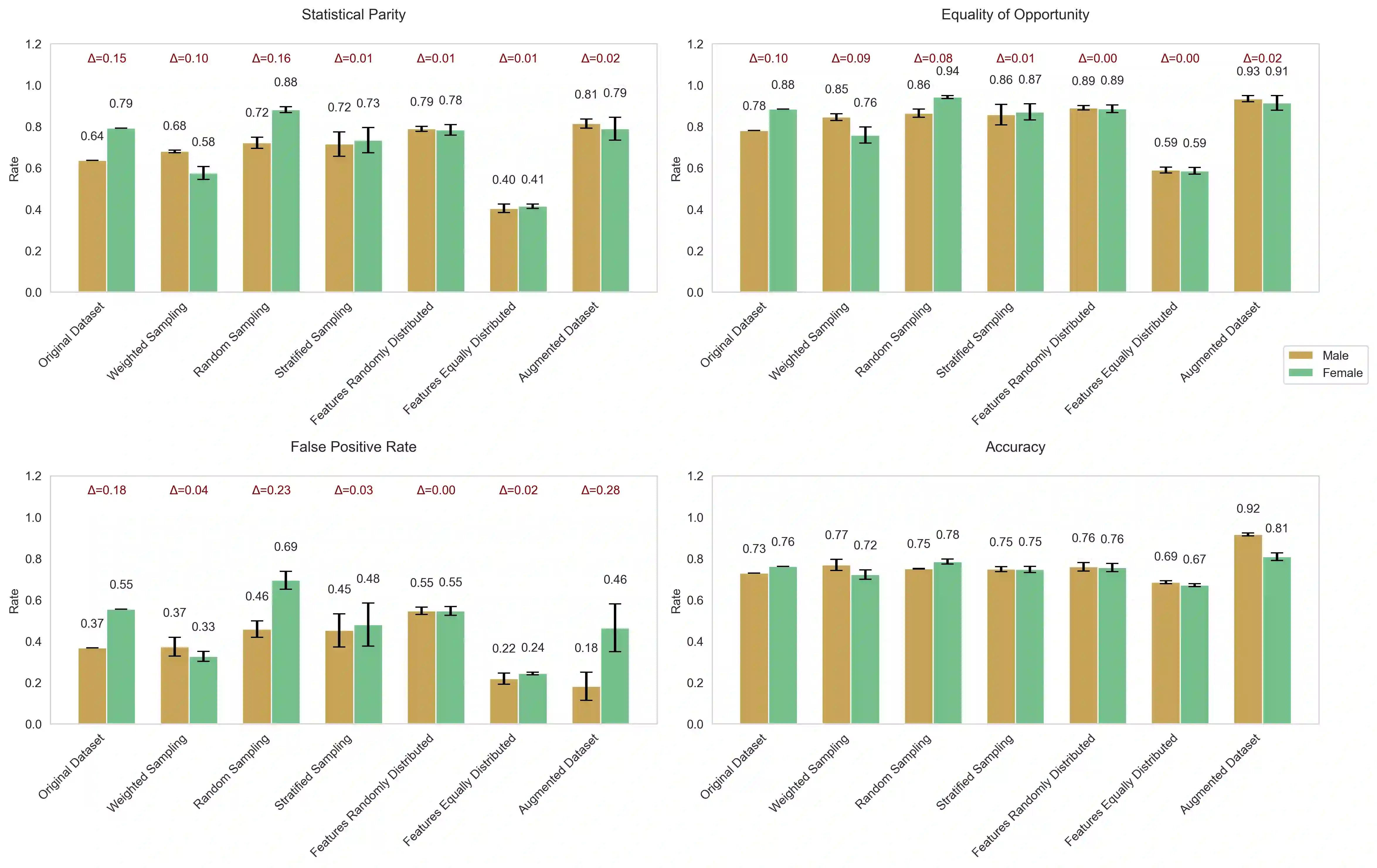
This paper examines the critical role of Graph Neural Networks (GNNs) in data preparation for generative artificial intelligence (GenAI) systems, with a particular focus on addressing and mitigating biases. We present a comparative analysis of three distinct methods for bias mitigation: data sparsification, feature modification, and synthetic data augmentation. Through experimental analysis using the german credit dataset, we evaluate these approaches using multiple fairness metrics, including statistical parity, equality of opportunity, and false positive rates. Our research demonstrates that while all methods improve fairness metrics compared to the original dataset, stratified sampling and synthetic data augmentation using GraphSAGE prove particularly effective in balancing demographic representation while maintaining model performance. The results provide practical insights for developing more equitable AI systems while maintaining model performance.
翻译:本文探讨了图神经网络(GNNs)在生成式人工智能(GenAI)系统数据准备中的关键作用,特别聚焦于识别与缓解偏见问题。我们针对三种不同的偏见缓解方法进行了比较分析:数据稀疏化、特征修改以及合成数据增强。通过使用德国信贷数据集进行实验分析,我们采用多种公平性指标(包括统计奇偶性、机会均等性和假阳性率)对这些方法进行了评估。研究表明,尽管所有方法相较于原始数据集均能提升公平性指标,但分层抽样以及基于GraphSAGE的合成数据增强方法在保持模型性能的同时,能特别有效地平衡人口统计表征。该结果为开发更公平且保持性能的人工智能系统提供了实践启示。