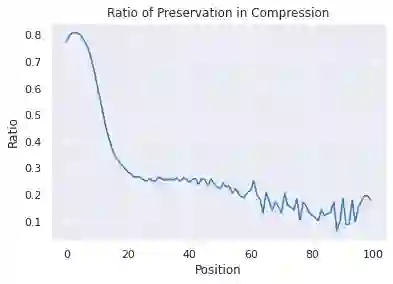
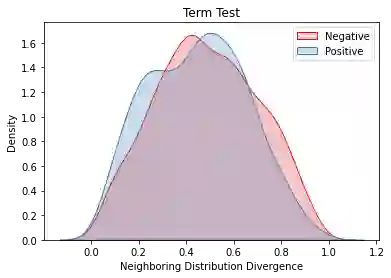
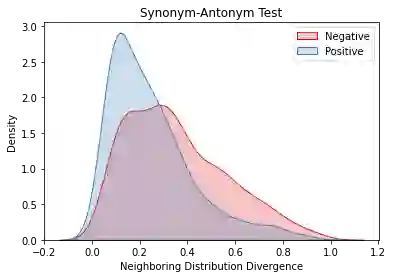
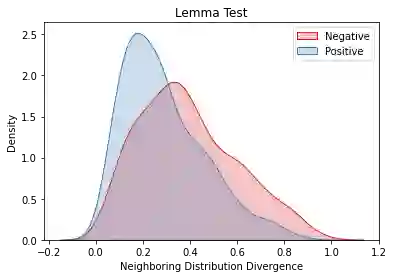
Overlapping frequently occurs in paired texts in natural language processing tasks like text editing and semantic similarity evaluation. Better evaluation of the semantic distance between the overlapped sentences benefits the language system's understanding and guides the generation. Since conventional semantic metrics are based on word representations, they are vulnerable to the disturbance of overlapped components with similar representations. This paper aims to address the issue with a mask-and-predict strategy. We take the words in the longest common sequence (LCS) as neighboring words and use masked language modeling (MLM) from pre-trained language models (PLMs) to predict the distributions on their positions. Our metric, Neighboring Distribution Divergence (NDD), represent the semantic distance by calculating the divergence between distributions in the overlapped parts. Experiments on Semantic Textual Similarity show NDD to be more sensitive to various semantic differences, especially on highly overlapped paired texts. Based on the discovery, we further implement an unsupervised and training-free method for text compression, leading to a significant improvement on the previous perplexity-based method. The high scalability of our method even enables NDD to outperform the supervised state-of-the-art in domain adaption by a huge margin. Further experiments on syntax and semantics analyses verify the awareness of internal sentence structures, indicating the high potential of NDD for further studies.
翻译:在自然语言处理任务(如文本编辑和语义相似度评估)中,配对文本常出现高度重叠现象。更准确地评估重叠句子间的语义距离,有助于提升语言系统的理解能力并指导文本生成。由于传统语义指标基于词汇表示,它们易受具有相似表示的重叠成分干扰。本文旨在通过掩码-预测策略解决该问题。我们将最长公共子序列中的词汇视为邻接词汇,并利用预训练语言模型的掩码语言建模来预测这些位置上的分布。本文提出的邻接分布散度指标通过计算重叠部分分布的散度来表征语义距离。语义文本相似度实验表明,NDD对多种语义差异更为敏感,尤其在高度重叠的配对文本中表现突出。基于这一发现,我们进一步实现了一种无监督且无需训练的文本压缩方法,相较于先前基于困惑度的方法取得了显著改进。该方法的高可扩展性甚至使NDD在领域自适应任务中大幅超越有监督最先进方法。关于句法与语义分析的进一步实验验证了NDD对句子内部结构的感知能力,彰显了其在后续研究中的巨大潜力。