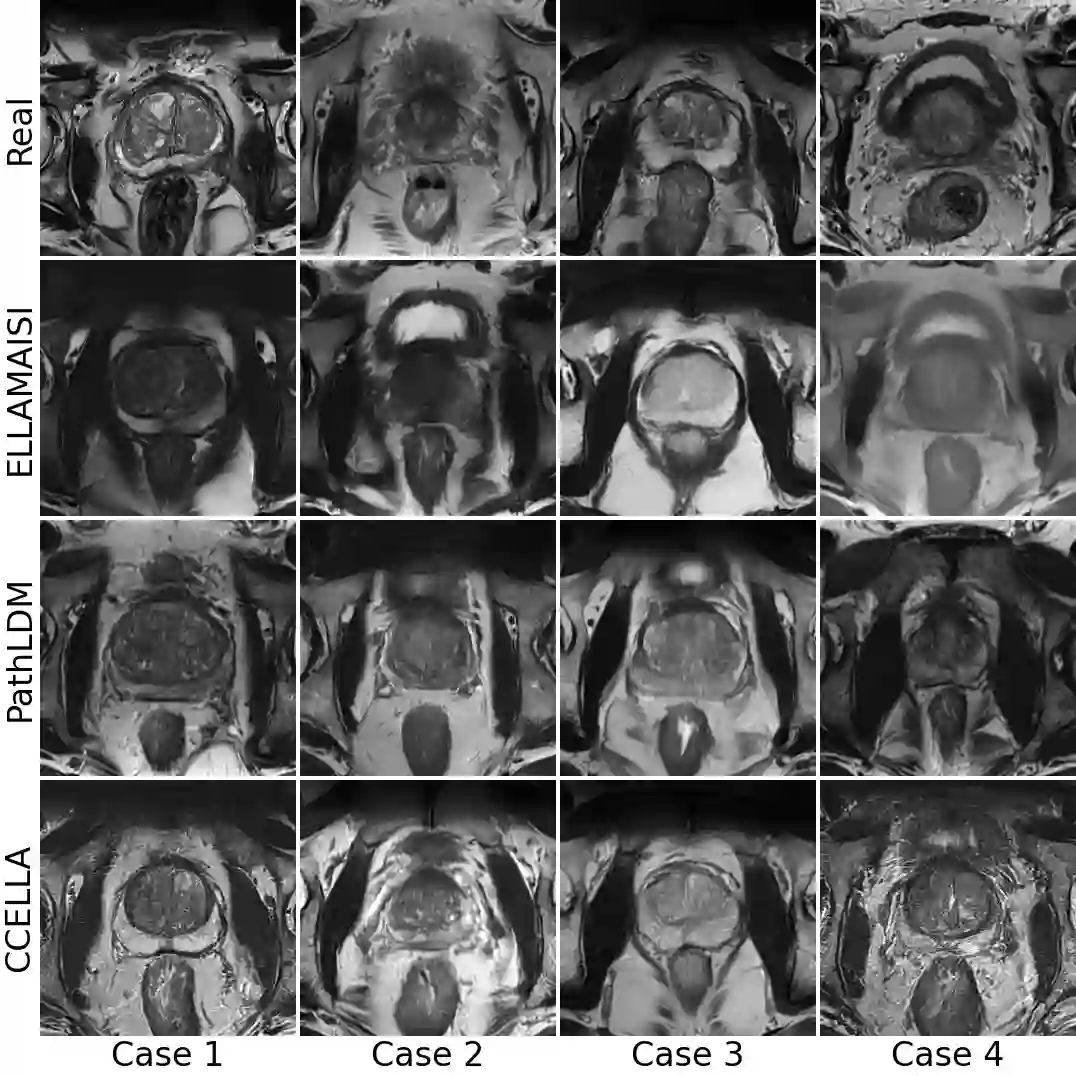
Objective: Latent diffusion models (LDM) could alleviate data scarcity challenges affecting machine learning development for medical imaging. However, medical LDM strategies typically rely on short-prompt text encoders, nonmedical LDMs, or large data volumes. These strategies can limit performance and scientific accessibility. We propose a novel LDM conditioning approach to address these limitations. Methods: We propose Class-Conditioned Efficient Large Language model Adapter (CCELLA), a novel dual-head conditioning approach that simultaneously conditions the LDM U-Net with free-text clinical reports and radiology classification. We also propose a data-efficient LDM pipeline centered around CCELLA and a proposed joint loss function. We first evaluate our method on 3D prostate MRI against state-of-the-art. We then augment a downstream classifier model training dataset with synthetic images from our method. Results: Our method achieves a 3D FID score of 0.025 on a size-limited 3D prostate MRI dataset, significantly outperforming a recent foundation model with FID 0.070. When training a classifier for prostate cancer prediction, adding synthetic images generated by our method during training improves classifier accuracy from 69% to 74% and outperforms classifiers trained on images generated by prior state-of-the-art. Classifier training solely on our method's synthetic images achieved comparable performance to real image training. Conclusion: We show that our method improved both synthetic image quality and downstream classifier performance using limited data and minimal human annotation. Significance: The proposed CCELLA-centric pipeline enables radiology report and class-conditioned LDM training for high-quality medical image synthesis given limited data volume and human data annotation, improving LDM performance and scientific accessibility.
翻译:目的:潜在扩散模型(LDM)可缓解医学影像机器学习开发中面临的数据稀缺挑战。然而,医学LDM策略通常依赖短提示文本编码器、非医学LDM或大规模数据量。这些策略可能限制性能与科学可及性。我们提出一种新颖的LDM条件调节方法以应对这些局限。方法:我们提出类别条件高效大语言模型适配器(CCELLA),这是一种新颖的双头条件调节方法,可同时利用自由文本临床报告与放射学分类对LDM U-Net进行条件调节。我们还提出一个以CCELLA为核心的数据高效LDM流程及联合损失函数。我们首先在三维前列腺MRI数据上评估本方法并与前沿技术对比。随后使用本方法生成的合成图像扩增下游分类器模型的训练数据集。结果:在规模受限的三维前列腺MRI数据集上,本方法获得0.025的3D FID分数,显著优于近期基础模型的0.070 FID分数。在前列腺癌预测分类器训练中,加入本方法生成的合成图像使分类器准确率从69%提升至74%,且优于基于先前前沿技术生成图像训练的分类器。仅使用本方法合成图像训练的分类器取得了与真实图像训练相当的性能。结论:我们证明本方法在有限数据和最小人工标注条件下,同时提升了合成图像质量与下游分类器性能。意义:所提出的以CCELLA为核心的流程,能够在有限数据量和人工标注条件下,实现基于放射学报告与类别条件调节的LDM训练,用于高质量医学图像合成,从而提升LDM性能与科学可及性。