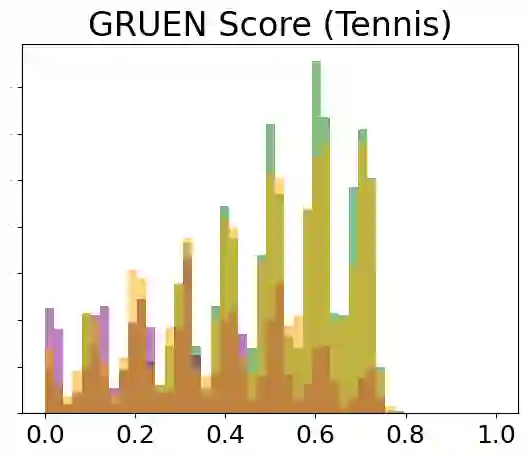
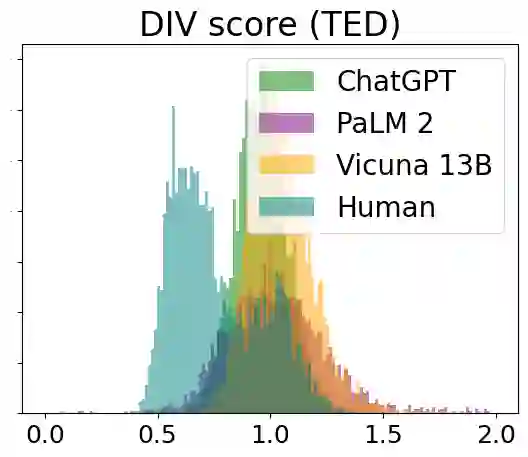
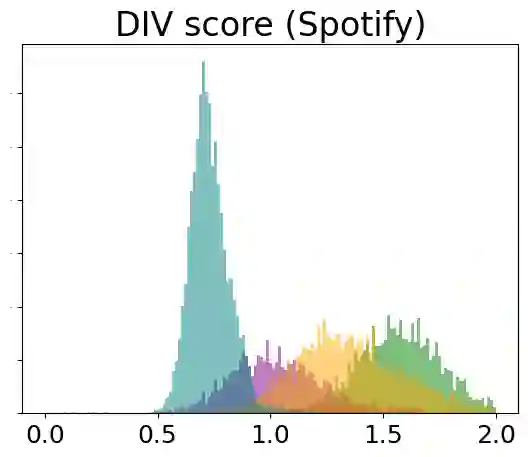
Authorship Analysis, also known as stylometry, has been an essential aspect of Natural Language Processing (NLP) for a long time. Likewise, the recent advancement of Large Language Models (LLMs) has made authorship analysis increasingly crucial for distinguishing between human-written and AI-generated texts. However, these authorship analysis tasks have primarily been focused on written texts, not considering spoken texts. Thus, we introduce the largest benchmark for spoken texts - HANSEN (Human ANd ai Spoken tExt beNchmark). HANSEN encompasses meticulous curation of existing speech datasets accompanied by transcripts, alongside the creation of novel AI-generated spoken text datasets. Together, it comprises 17 human datasets, and AI-generated spoken texts created using 3 prominent LLMs: ChatGPT, PaLM2, and Vicuna13B. To evaluate and demonstrate the utility of HANSEN, we perform Authorship Attribution (AA) & Author Verification (AV) on human-spoken datasets and conducted Human vs. AI spoken text detection using state-of-the-art (SOTA) models. While SOTA methods, such as, character ngram or Transformer-based model, exhibit similar AA & AV performance in human-spoken datasets compared to written ones, there is much room for improvement in AI-generated spoken text detection. The HANSEN benchmark is available at: https://huggingface.co/datasets/HANSEN-REPO/HANSEN.
翻译:作者分析(亦称风格计量学)长期以来一直是自然语言处理(NLP)的关键分支。同样,近年来大语言模型(LLMs)的突破使得作者分析在区分人类撰写文本与AI生成文本方面愈发重要。然而,这些作者分析任务主要聚焦于书面文本,未充分考虑语音文本。为此,我们引入了最大的语音文本基准——HANSEN(人类与AI语音文本基准)。HANSEN不仅精心整理了现有附带转录文本的语音数据集,还创建了全新的AI生成语音文本数据集。该基准共包含17个人类语音数据集,以及采用三大主流大语言模型(ChatGPT、PaLM2和Vicuna13B)生成的AI语音文本。为评估并展示HANSEN的实用性,我们基于人类语音数据集开展了作者归属(AA)与作者验证(AV)任务,并利用当前最优(SOTA)模型进行人类与AI语音文本检测。研究显示,尽管字符n-gram或基于Transformer的模型等SOTA方法在人类语音数据集上的AA与AV表现与书面文本类似,但AI生成语音文本的检测效果仍有显著提升空间。HANSEN基准可通过以下链接获取:https://huggingface.co/datasets/HANSEN-REPO/HANSEN。