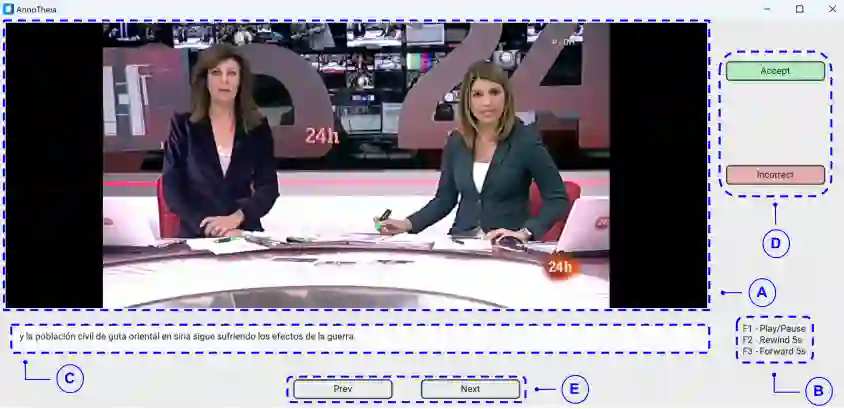
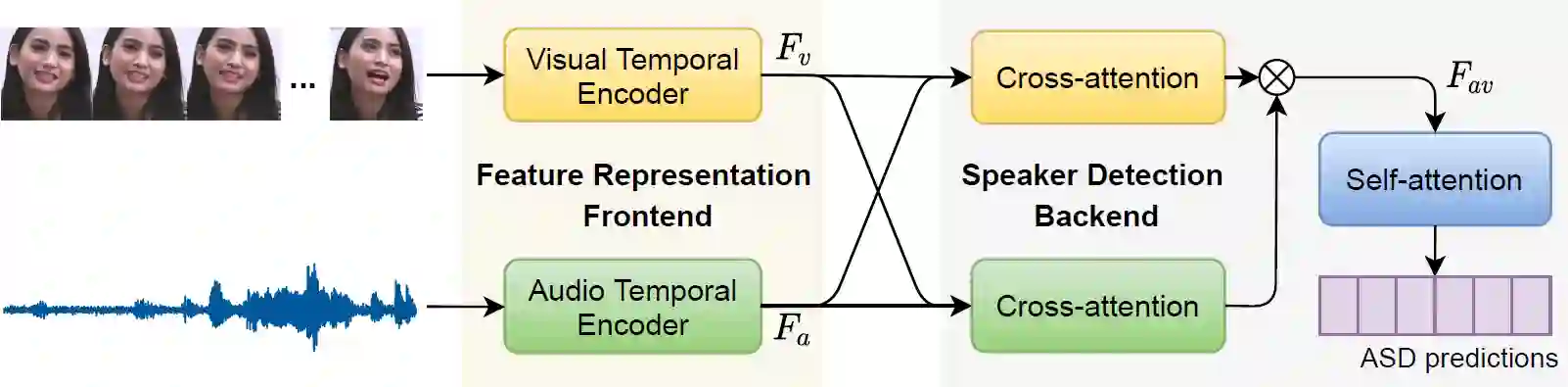
More than 7,000 known languages are spoken around the world. However, due to the lack of annotated resources, only a small fraction of them are currently covered by speech technologies. Albeit self-supervised speech representations, recent massive speech corpora collections, as well as the organization of challenges, have alleviated this inequality, most studies are mainly benchmarked on English. This situation is aggravated when tasks involving both acoustic and visual speech modalities are addressed. In order to promote research on low-resource languages for audio-visual speech technologies, we present AnnoTheia, a semi-automatic annotation toolkit that detects when a person speaks on the scene and the corresponding transcription. In addition, to show the complete process of preparing AnnoTheia for a language of interest, we also describe the adaptation of a pre-trained model for active speaker detection to Spanish, using a database not initially conceived for this type of task. The AnnoTheia toolkit, tutorials, and pre-trained models are available on GitHub.
翻译:全球范围内有超过 7000 种已知语言被使用。然而,由于标注资源的匮乏,目前仅有少数语言能够应用语音技术。尽管自监督语音表征、近期的大规模语音语料库收集以及各类挑战赛的举办在一定程度上缓解了这种不平等现象,但多数研究仍主要以英语为基准。当涉及同时处理声学与视觉语音模态的任务时,这一状况更为严峻。为促进低资源语言在音视频语音技术领域的研究,我们提出了 AnnoTheia——一种半自动标注工具包,能够检测场景中的人物发言时刻并生成相应转录文本。此外,为了展示将 AnnoTheia 适配至目标语言的全流程,我们还描述了如何利用一个非为此类任务设计的数据库,将预训练的主动说话人检测模型适配至西班牙语。AnnoTheia 工具包、教程及预训练模型已在 GitHub 上开源。