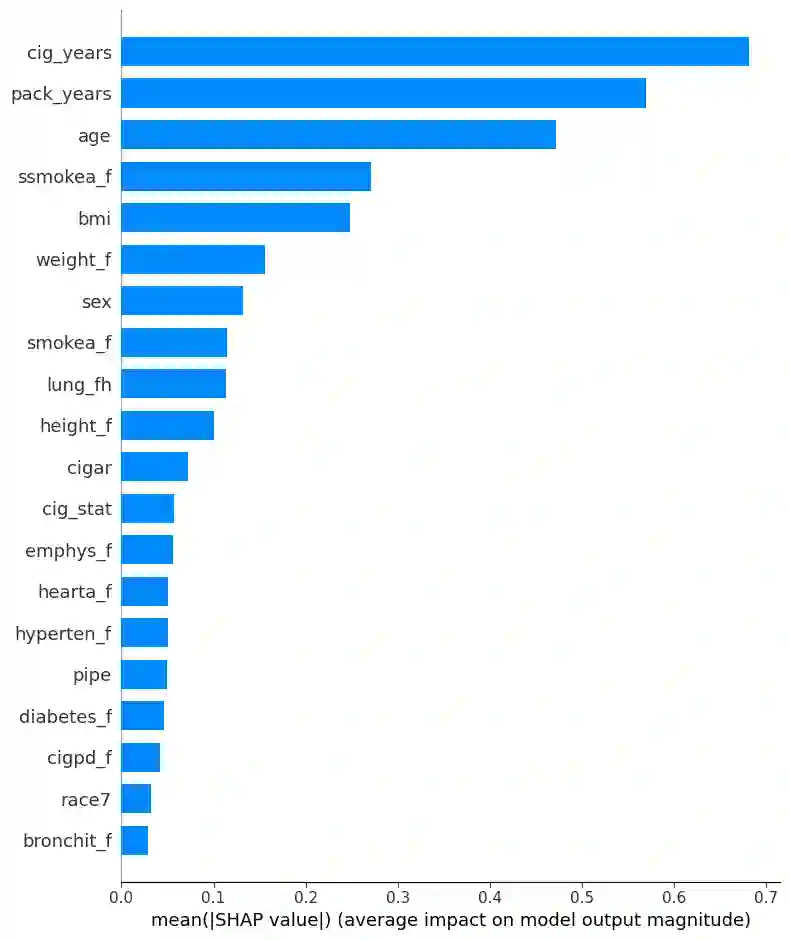
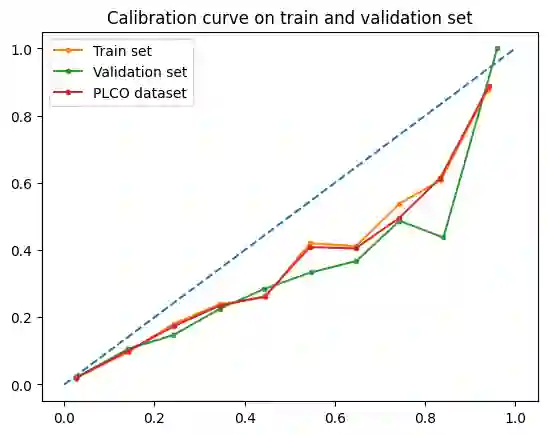
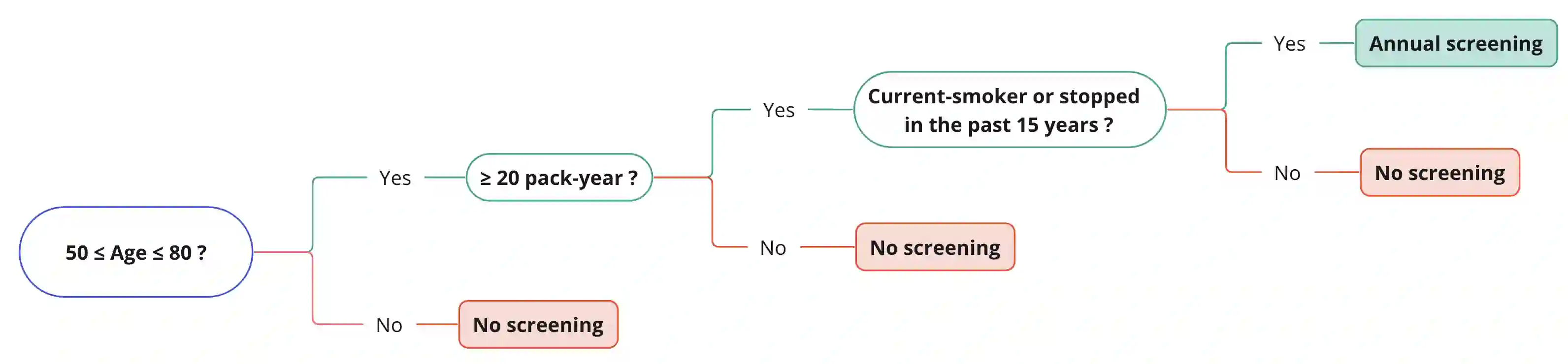
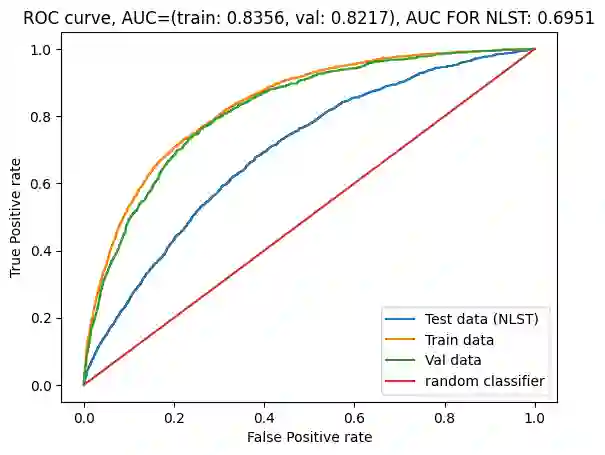
Lung cancer is a significant cause of mortality worldwide, emphasizing the importance of early detection for improved survival rates. In this study, we propose a machine learning (ML) tool trained on data from the PLCO Cancer Screening Trial and validated on the NLST to estimate the likelihood of lung cancer occurrence within five years. The study utilized two datasets, the PLCO (n=55,161) and NLST (n=48,595), consisting of comprehensive information on risk factors, clinical measurements, and outcomes related to lung cancer. Data preprocessing involved removing patients who were not current or former smokers and those who had died of causes unrelated to lung cancer. Additionally, a focus was placed on mitigating bias caused by censored data. Feature selection, hyper-parameter optimization, and model calibration were performed using XGBoost, an ensemble learning algorithm that combines gradient boosting and decision trees. The ML model was trained on the pre-processed PLCO dataset and tested on the NLST dataset. The model incorporated features such as age, gender, smoking history, medical diagnoses, and family history of lung cancer. The model was