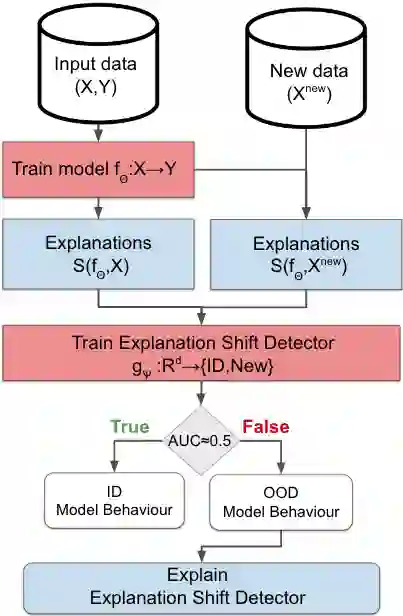
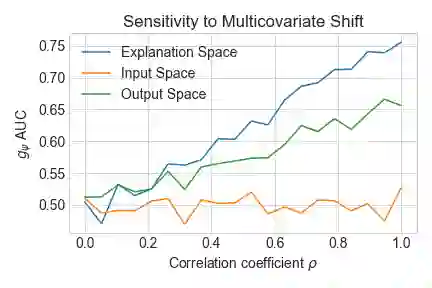
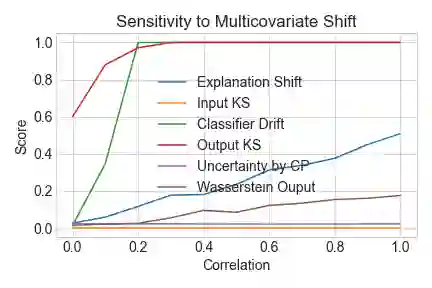
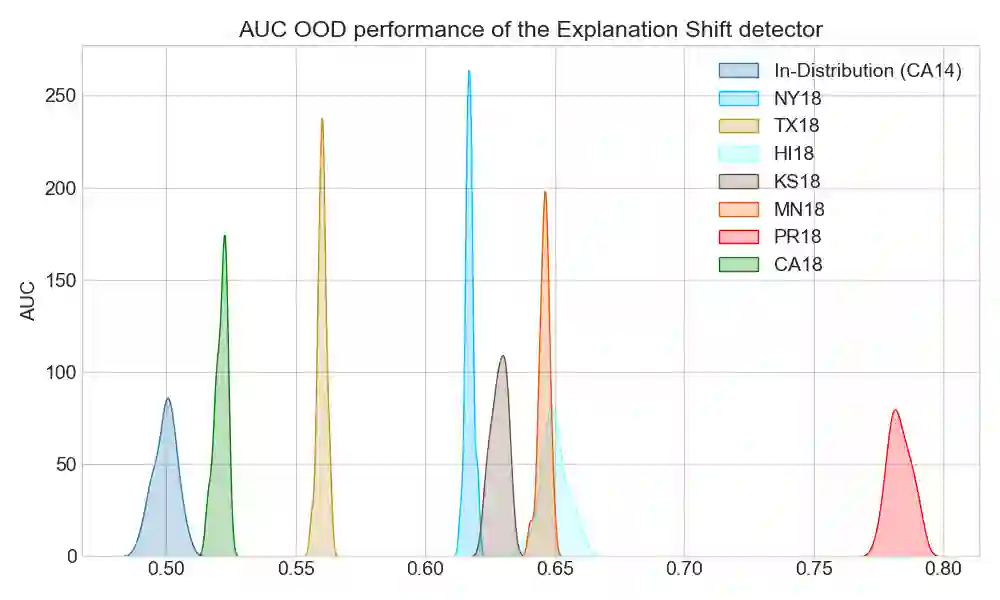
As input data distributions evolve, the predictive performance of machine learning models tends to deteriorate. In practice, new input data tend to come without target labels. Then, state-of-the-art techniques model input data distributions or model prediction distributions and try to understand issues regarding the interactions between learned models and shifting distributions. We suggest a novel approach that models how explanation characteristics shift when affected by distribution shifts. We find that the modeling of explanation shifts can be a better indicator for detecting out-of-distribution model behaviour than state-of-the-art techniques. We analyze different types of distribution shifts using synthetic examples and real-world data sets. We provide an algorithmic method that allows us to inspect the interaction between data set features and learned models and compare them to the state-of-the-art. We release our methods in an open-source Python package, as well as the code used to reproduce our experiments.
翻译:随着输入数据分布的演变,机器学习模型的预测性能往往会下降。在实践中,新的输入数据通常不带目标标签。当前最先进的技术通过对输入数据分布或模型预测分布进行建模,试图理解学习模型与偏移分布之间的交互问题。我们提出了一种新颖的方法,用于建模受分布偏移影响时解释特征如何变化。我们发现,相比于最先进的技术,对解释偏移的建模能更好地检测模型在分布外数据上的行为。我们利用合成示例和真实数据集分析了不同类型的分布偏移。我们提供了一种算法方法,用于检查数据集特征与学习模型之间的交互,并将其与最先进技术进行比较。我们以开源Python包的形式发布了我们的方法,以及用于复现实验的代码。