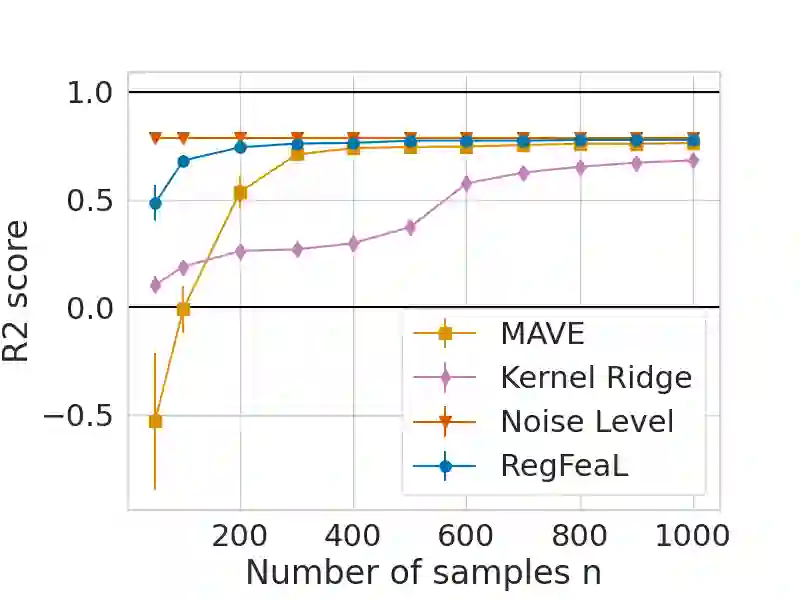
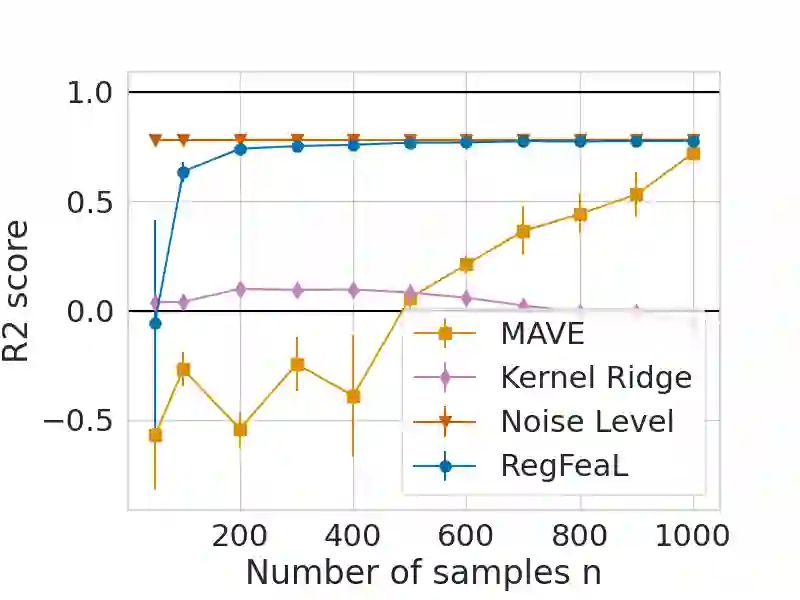
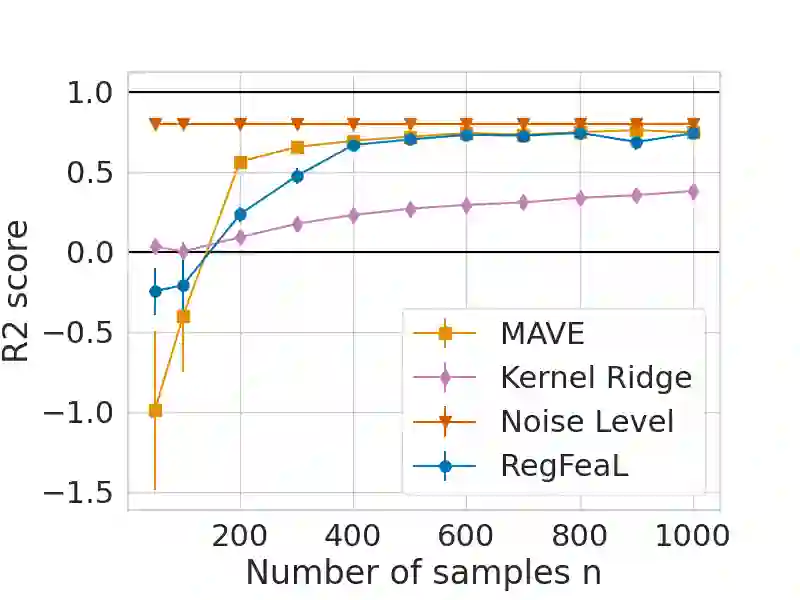
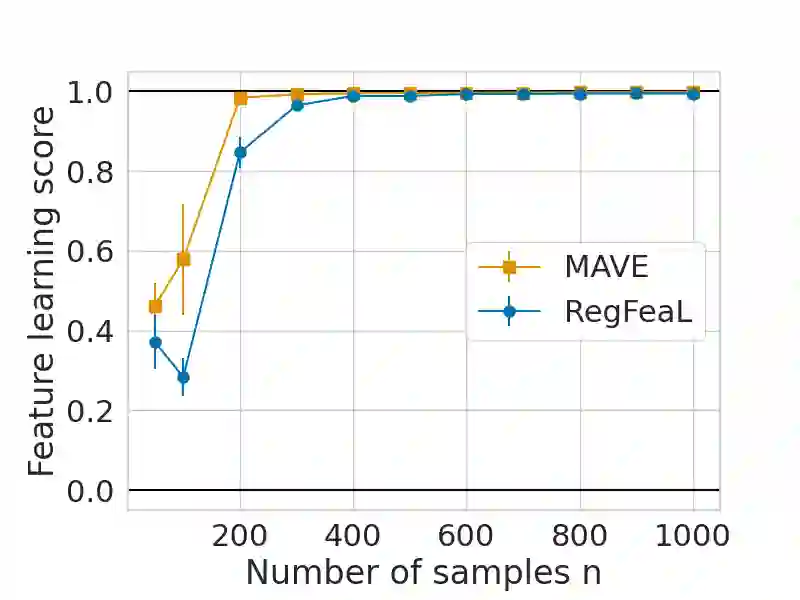
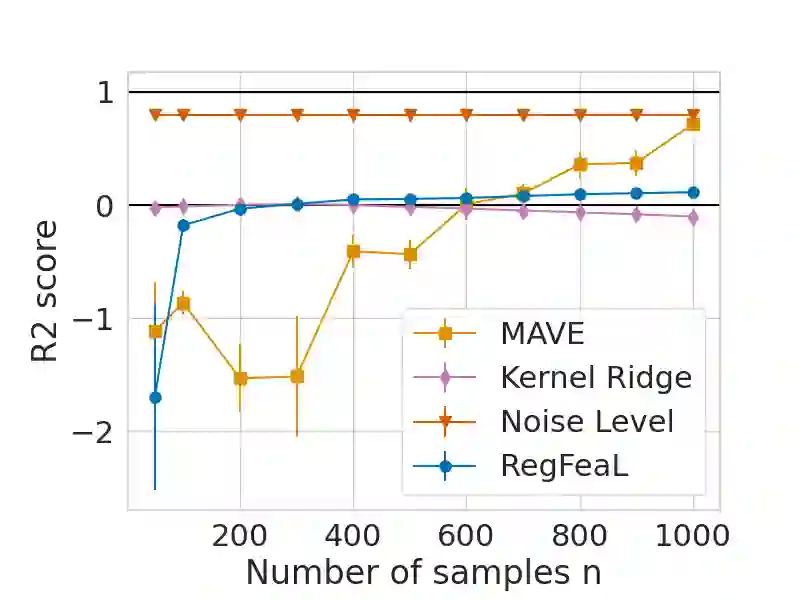
Representation learning plays a crucial role in automated feature selection, particularly in the context of high-dimensional data, where non-parametric methods often struggle. In this study, we focus on supervised learning scenarios where the pertinent information resides within a lower-dimensional linear subspace of the data, namely the multi-index model. If this subspace were known, it would greatly enhance prediction, computation, and interpretation. To address this challenge, we propose a novel method for linear feature learning with non-parametric prediction, which simultaneously estimates the prediction function and the linear subspace. Our approach employs empirical risk minimisation, augmented