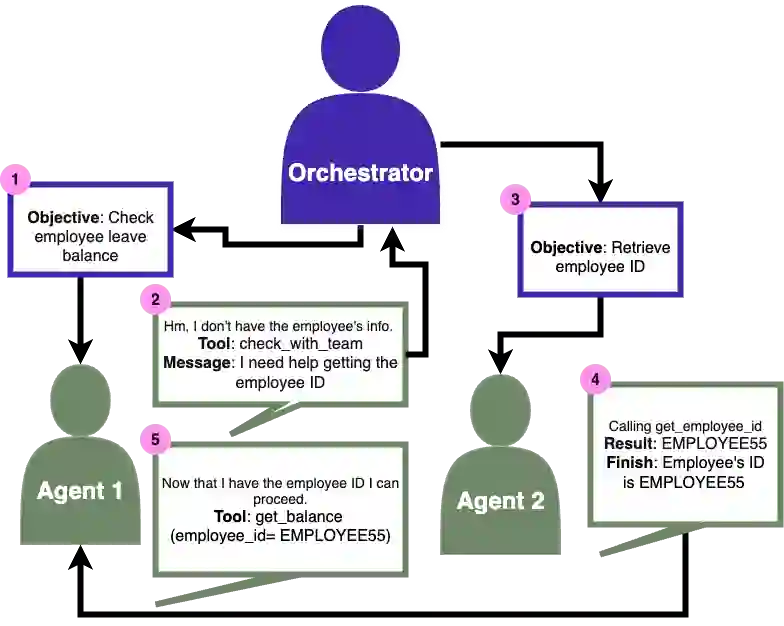
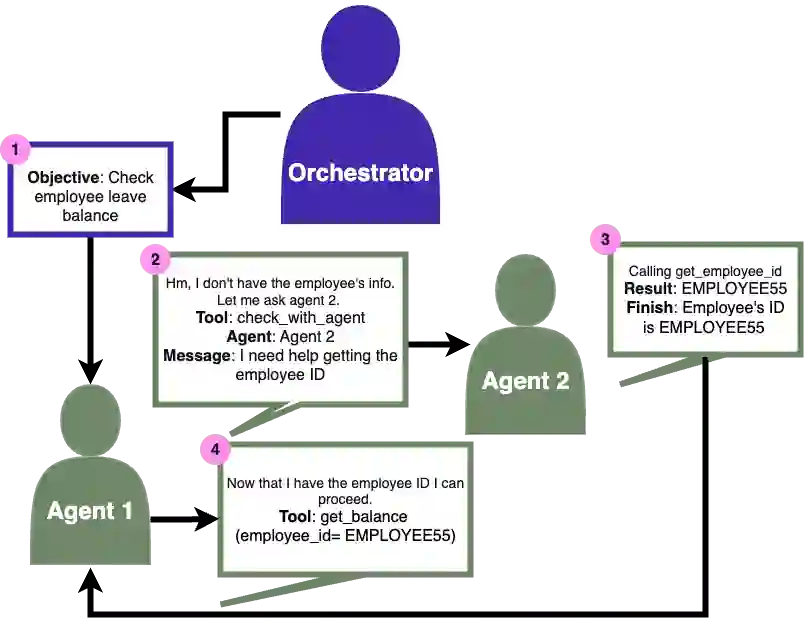
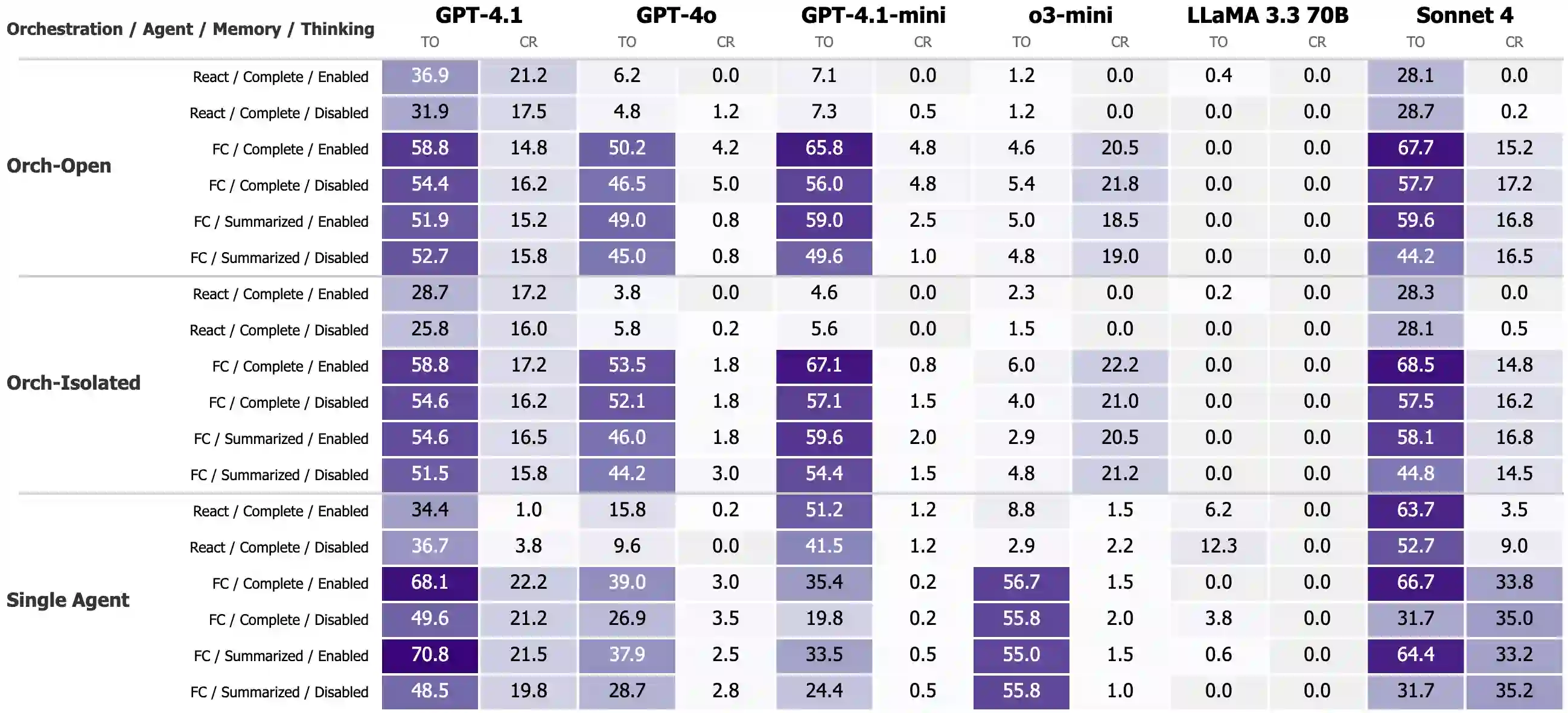
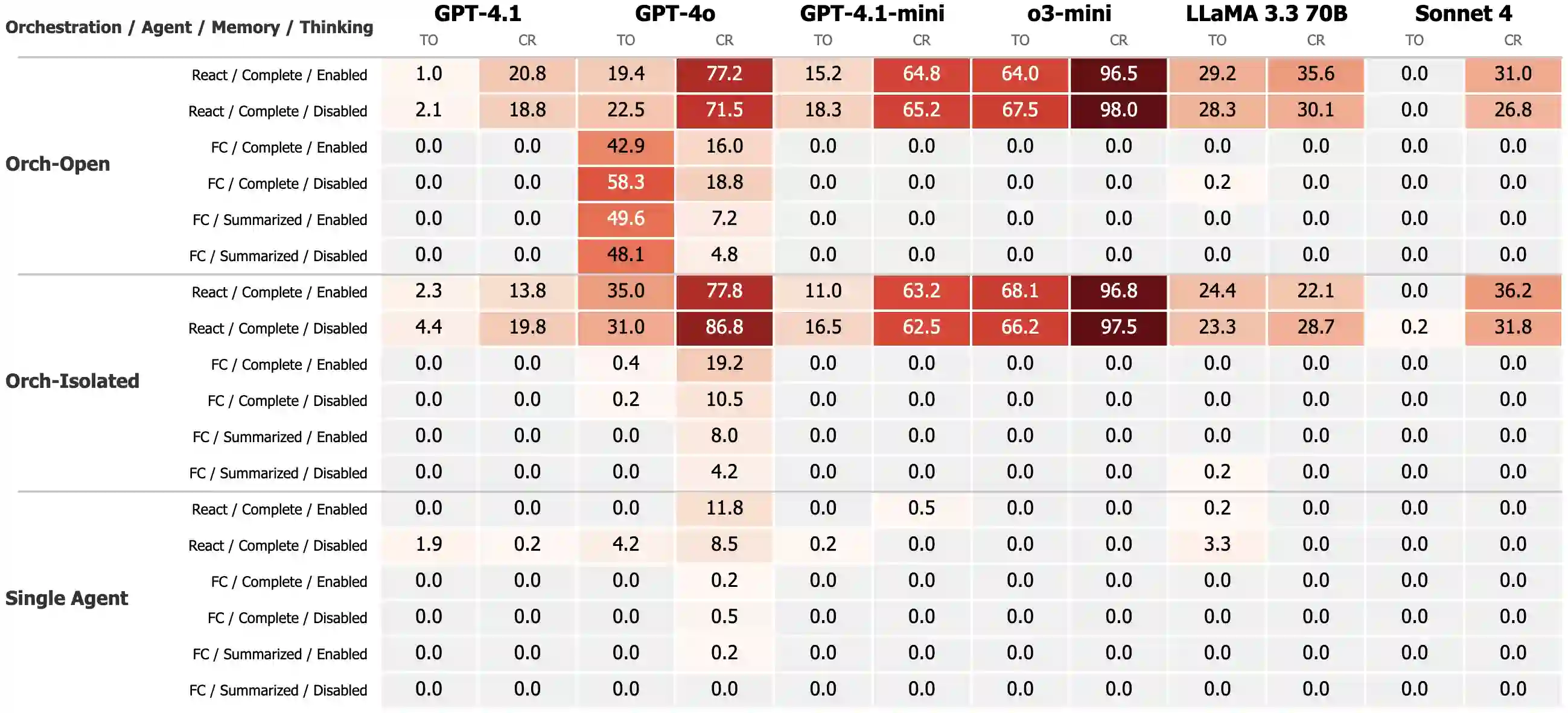
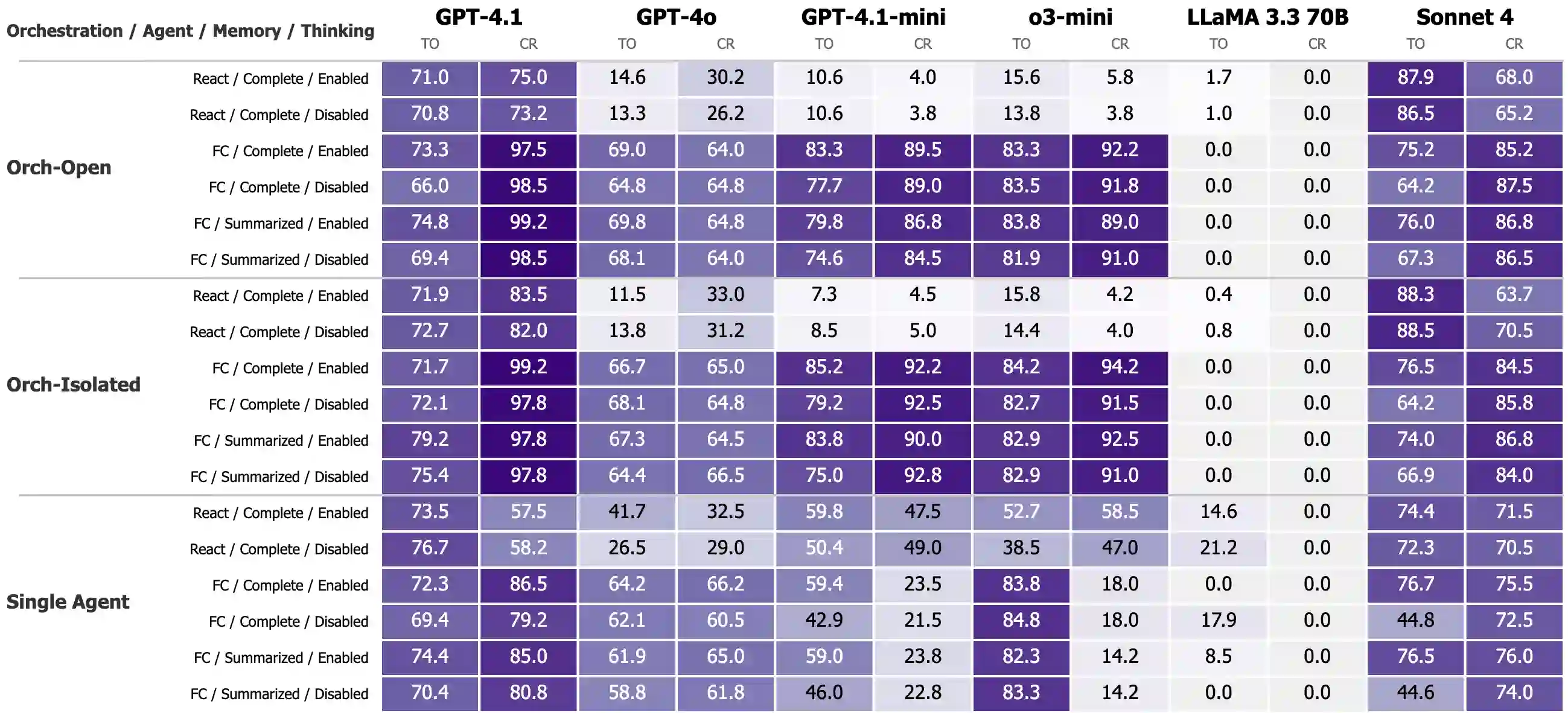
While individual components of agentic architectures have been studied in isolation, there remains limited empirical understanding of how different design dimensions interact within complex multi-agent systems. This study