well-calibrated (Brier score=0.044). ROC-AUC was 82% on the PLCO dataset and 70% on the NLST dataset. PR-AUC was 29% and 11% respectively. When compared to the USPSTF guidelines for lung cancer screening, our model provided the same recall with a precision of 13.1% vs. 9.3% on the PLCO dataset and 3.2% vs. 3.1% on the NLST dataset. The developed ML tool provides a freely available web application for estimating the likelihood of developing lung cancer within five years. By utilizing risk factors and clinical data, individuals can assess their risk and make informed decisions regarding lung cancer screening. This research contributes to the efforts in early detection and prevention strategies, aiming to reduce lung cancer-related mortality rates.
翻译:肺癌是全球范围内导致死亡的主要原因,凸显了早期检测对提高生存率的重要性。本研究提出一种机器学习(ML)工具,该工具基于PLCO癌症筛查试验数据进行训练,并在NLST数据集上验证,用于估算五年内肺癌发生概率。研究采用两个数据集:PLCO(n=55,161)和NLST(n=48,595),包含全面的风险因素、临床测量指标及肺癌相关结局信息。数据预处理阶段排除了非当前或既往吸烟者,以及因非肺癌原因死亡的患者,并重点减轻了删失数据带来的偏差。特征选择、超参数优化及模型校准均使用XGBoost(一种结合梯度提升与决策树的集成学习算法)。ML模型在预处理后的PLCO数据集上训练,并在NLST数据集上测试。模型纳入年龄、性别、吸烟史、医疗诊断及肺癌家族史等特征。模型校准效果良好(Brier评分=0.044)。PLCO数据集的ROC-AUC为82%,NLST数据集为70%;PR-AUC分别为29%和11%。与美国预防服务工作组(USPSTF)肺癌筛查指南相比,本模型在PLCO数据集上召回率相同时精确度为13.1% vs. 9.3%,在NLST数据集上为3.2% vs. 3.1%。所开发的ML工具提供免费网络应用程序,用于估算五年内患肺癌风险。通过利用风险因素与临床数据,个体可评估自身风险并做出知情筛查决策。本研究致力于推动早期检测与预防策略,旨在降低肺癌相关死亡率。