with a penalty on function derivatives, ensuring versatility. Leveraging the orthogonality and rotation invariance properties of Hermite polynomials, we introduce our estimator, named RegFeaL. By utilising alternative minimisation, we iteratively rotate the data to improve alignment with leading directions and accurately estimate the relevant dimension in practical settings. We establish that our method yields a consistent estimator of the prediction function with explicit rates. Additionally, we provide empirical results demonstrating the performance of RegFeaL in various experiments.
翻译:表示学习在自动化特征选择中起着关键作用,尤其是在高维数据背景下,非参数方法往往难以应对。本研究聚焦于监督学习场景,其中重要信息位于数据的低维线性子空间中,即多指标模型。若该子空间已知,将大幅提升预测精度、计算效率与可解释性。为解决这一挑战,我们提出一种用于非参数预测的线性特征学习新方法,能够同时估计预测函数与线性子空间。该方法采用经验风险最小化,并辅以函数导数的惩罚项,确保其通用性。利用埃尔米特多项式的正交性与旋转不变性,我们引入名为RegFeaL的估计器。通过交替最小化策略,迭代旋转数据以增强与主导方向的匹配,并在实际场景中准确估计相关维度。我们证明该方法能以显式速率得到预测函数的一致估计量。此外,通过多种实验验证了RegFeaL的性能。