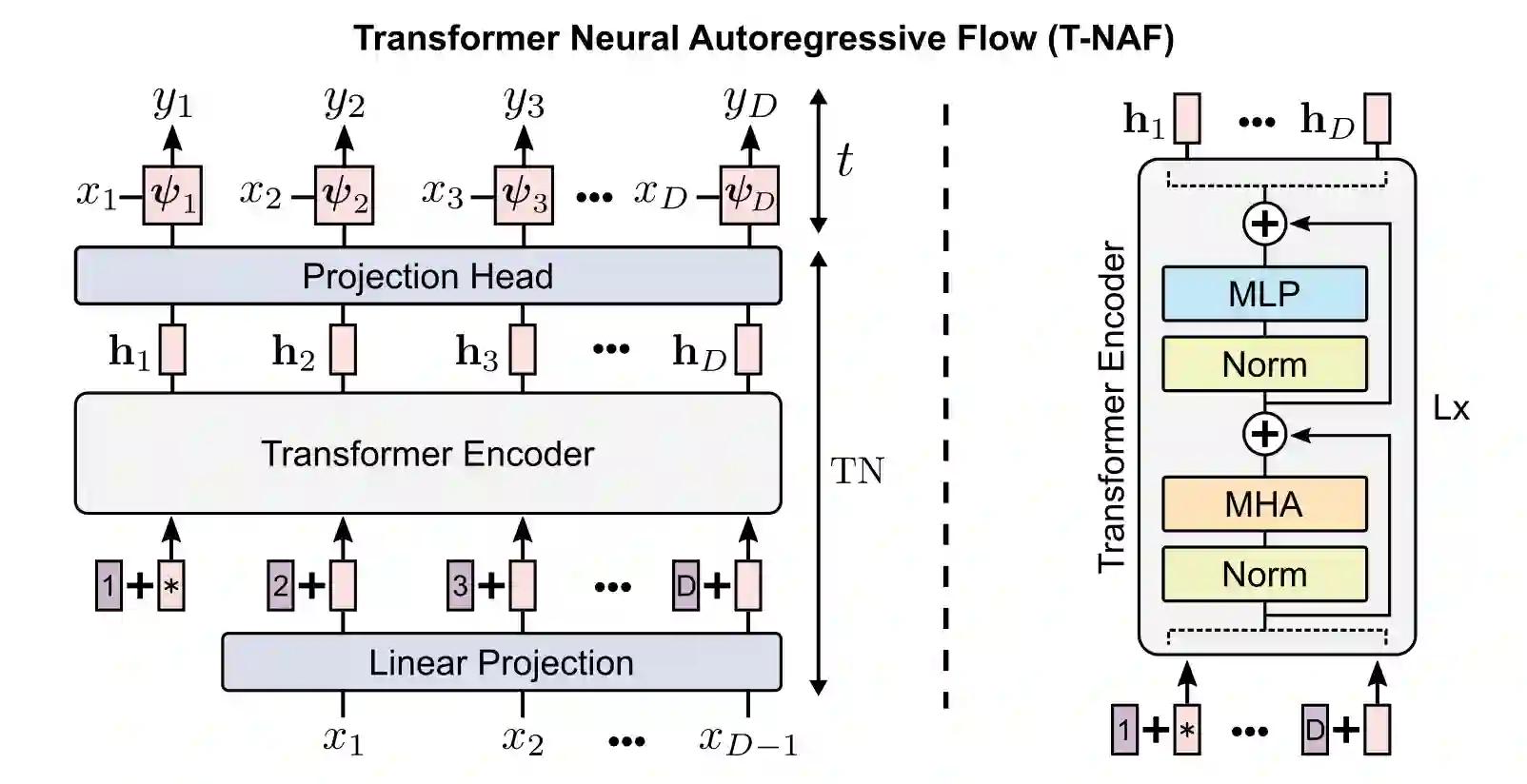
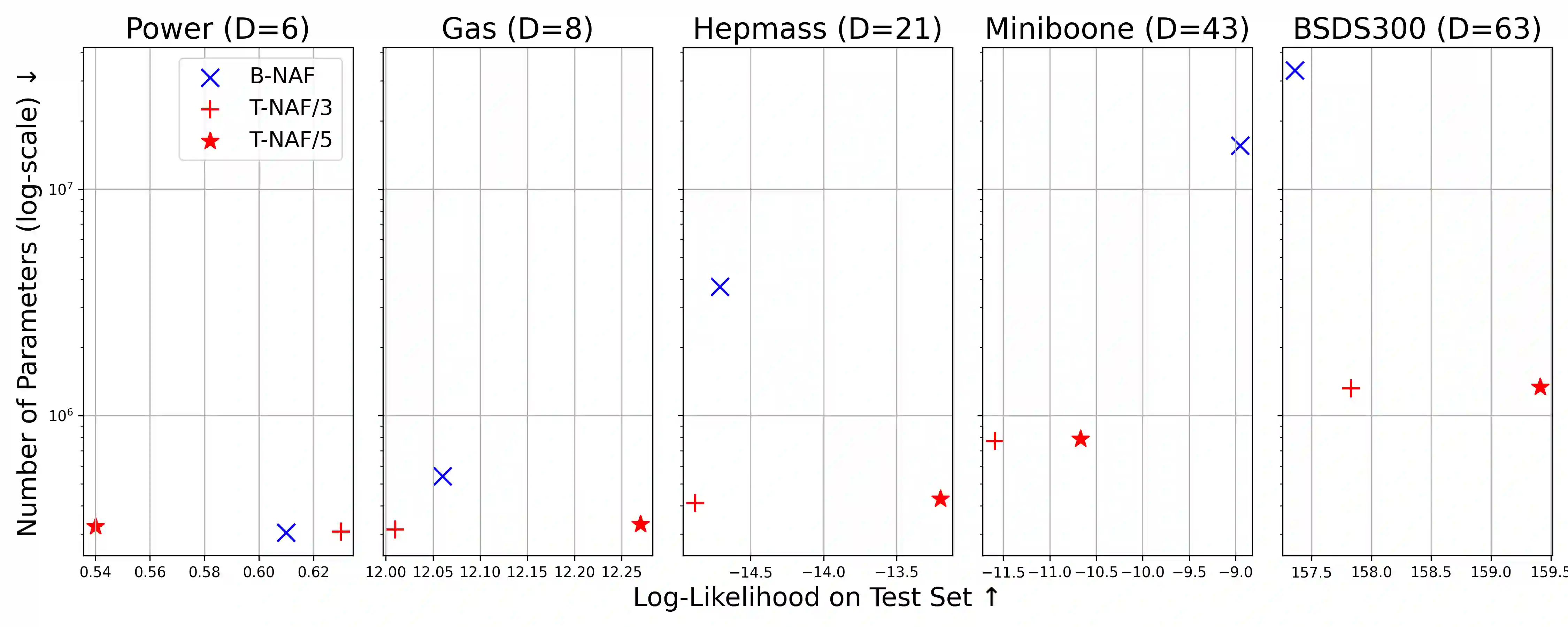
Density estimation, a central problem in machine learning, can be performed using Normalizing Flows (NFs). NFs comprise a sequence of invertible transformations, that turn a complex target distribution into a simple one, by exploiting the change of variables theorem. Neural Autoregressive Flows (NAFs) and Block Neural Autoregressive Flows (B-NAFs) are arguably the most perfomant members of the NF family. However, they suffer scalability issues and training instability due to the constraints imposed on the network structure. In this paper, we propose a novel solution to these challenges by exploiting transformers to define a new class of neural flows called Transformer Neural Autoregressive Flows (T-NAFs). T-NAFs treat each dimension of a random variable as a separate input