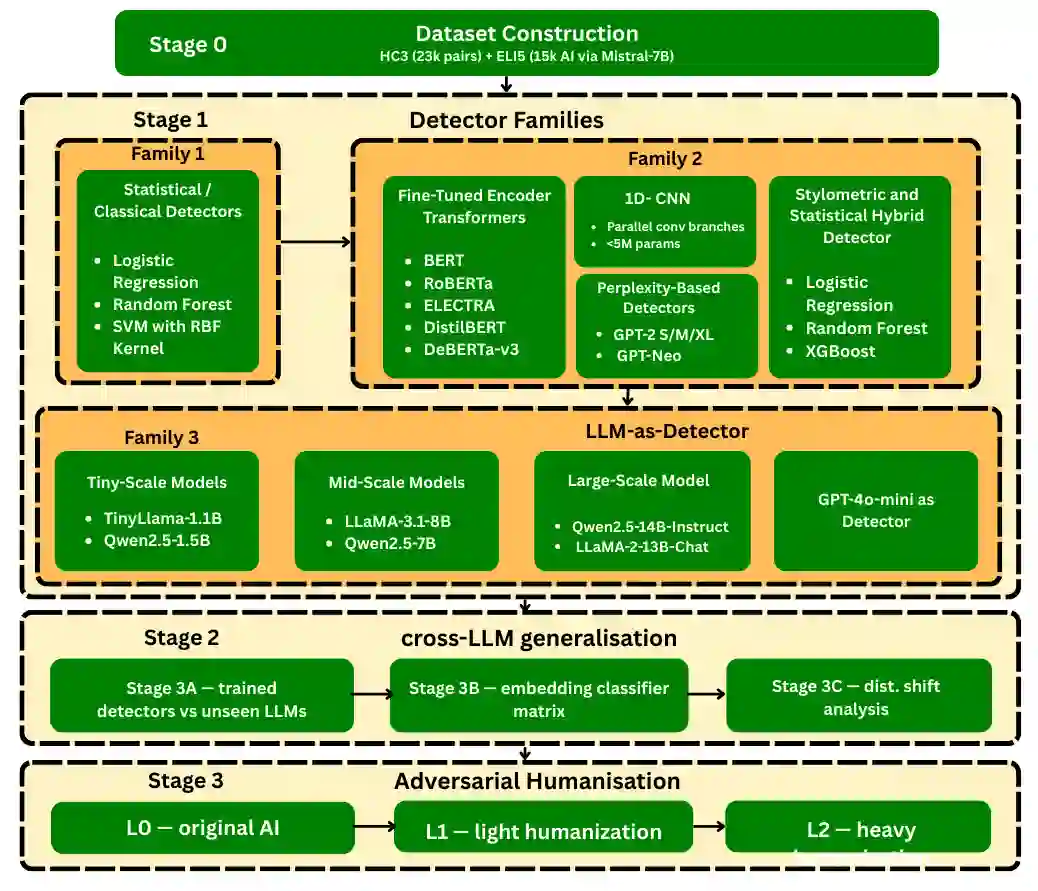
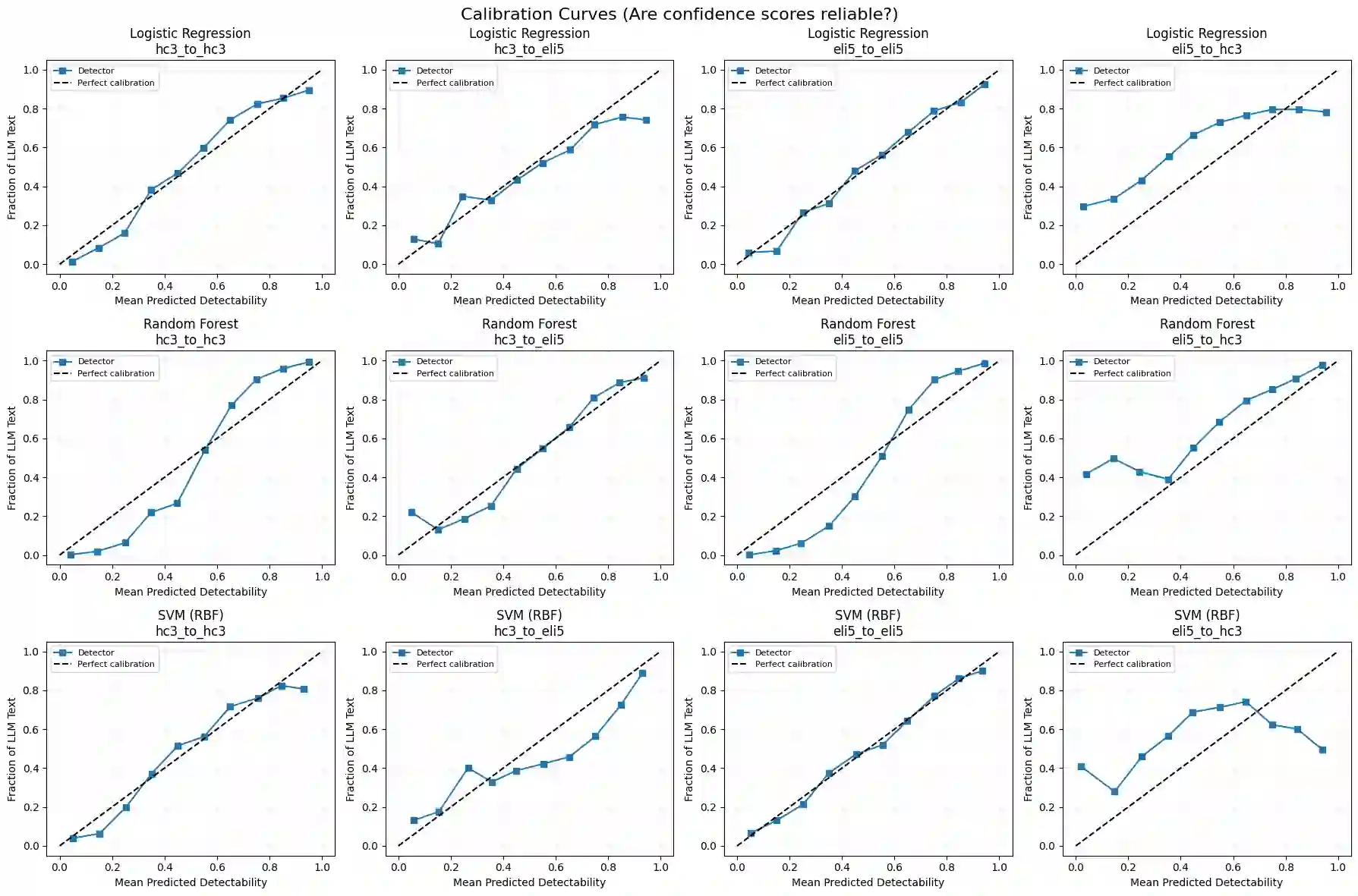
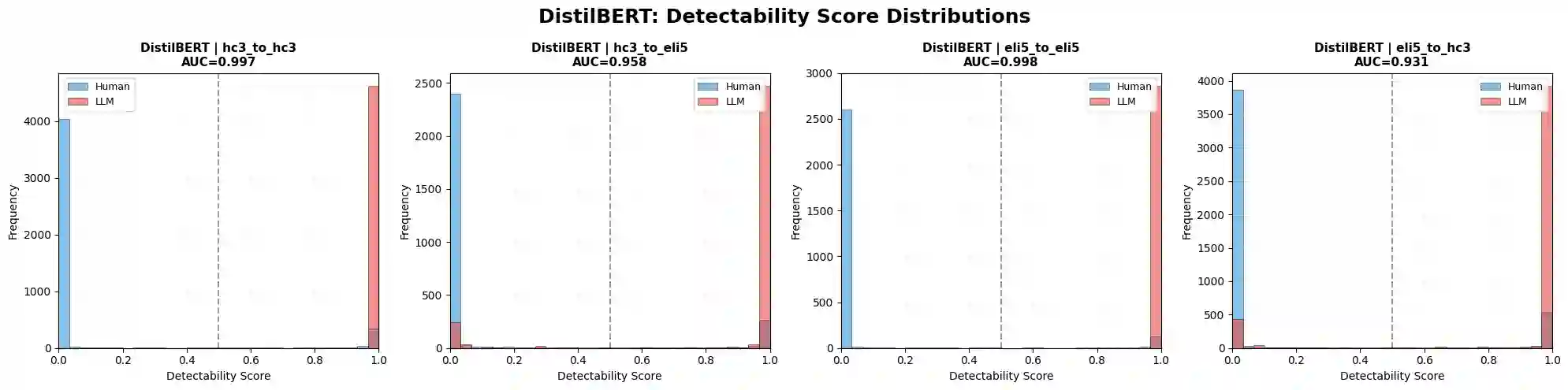
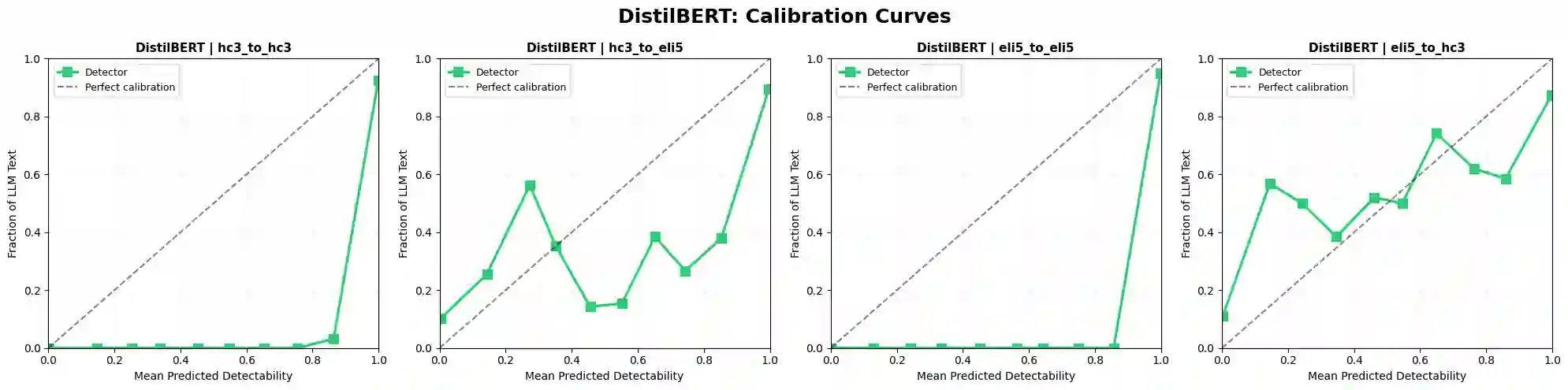
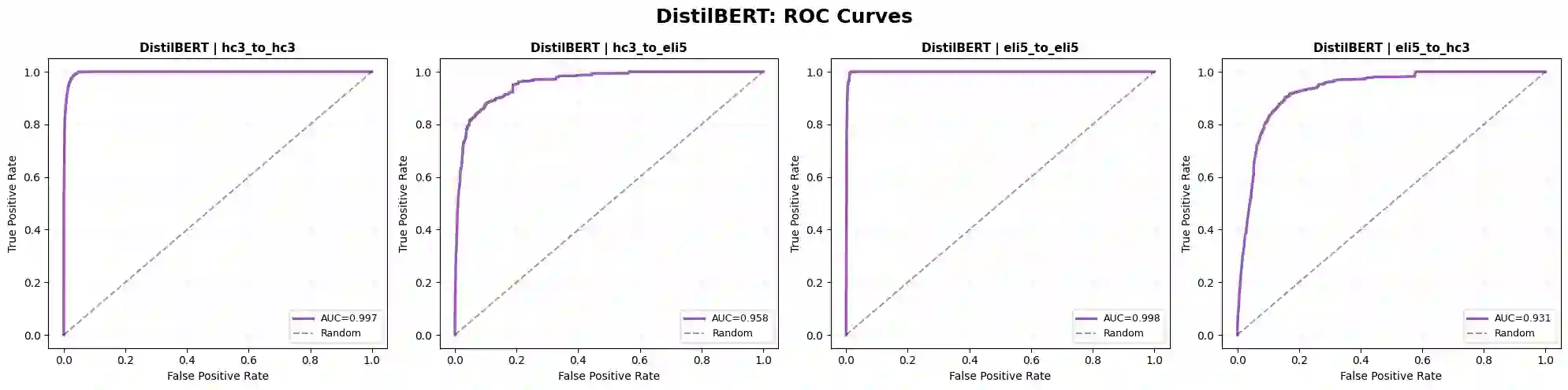
The rapid proliferation of large language models (LLMs) has created an urgent need for robust and generalizable detectors of machine-generated text. Existing benchmarks typically evaluate a single detector on a single dataset under ideal conditions, leaving open questions about cross-domain transfer, cross-LLM generalization, and adversarial robustness. We present a comprehensive benchmark evaluating diverse detection approaches across