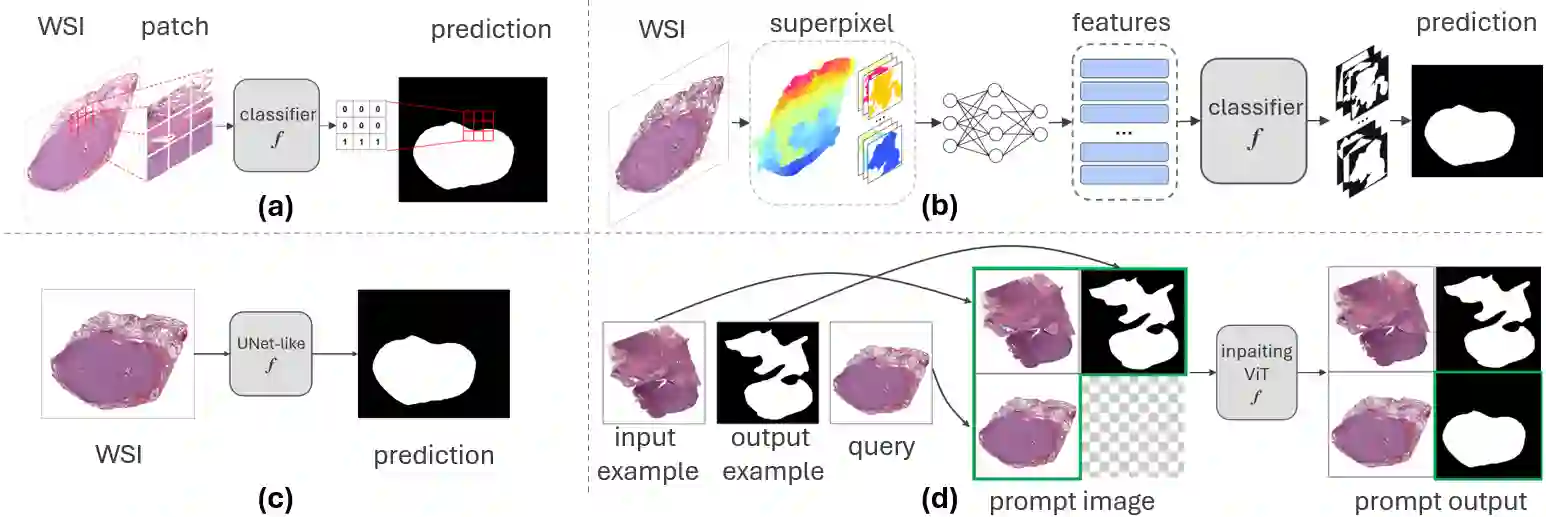
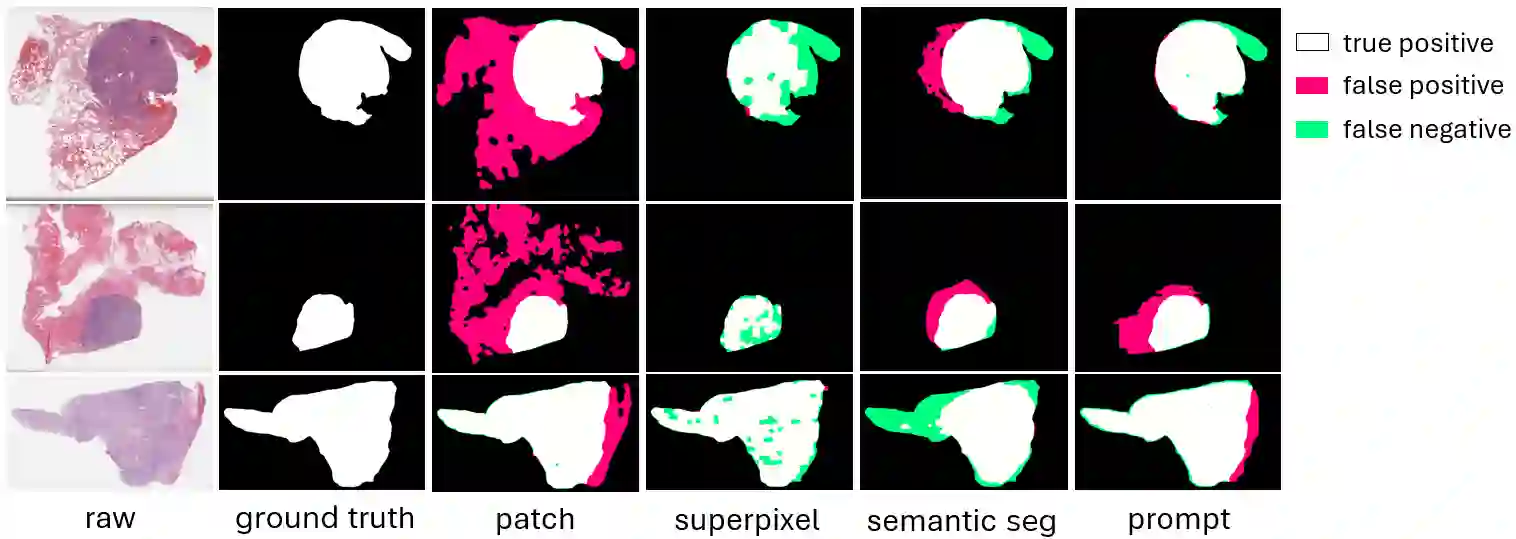
Tumor segmentation stands as a pivotal task in cancer diagnosis. Given the immense dimensions of whole slide images (WSI) in histology, deep learning approaches for WSI classification mainly operate at patch-wise or superpixel-wise level. However, these solutions often struggle to capture global WSI information and cannot directly generate the binary mask. Downsampling the WSI and performing semantic segmentation is another possible approach. While this method offers computational efficiency, it necessitates a large amount of annotated data since resolution reduction may lead to information loss. Visual prompting is a novel paradigm that allows the model to perform new tasks by making subtle modifications to the input space, rather than adapting the model itself. Such approach has demonstrated promising results on many computer vision tasks. In this paper, we show the efficacy of visual prompting in the context of tumor segmentation for three distinct organs. In comparison to classical methods trained for this specific task, our findings reveal that, with appropriate prompt examples, visual prompting can achieve comparable or better performance without extensive fine-tuning.
翻译:肿瘤分割是癌症诊断中的关键任务。由于组织学中全切片图像(WSI)尺寸巨大,用于WSI分类的深度学习方法主要基于图像块或超像素级进行处理。然而,这些方法往往难以捕捉全局WSI信息,且无法直接生成二值掩膜。对WSI进行降采样并执行语义分割是另一种可行方案。尽管该方法具有计算效率优势,但由于分辨率降低可能导致信息丢失,因此需要大量标注数据。视觉提示是一种新颖范式,它允许模型通过对输入空间进行微小修改来执行新任务,而非调整模型本身。此类方法已在多项计算机视觉任务中展现出令人瞩目的效果。本文展示了视觉提示在三种不同器官的肿瘤分割任务中的有效性。与针对该特定任务训练的传统方法相比,我们的研究结果表明,通过提供恰当的提示示例,视觉提示无需广泛微调即可实现相当或更优的性能表现。