token, using attention masking to enforce an autoregressive constraint. We take an amortization-inspired approach where the transformer outputs the parameters of an invertible transformation. The experimental results demonstrate that T-NAFs consistently match or outperform NAFs and B-NAFs across multiple datasets from the UCI benchmark. Remarkably, T-NAFs achieve these results using an order of magnitude fewer parameters than previous approaches, without composing multiple flows.
翻译:密度估计是机器学习中的一个核心问题,可通过归一化流实现。归一化流由一系列可逆变换构成,通过利用变量变换定理,将复杂的目标分布转化为简单分布。神经自回归流和块神经自回归流可以说是归一化流家族中性能最优的成员。然而,由于网络结构上的约束,它们存在可扩展性问题和训练不稳定性。本文中,我们提出了一种应对这些挑战的新方案,通过利用Transformer来定义一种新型神经流,称为Transformer神经自回归流。T-NAF将随机变量的每个维度视为独立的输入标记,通过注意力掩码来施加自回归约束。我们采用了一种类似摊销的方法,由Transformer输出可逆变换的参数。实验结果表明,在UCI基准的多个数据集上,T-NAF始终匹配或超越NAF和B-NAF的性能。值得注意的是,T-NAF在实现这些结果时,使用的参数量比以往方法少一个数量级,且无需组合多个流。