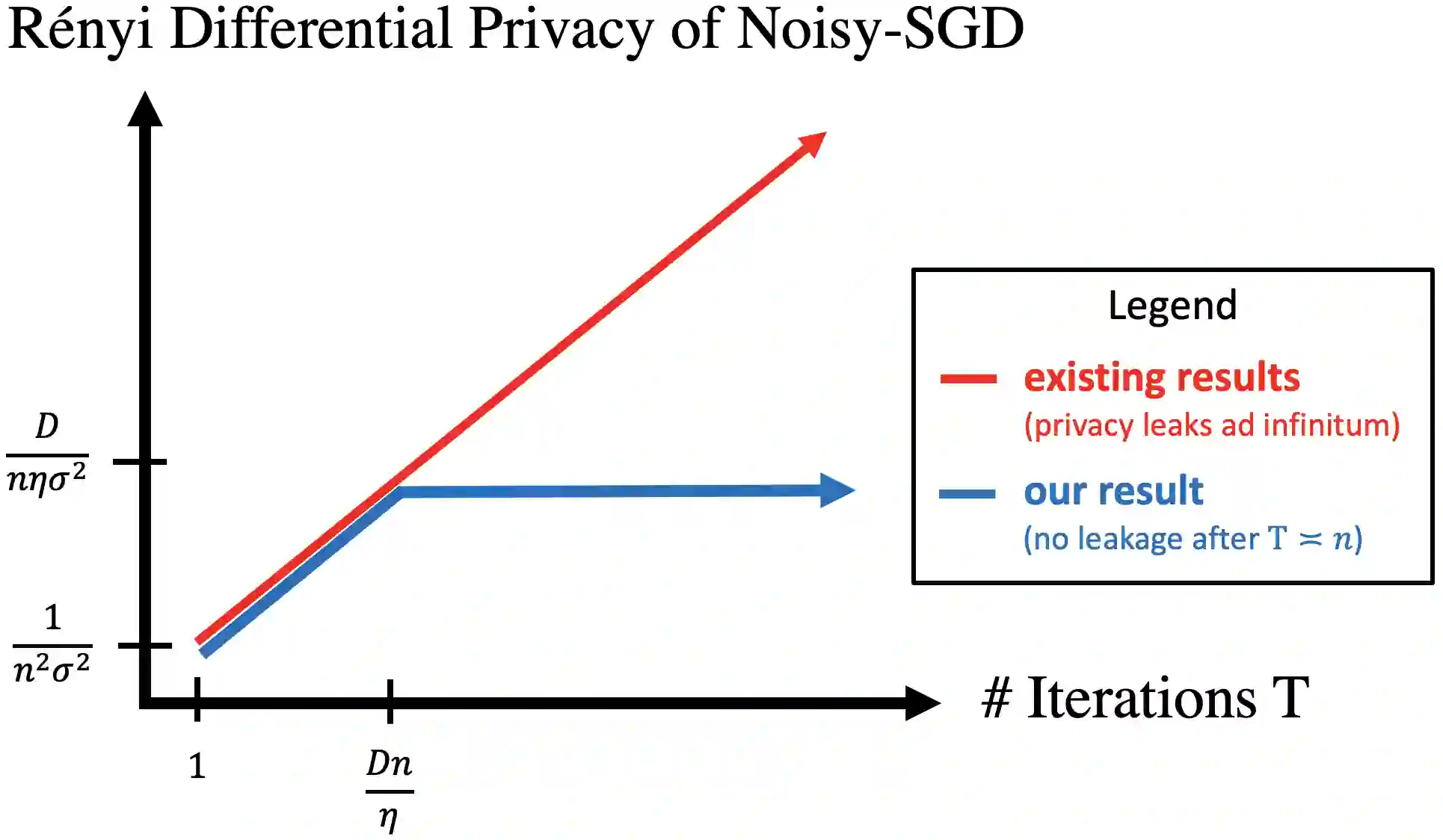
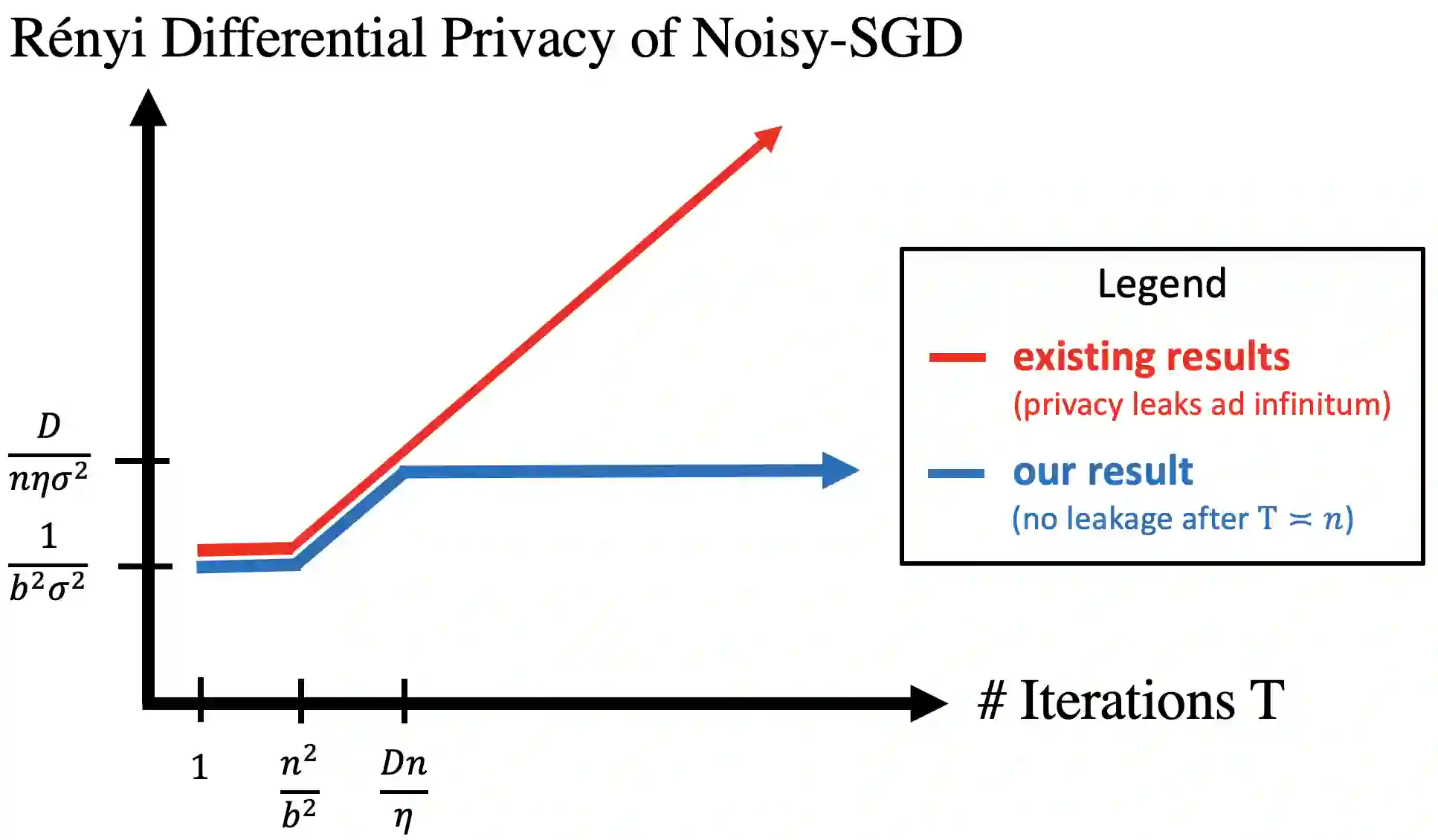
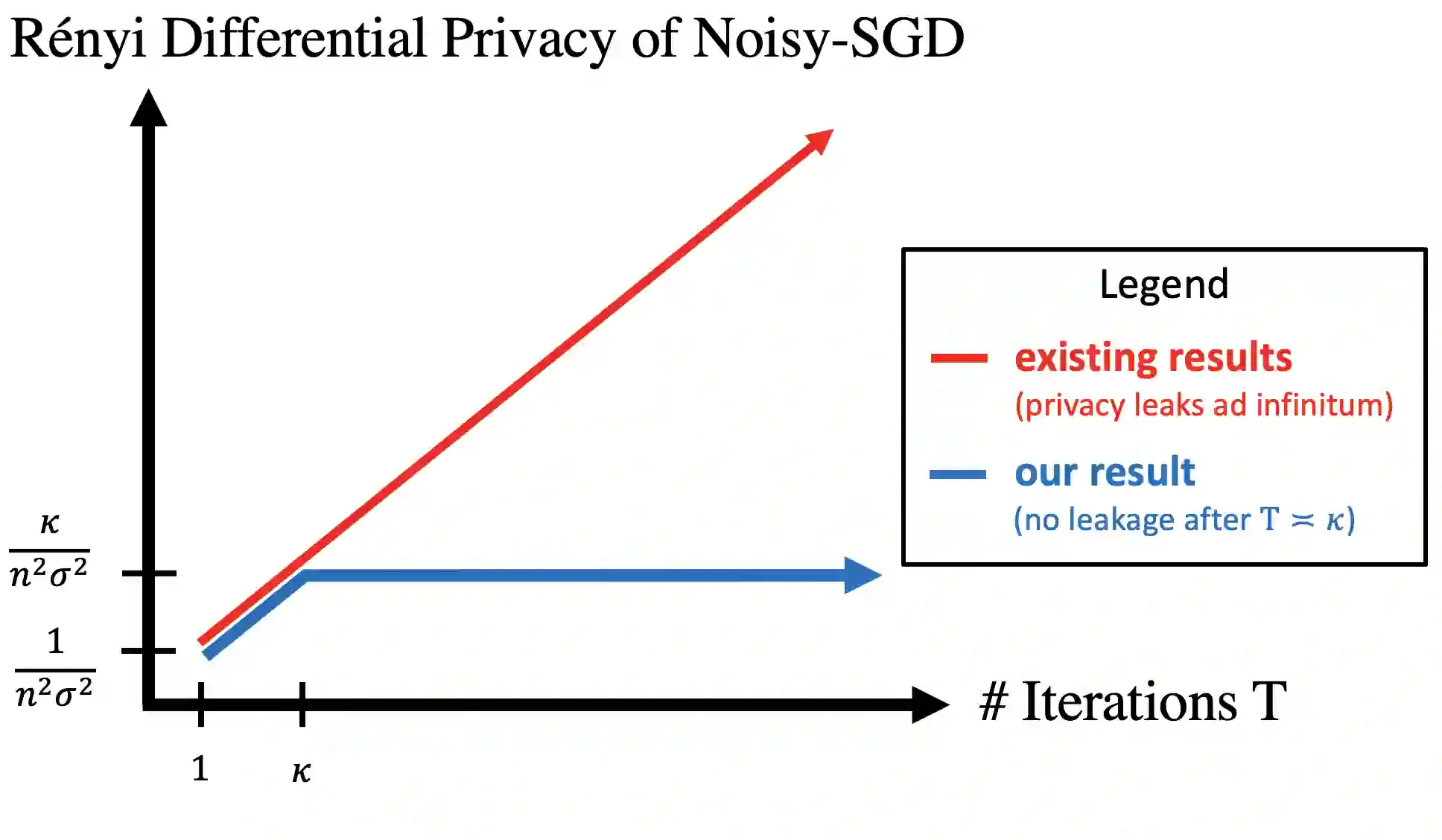
A central issue in machine learning is how to train models on sensitive user data. Industry has widely adopted a simple algorithm: Stochastic Gradient Descent with noise (a.k.a. Stochastic Gradient Langevin Dynamics). However, foundational theoretical questions about this algorithm's privacy loss remain open -- even in the seemingly simple setting of smooth convex losses over a bounded domain. Our main result resolves these questions: for a large