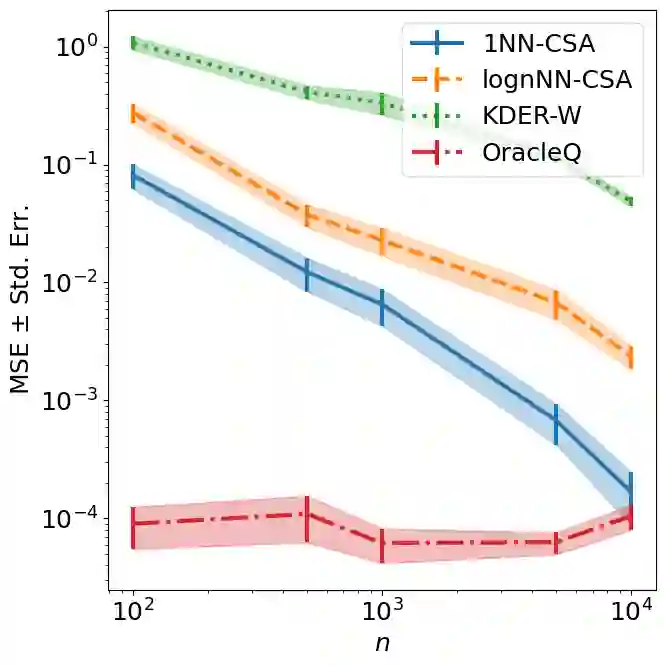
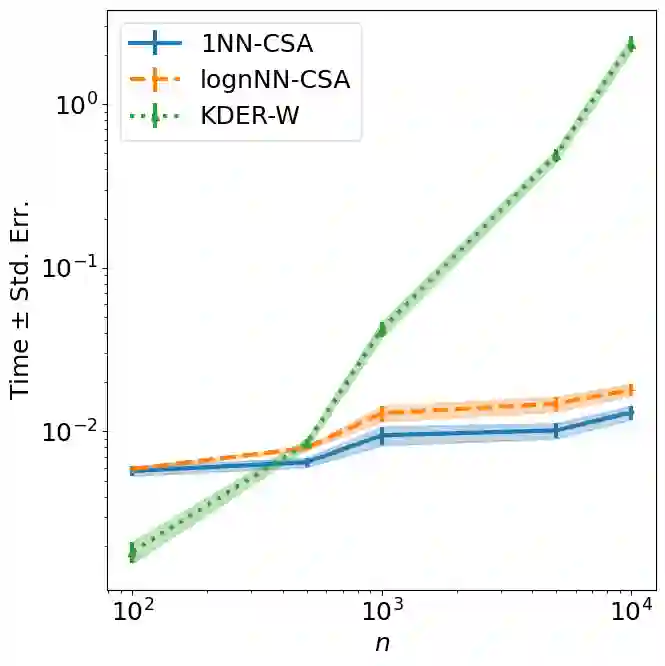
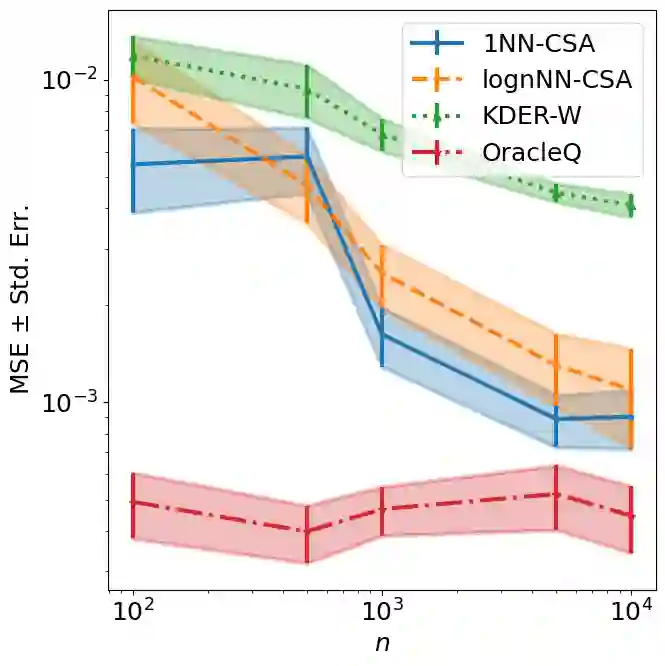
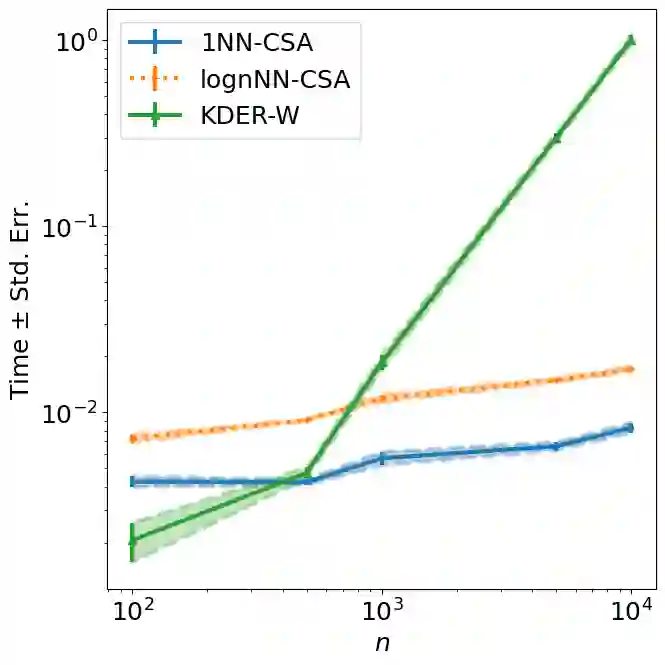
Many existing covariate shift adaptation methods estimate sample weights to be used in the risk estimation in order to mitigate the gap between the source and the target distribution. However, non-parametrically estimating the optimal weights typically involves computationally expensive hyper-parameter tuning that is crucial to the final performance. In this paper, we propose a new non-parametric approach to covariate shift adaptation which avoids estimating weights and has no hyper-parameter to be tuned. Our basic idea is to label unlabeled target data according to the $k$-nearest neighbors in the source dataset. Our analysis indicates that setting $k = 1$ is an optimal choice. Thanks to this property, there is no need to tune any hyper-parameters, unlike other non-parametric methods. Moreover, our