two corpora: HC3 (23,363 human-ChatGPT pairs) and ELI5 (15,000 human-Mistral-7B pairs). Methods include classical classifiers, fine-tuned transformer encoders (BERT, RoBERTa, ELECTRA, DistilBERT, DeBERTa-v3), a CNN, an XGBoost stylometric model, perplexity-based detectors, and LLM-as-detector prompting. Results show that transformer models achieve near-perfect in-distribution performance but degrade under domain shift. The XGBoost stylometric model matches performance while remaining interpretable. LLM-based detectors underperform and are affected by generator-detector identity bias. Perplexity-based methods exhibit polarity inversion, with modern LLM outputs showing lower perplexity than human text, but remain effective when corrected. No method generalizes robustly across domains and LLM sources.
翻译:大型语言模型(LLM)的快速扩散催生了对鲁棒且可泛化的机器生成文本检测器的迫切需求。现有基准通常仅在理想条件下针对单一数据集评估单一检测器,未能解决跨领域迁移、跨LLM泛化及对抗鲁棒性等关键问题。本文提出一个综合基准,在两个语料库上评估多种检测方法:HC3(23,363个人类-ChatGPT对话对)和ELI5(15,000个人类-Mistral-7B对话对)。评估方法涵盖经典分类器、微调Transformer编码器(BERT、RoBERTa、ELECTRA、DistilBERT、DeBERTa-v3)、CNN、XGBoost风格计量模型、基于困惑度的检测器以及LLM作为检测器的提示方法。实验结果表明:Transformer模型在分布内数据上达到接近完美的性能,但在领域偏移下显著退化;XGBoost风格计量模型在保持可解释性的同时达到相当性能;基于LLM的检测器表现欠佳且受生成器-检测器身份偏差影响;基于困惑度的方法出现极性反转现象(现代LLM输出文本的困惑度低于人类文本),但经校正后仍保持有效性。所有方法均未能在跨领域和跨LLM场景中实现鲁棒泛化。