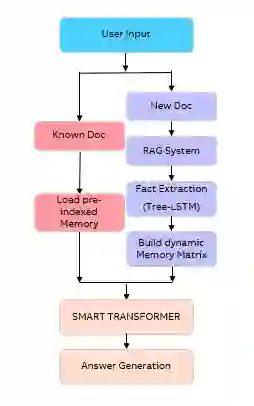
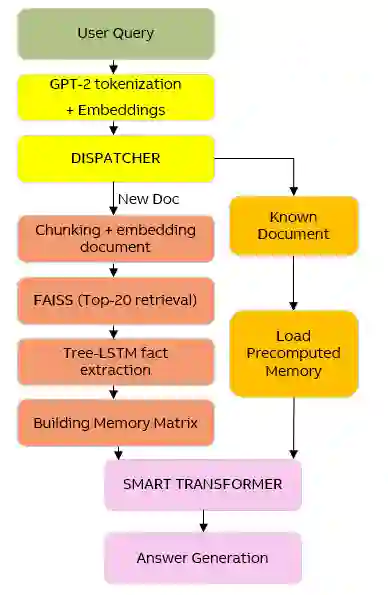
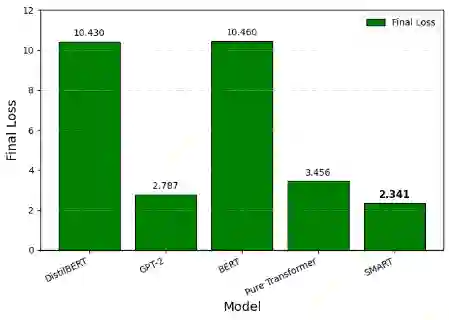
The user of Engineering Manuals (EM) finds it difficult to read EM s because they are long, have a dense format which includes written documents, step by step procedures, and standard parameter lists for engineering equipment. Off the shelf transformers, especially compact ones, treat this material as a flat stream of tokens. This approach leads to confident but incorrect numeric answers and forces the models to memorize separate facts inefficiently. SMART (Structured Memory and Reasoning Transformer) offers a different and practical solution to the above problem. SMART structures its processing by using a hierarchical approach, and is based upon three main job categories (1) A syntax-aware Fact Extractor (Grammarian) Tree LSTM which extracts facts as subject relation object relations from EM sentences (2) A compact indexed memory MANN (Memory Augmented Neural Network) that indexes these Rational Subject Relation Objects as 384 dimensional vectors that are associated with the source of the information, and (3) A 6 layer Transformer that learns to fuse the previously retrieved facts into its generated response. The entire SMART model utilizes 45.51M parameters, which is 64% less than GPT-2 (124M) and 69% less than BERT (133M), and it achieves a 21.3% higher accuracy than GPT-2, indicating that SMART fits the data better with the least amount of processing requirements. SMART employs dual modes of inference an indexed fast path for known documents (sub-second answer times) and an indexed dynamic path assisted by RAGs for new uploads (FAISS Top 20 results with memory severed at 64 slots). In real world deployment, this framework leads to more well supported results with reduced hallucinations than comparable small transformer models.
翻译:工程手册(EM)用户发现阅读EM存在困难,因为其篇幅冗长、格式密集,包含书面文档、分步操作流程以及工程设备的标准参数列表。现成的Transformer模型(尤其是紧凑型)将此类材料视为扁平的令牌流进行处理。这种方法会导致模型产生自信但错误的数值答案,并迫使其低效地记忆分散的事实。SMART(结构化记忆与推理Transformer)为此问题提供了一种创新且实用的解决方案。SMART采用分层处理架构,其核心基于三大功能模块:(1)语法感知的事实提取器(语法学家)——基于Tree LSTM从EM语句中提取主谓宾关系的事实三元组;(2)紧凑型索引记忆模块——通过记忆增强神经网络(MANN)将这些理性主谓宾关系索引为384维向量,并与信息来源关联;(3)6层Transformer模块——学习将检索到的事实融合至生成响应中。整个SMART模型仅包含45.51M参数,较GPT-2(124M)减少64%,较BERT(133M)减少69%,同时其准确率比GPT-2提升21.3%,表明SMART能以最低计算成本实现更优的数据拟合。SMART采用双模式推理机制:针对已知文档的索引快速路径(亚秒级响应)和针对新上传文档的索引动态路径(通过检索增强生成技术辅助,采用FAISS Top 20检索结果并设置64槽记忆截断)。在实际部署中,该框架相较于同类小型Transformer模型,能够生成更具支撑性的结果并显著减少幻觉现象。