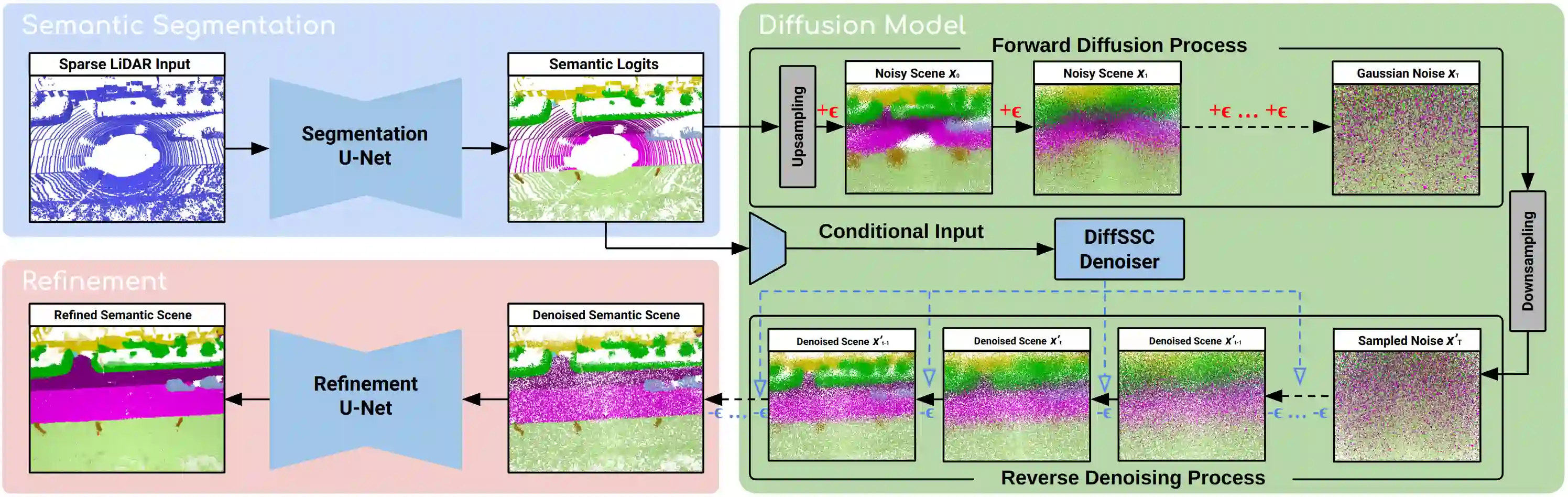
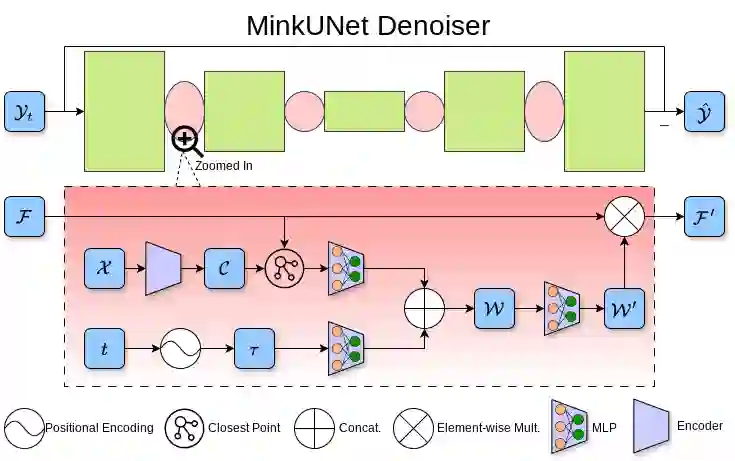
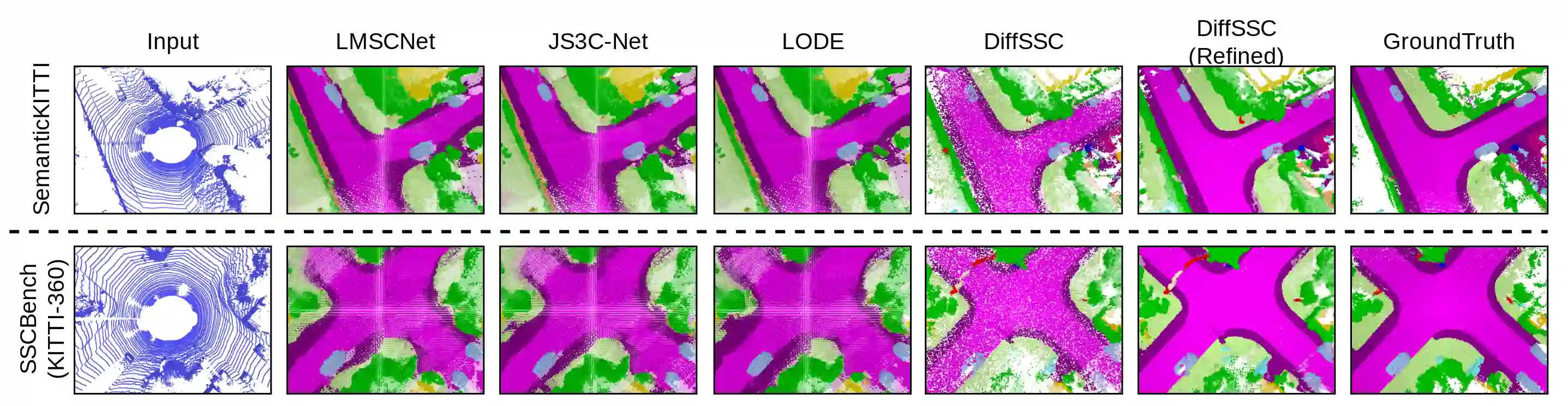
Perception systems play a crucial role in autonomous driving, incorporating multiple sensors and corresponding computer vision algorithms. 3D LiDAR sensors are widely used to capture sparse point clouds of the vehicle's surroundings. However, such systems struggle to perceive occluded areas and gaps in the scene due to the sparsity of these point clouds and their lack of semantics. To address these challenges, Semantic Scene Completion (SSC) jointly predicts unobserved geometry and semantics in the scene given raw LiDAR measurements, aiming for a more complete scene representation. Building on promising results of diffusion models in image generation and super-resolution tasks, we propose their extension to SSC by implementing the noising and denoising diffusion processes in the point and semantic spaces individually. To control the generation, we employ semantic LiDAR point clouds as conditional input and design local and global regularization losses to stabilize the denoising process. We evaluate our approach on autonomous driving datasets and our approach outperforms the state-of-the-art for SSC.
翻译:感知系统在自动驾驶中扮演着关键角色,其整合了多种传感器及相应的计算机视觉算法。三维激光雷达传感器被广泛用于捕获车辆周围环境的稀疏点云。然而,由于点云的稀疏性及其缺乏语义信息,此类系统难以感知场景中被遮挡的区域和间隙。为应对这些挑战,语义场景补全(SSC)任务旨在给定原始激光雷达测量的条件下,联合预测场景中未被观测到的几何结构与语义信息,以获得更完整的场景表征。基于扩散模型在图像生成与超分辨率任务中展现出的优异成果,我们将其扩展应用于SSC任务,具体通过在点空间与语义空间中分别实现噪声添加与去噪的扩散过程。为控制生成过程,我们采用语义激光雷达点云作为条件输入,并设计了局部与全局正则化损失以稳定去噪过程。我们在自动驾驶数据集上评估了所提方法,结果表明其性能优于当前最先进的SSC方法。