare data, leading to data being in silos (i.e. locked-in at healthcare facilities). The application of federated algorithms on these datasets could accelerate disease diagnostic, drug development, as well as improve patient care. Methods: We present an extensive evaluation of the impact of different federation and differential privacy techniques when training models on the open-source MIMIC-III dataset. We analyze a set of parameters influencing a federated model performance, namely data distribution (homogeneous and heterogeneous), communication strategies (communication rounds vs. local training epochs), federation strategies (FedAvg vs. FedProx). Furthermore, we assess and compare two differential privacy (DP) techniques during model training: a stochastic gradient descent-based differential privacy algorithm (DP-SGD), and a sparse vector differential privacy technique (DP-SVT). Results: Our experiments show that extreme data distributions across sites (imbalance either in the number of patients or the positive label ratios between sites) lead to a deterioration of model performance when trained using the FedAvg strategy. This issue is resolved when using FedProx with the use of appropriate hyperparameter tuning. Furthermore, the results show that both differential privacy techniques can reach model performances similar to those of models trained without DP, however at the expense of a large quantifiable privacy leakage. Conclusions: We evaluate empirically the benefits of two federation strategies and propose optimal strategies for the choice of parameters when using differential privacy techniques.
翻译:背景:联邦学习方法为在隐私敏感数据集(这些数据难以直接共享)上训练机器学习模型提供了可能。多项法规对医疗数据的存储和使用提出了严格要求,导致数据孤立(即被锁定在医疗机构内部)。在这些数据集上应用联邦算法可加速疾病诊断、药物研发并改善患者护理。方法:我们全面评估了在开源MIMIC-III数据集上训练模型时,不同联邦策略与差分隐私技术的影响。分析了一组影响联邦模型性能的参数,包括数据分布(同质与异质)、通信策略(通信轮次与本地训练轮次)、联邦策略(FedAvg与FedProx)。此外,我们评估并比较了模型训练中的两种差分隐私技术:基于随机梯度下降的差分隐私算法(DP-SGD)与稀疏向量差分隐私技术(DP-SVT)。结果:实验表明,当采用FedAvg策略时,站点间的极端数据分布(站点间患者数量或阳性标签比例的不平衡)会导致模型性能下降。通过使用FedProx并进行适当的超参数调优可解决此问题。此外,结果表明两种差分隐私技术均能达到与未使用DP训练模型相近的性能,但牺牲了较大的可量化隐私泄露。结论:我们通过实验评估了两种联邦策略的优势,并提出了在使用差分隐私技术时的参数选择最优策略。