range of parameters, we characterize the differential privacy up to a constant factor. This result reveals that all previous analyses for this setting have the wrong qualitative behavior. Specifically, while previous privacy analyses increase ad infinitum in the number of iterations, we show that after a small burn-in period, running SGD longer leaks no further privacy. Our analysis departs from previous approaches based on fast mixing, instead using techniques based on optimal transport (namely, Privacy Amplification by Iteration) and the Sampled Gaussian Mechanism (namely, Privacy Amplification by Sampling). Our techniques readily extend to other settings, e.g., strongly convex losses, non-uniform stepsizes, arbitrary batch sizes, and random or cyclic choice of batches.
翻译:机器学习的一个核心问题是如何在敏感用户数据上训练模型。业界已广泛采用一种简单算法:带噪声的随机梯度下降(又称随机梯度朗之万动力学)。然而,关于该算法隐私损失的基础理论问题仍未解决——即使在有界域上光滑凸损失这一看似简单的设置中也是如此。我们的主要结果解决了这些问题:对于大范围参数,我们以常数因子精度刻画了其差分隐私性。这一结果揭示,此前该设置的所有分析在定性行为上均是错误的。具体而言,以往的隐私分析会随迭代次数无限增长,而我们证明,经过短暂的"预热期"后,延长SGD运行时间不会进一步泄露隐私。我们的分析摒弃了基于快速混合的传统方法,转而采用基于最优传输(即迭代隐私放大)和采样高斯机制(即采样隐私放大)的技术。我们的方法可直接推广至其他设置,例如强凸损失、非均匀步长、任意批次大小以及随机或循环批次选择。