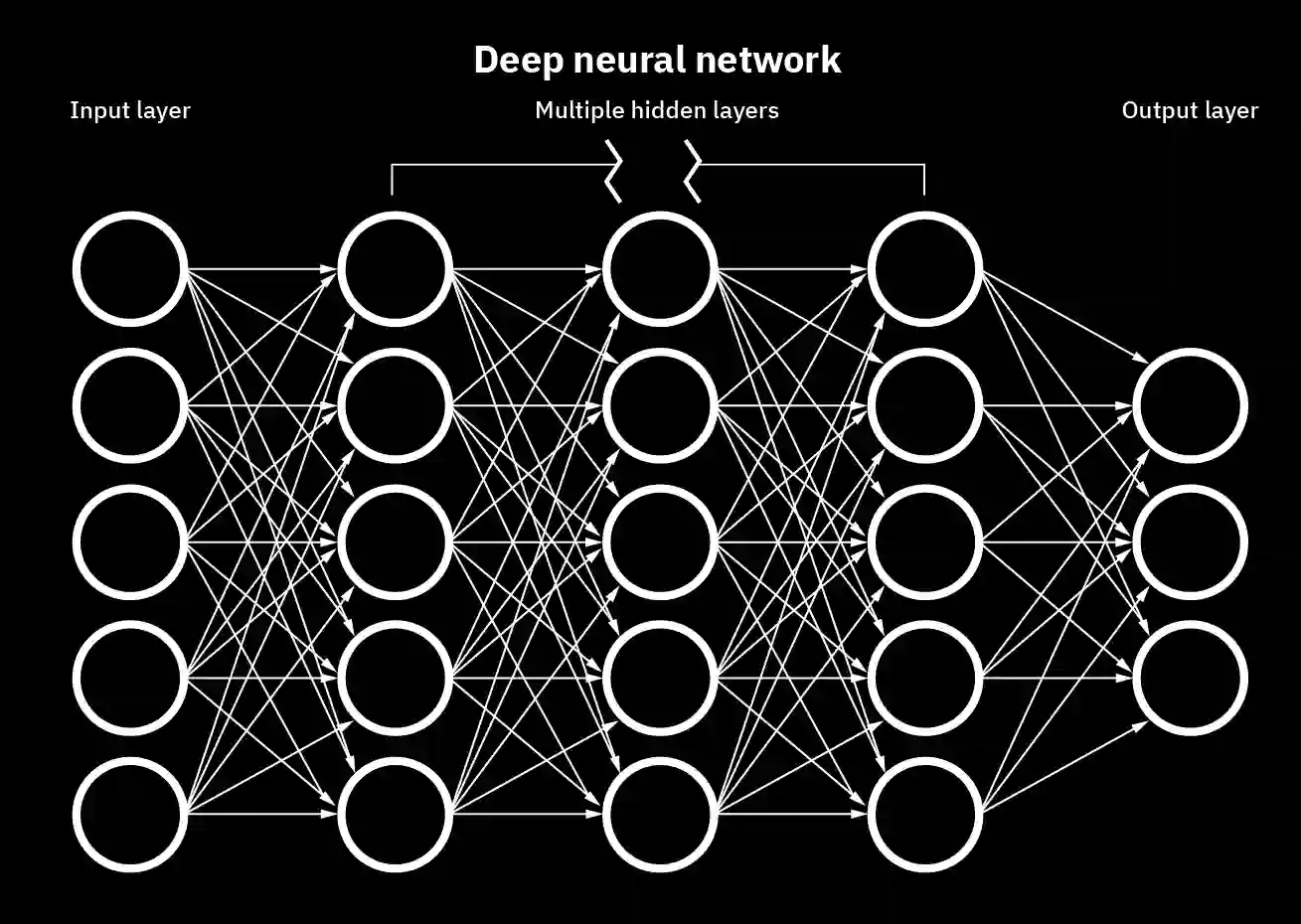
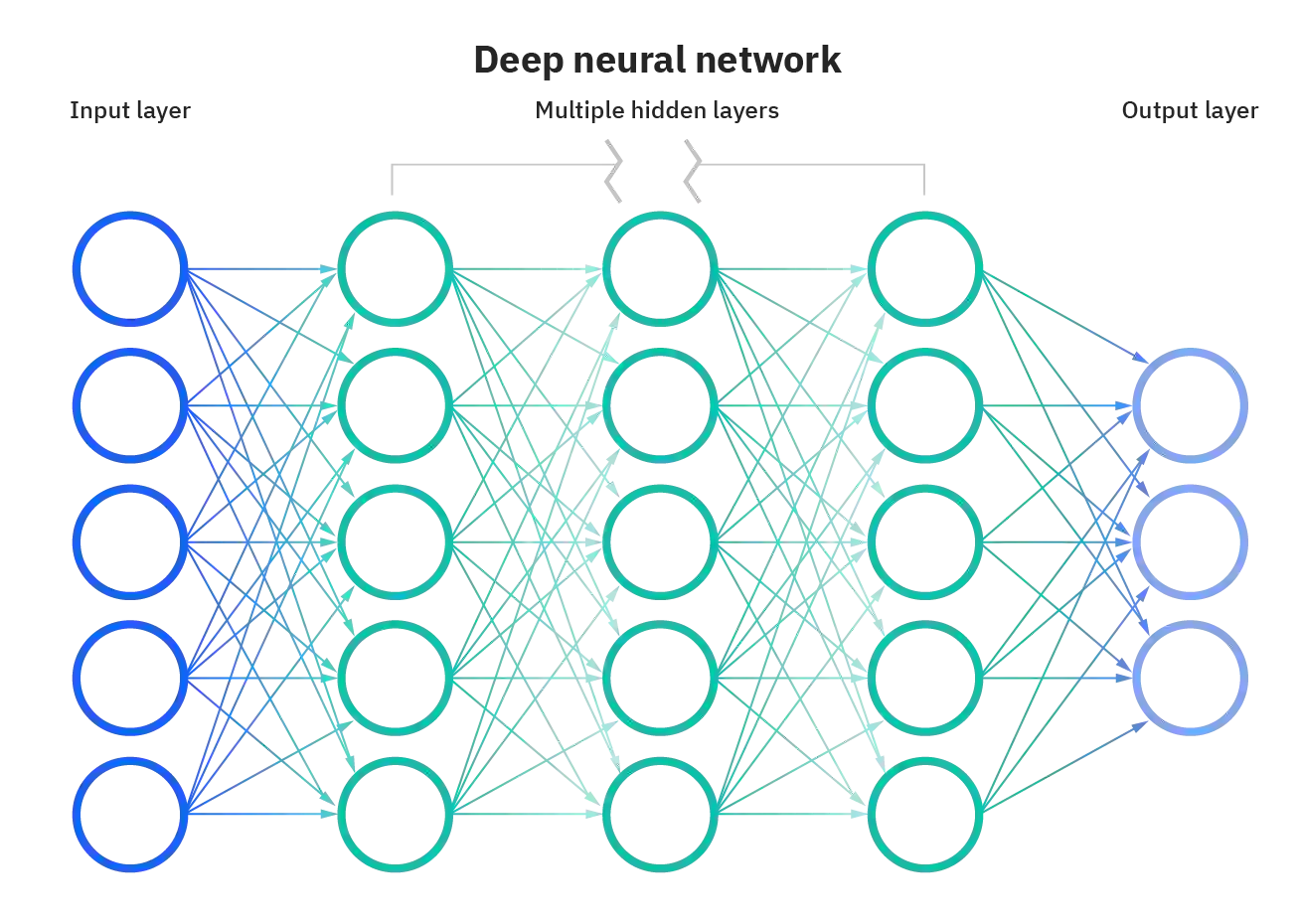
We introduce SymbolicAI, a versatile and modular framework employing a logic-based approach to concept learning and flow management in generative processes. SymbolicAI enables the seamless integration of generative models with a diverse range of solvers by treating large language models (LLMs) as semantic parsers that execute tasks based on both natural and formal language instructions, thus bridging the gap between symbolic reasoning and generative AI. We leverage probabilistic programming principles to tackle complex tasks, and utilize differentiable and classical programming paradigms with their respective strengths. The framework introduces a set of polymorphic, compositional, and self-referential operations for data stream manipulation, aligning LLM outputs with user objectives. As a result, we can transition between the capabilities of various foundation models endowed with zero- and few-shot learning capabilities and specialized, fine-tuned models or solvers