aims to address these gaps by providing a comprehensive enterprise-specific benchmark evaluating 18 distinct agentic configurations across state-of-the-art large language models. We examine four critical agentic system dimensions: orchestration strategy, agent prompt implementation (ReAct versus function calling), memory architecture, and thinking tool integration. Our benchmark reveals significant model-specific architectural preferences that challenge the prevalent one-size-fits-all paradigm in agentic AI systems. It also reveals significant weaknesses in overall agentic performance on enterprise tasks with the highest scoring models achieving a maximum of only 35.3\% success on the more complex task and 70.8\% on the simpler task. We hope these findings inform the design of future agentic systems by enabling more empirically backed decisions regarding architectural components and model selection.
翻译:尽管智能体架构的各个组件已在孤立环境中得到研究,但关于不同设计维度在复杂多智能体系统中如何相互作用的实证认知仍然有限。本研究旨在通过构建面向企业场景的综合评估基准来填补这一空白,该基准覆盖18种不同的智能体配置,并基于前沿大语言模型进行评估。我们考察了智能体系统的四个关键维度:协同调度策略、智能体提示实现方式(ReAct与函数调用对比)、记忆架构以及思维工具集成。我们的基准测试揭示了显著的模型特异性架构偏好,这对当前智能体人工智能系统中普遍存在的“一刀切”范式提出了挑战。同时,研究还发现智能体在企业任务上的整体表现存在明显不足:在更复杂的任务中得分最高的模型成功率最高仅为35.3%,而在较简单任务中也仅达到70.8%。我们期望这些发现能为未来智能体系统的设计提供参考,通过在架构组件和模型选择方面提供更多实证依据来支持决策制定。