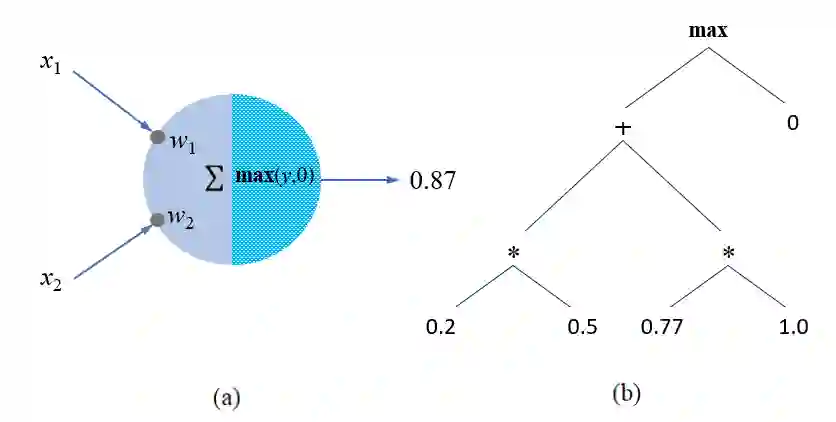
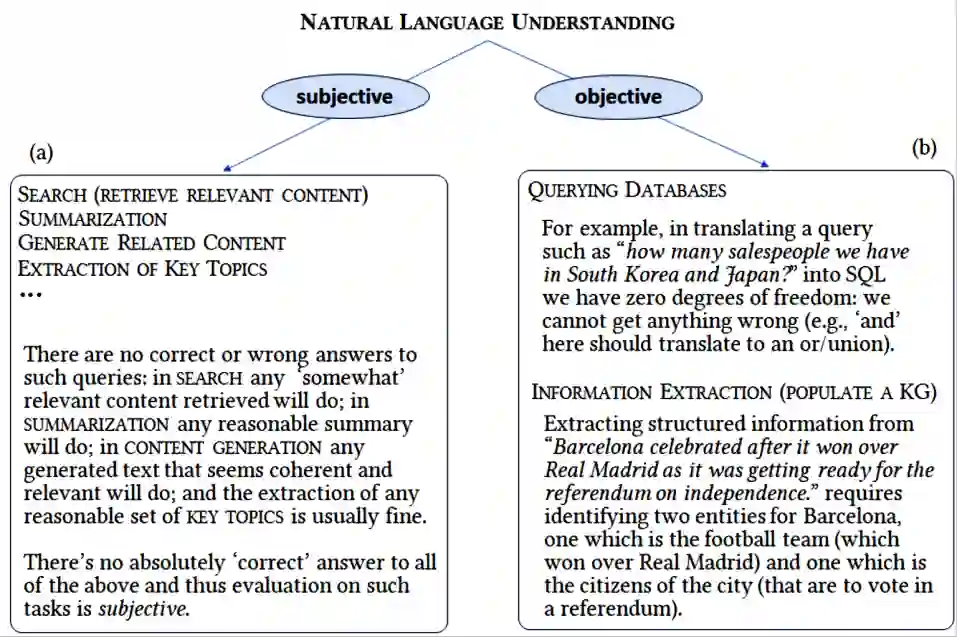
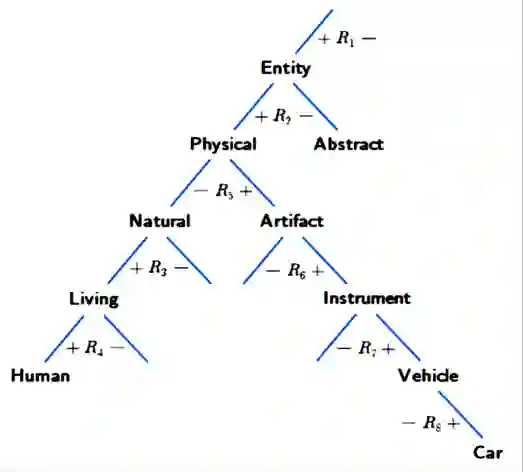
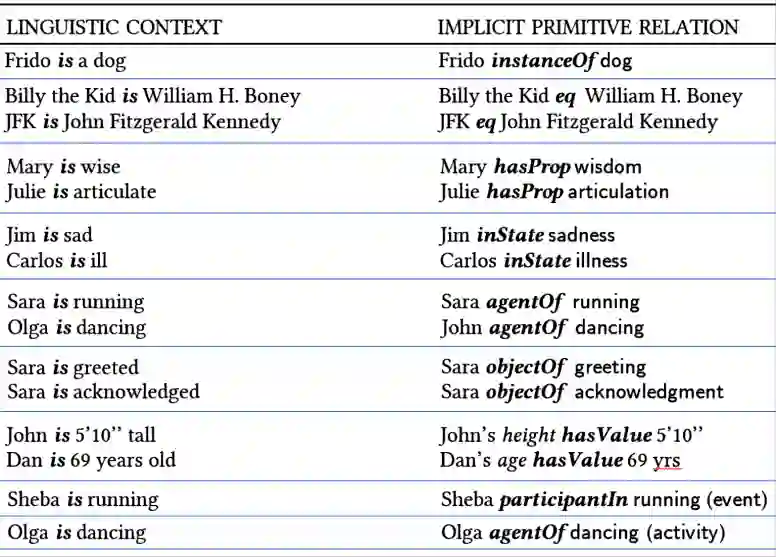
In our opinion the exuberance surrounding the relative success of data-driven large language models (LLMs) is slightly misguided and for several reasons (i) LLMs cannot be relied upon for factual information since for LLMs all ingested text (factual or non-factual) was created equal; (ii) due to their subsymbolic na-ture, whatever 'knowledge' these models acquire about language will always be buried in billions of microfeatures (weights), none of which is meaningful on its own; and (iii) LLMs will often fail to make the correct inferences in several linguistic contexts (e.g., nominal compounds, copredication, quantifier scope ambi-guities, intensional contexts. Since we believe the relative success of data-driven large language models (LLMs) is not a reflection on the symbolic vs. subsymbol-ic debate but a reflection on applying the successful strategy of a bottom-up reverse engineering of language at scale, we suggest in this paper applying the effective bottom-up strategy in a symbolic setting resulting in symbolic, explainable, and ontologically grounded language models.
翻译:我们认为,围绕数据驱动型大语言模型相对成功的狂热情绪略有失当,原因如下:(一)大语言模型无法被依赖来提供事实信息,因为对于它们而言,所有摄入的文本(事实性或非事实性)都是平等的;(二)由于其亚符号特性,这些模型获取的有关语言的任何“知识”都将永远埋藏在数十亿个微特征(权重)之中,而没有任何一个微特征本身具有意义;(三)大语言模型往往在多种语境中无法做出正确推理(例如名词复合词、共谓结构、量化词辖域歧义、内涵语境)。我们认为数据驱动型大语言模型的相对成功并非反映符号与亚符号之争,而是反映了大规模自下而上逆向工程语言这一成功策略的应用。因此本文建议在符号框架下应用这种有效的自下而上策略,从而构建符号化、可解释且基于本体的语言模型。