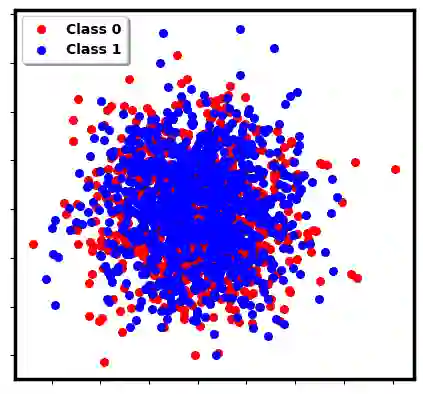
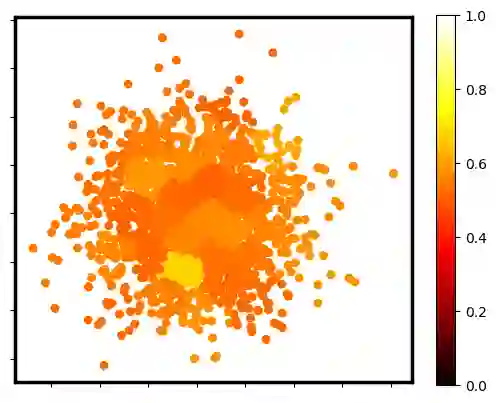
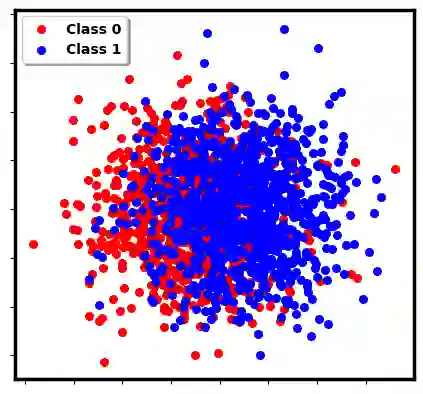
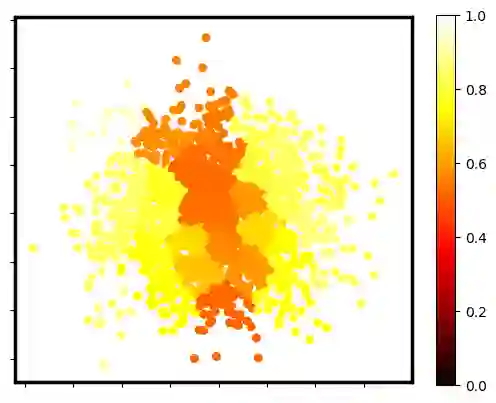
Two-sample testing tests whether the distributions generating two samples are identical. We pose the two-sample testing problem in a new scenario where the sample measurements (or sample features) are inexpensive to access, but their group memberships (or labels) are costly. We devise the first \emph{active sequential two-sample testing framework} that not only sequentially but also \emph{actively queries} sample labels to address the problem. Our test statistic is a likelihood ratio where one likelihood is found by maximization over all class priors, and the other is given by a classification model. The classification model is adaptively updated and then used to guide an active query scheme called bimodal query to label sample features in the regions with high dependency between the feature variables and the label variables. The theoretical contributions in the paper include proof that our framework produces an \emph{anytime-valid} $p$-value; and, under reachable conditions and a mild assumption, the framework asymptotically generates a minimum normalized log-likelihood ratio statistic that a passive query scheme can only achieve when the feature variable and the label variable have the highest dependence. Lastly, we provide a \emph{query-switching (QS)} algorithm to decide when to switch from passive query to active query and adapt bimodal query to increase the testing power of our test. Extensive experiments justify our theoretical contributions and the effectiveness of QS.
翻译:双样本检验用于检验生成两个样本的分布是否相同。本文提出了一种新的双样本检验场景:样本测量值(或样本特征)易于获取,但其群体归属(或标签)成本高昂。我们设计了首个**主动序列双样本检验框架**,该框架不仅能够**序列化**地,还能**主动查询**样本标签以解决该问题。我们的检验统计量是一个似然比:其中一个似然值通过对所有类别先验进行最大化得到,另一个则由分类模型给出。分类模型经过自适应更新后,用于指导一种称为**双模态查询**的主动查询方案,以标记特征变量与标签变量之间依赖性较高的区域中的样本特征。本文的理论贡献包括:证明我们的框架能够生成**任意时间有效**的p值;在可达条件和温和假设下,该框架渐进地生成一个最小归一化对数似然比统计量,而被动查询方案仅当特征变量与标签变量具有最高相关性时才能达到此效果。最后,我们提出一种**查询切换(QS)**算法,用于决定何时从被动查询切换为主动查询,并自适应调整双模态查询以增强检验的功效。大量实验验证了我们的理论贡献及QS算法的有效性。