proficient in addressing specific problems. In turn, the framework facilitates the creation and evaluation of explainable computational graphs. We conclude by introducing a quality measure and its empirical score for evaluating these computational graphs, and propose a benchmark that compares various state-of-the-art LLMs across a set of complex workflows. We refer to the empirical score as the "Vector Embedding for Relational Trajectory Evaluation through Cross-similarity", or VERTEX score for short. The framework codebase and benchmark are linked below.
翻译:我们提出SymbolicAI——一种通用且模块化的框架,采用基于逻辑的方法实现生成过程中的概念学习与流程管理。该框架通过将大型语言模型(LLM)视为语义解析器,使其既能基于自然语言指令也能基于形式语言指令执行任务,从而弥合符号推理与生成式AI之间的鸿沟,实现生成模型与多种求解器的无缝集成。我们利用概率编程原理处理复杂任务,并融合可微编程与经典编程范式的各自优势。该框架引入一组多态、组合且自指的操作用于数据流操控,使LLM输出与用户目标保持一致。由此,我们能够在具备零样本与小样本学习能力的基础模型与擅长解决特定问题的专用微调模型或求解器之间灵活切换能力。框架进而支持可解释计算图的构建与评估。最后,我们提出一种用于评估这些计算图的质量指标及其经验评分,并构建基准测试集以跨复杂工作流比较多种前沿LLM的性能。该经验评分称为"基于交叉相似度的关系轨迹评估向量嵌入"(Vector Embedding for Relational Trajectory Evaluation through Cross-similarity),简称VERTEX分数。框架代码库与基准测试链接附后。