method achieves a running time quasi-linear in the sample size with a theoretical guarantee, for the first time in the literature to the best of our knowledge. Our results include sharp rates of convergence for estimating the joint probability distribution of the target data. In particular, the variance of our estimators has the same rate of convergence as for standard parametric estimation despite their non-parametric nature. Our numerical experiments show that proposed method brings drastic reduction in the running time with accuracy comparable to that of the state-of-the-art methods.
翻译:现有许多协变量偏移自适应方法通过估计样本权重来调整源分布与目标分布之间的差异,以用于风险估计。然而,非参数化估计最优权重通常需要进行计算昂贵的超参数调优,而这对最终性能至关重要。本文提出一种新的非参数协变量偏移自适应方法,该方法无需估计权重且无需调整超参数。其核心思想是根据源数据集中待标记目标数据的$k$近邻进行标签分配。分析表明,设置$k=1为最优选择。得益于这一特性,与其他非参数方法不同,本方法无需进行任何超参数调优。此外,据我们所知,本方法首次在文献中实现了与样本规模准线性相关的运行时间,并具有理论保证。研究结果包含目标数据联合概率分布估计的尖锐收敛速率。特别地,尽管采用非参数框架,我们的估计量方差仍达到标准参数估计的收敛速率。数值实验表明,该方法在保持与顶尖方法相当精度的同时,显著降低了运行时间。