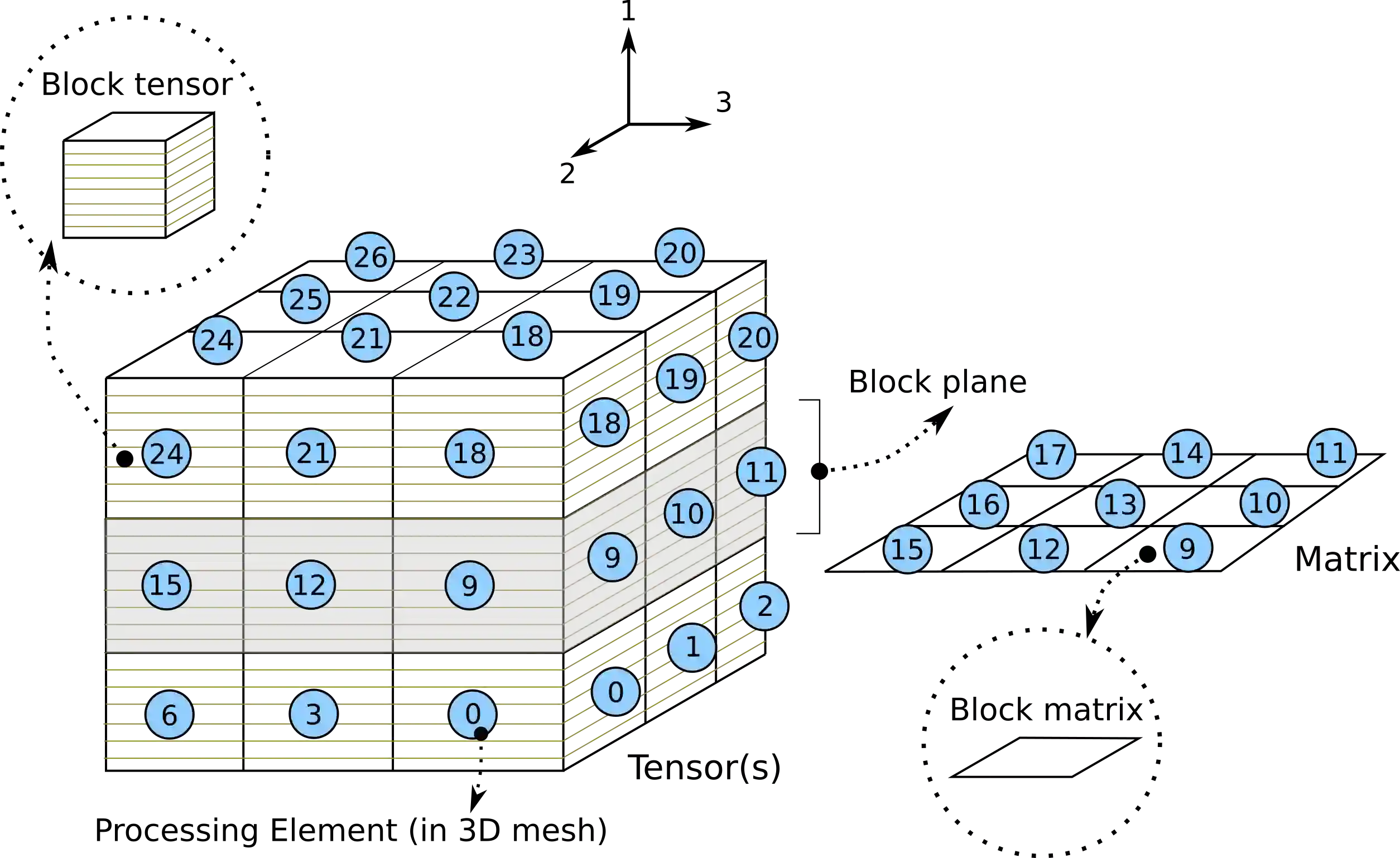
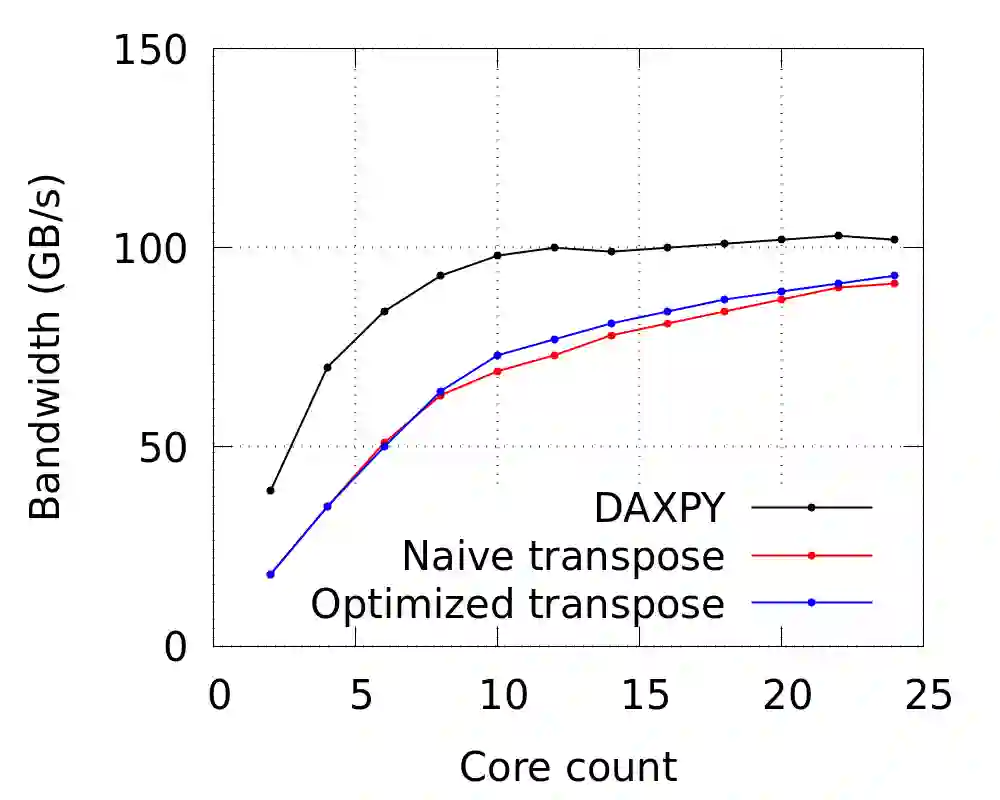
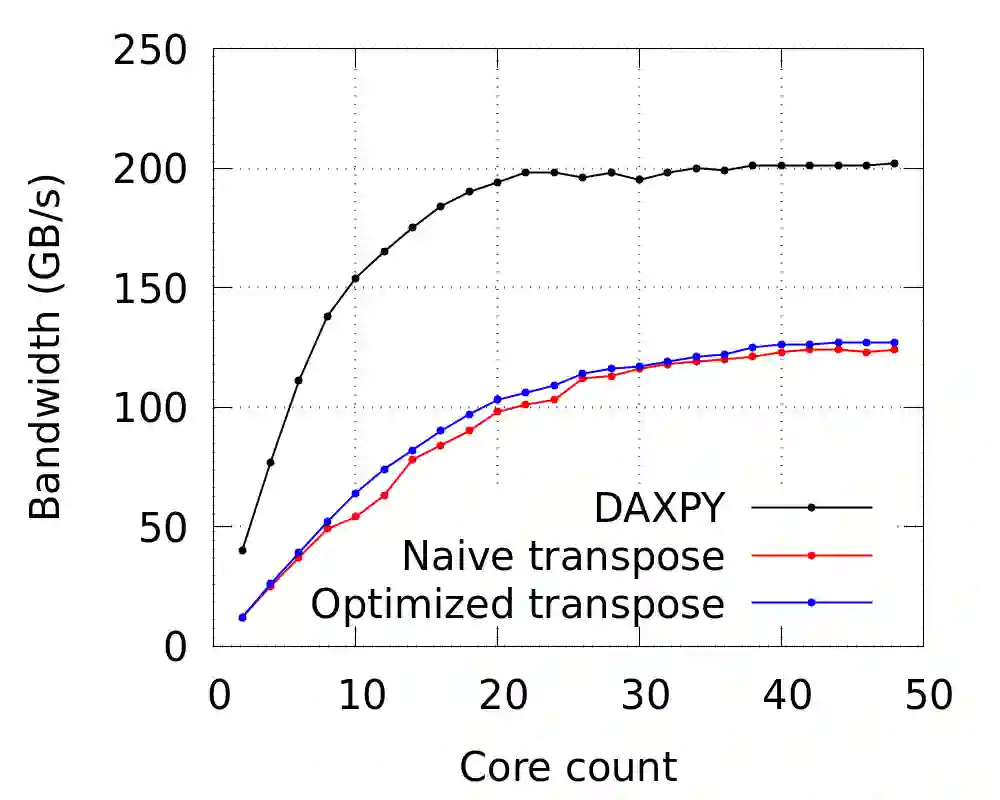
The 3D Discrete Fourier Transform (DFT) is a technique used to solve problems in disparate fields. Nowadays, the commonly adopted implementation of the 3D-DFT is derived from the Fast Fourier Transform (FFT) algorithm. However, evidence indicates that the distributed memory 3D-FFT algorithm does not scale well due to its use of all-to-all communication. Here, building on the work of Sedukhin \textit{et al}. [Proceedings of the 30th International Conference on Computers and Their Applications, CATA 2015 pp. 193-200 (01 2015)], we revisit the possibility of improving the scaling of the 3D-DFT by using an alternative approach that uses point-to-point communication, albeit at a higher arithmetic complexity. The new algorithm exploits tensor-matrix multiplications on a volumetrically decomposed domain via three specially adapted variants of Cannon's algorithm. It has here been implemented as a C++ library called S3DFT and tested on the JUWELS Cluster at the J\"ulich Supercomputing Center. Our implementation of the shared memory tensor-matrix multiplication attained 88\% of the theoretical single node peak performance. One variant of the distributed memory tensor-matrix multiplication shows excellent scaling, while the other two show poorer performance, which can be attributed to their intrinsic communication patterns. A comparison of S3DFT with the Intel MKL and FFTW3 libraries indicates that currently iMKL performs best overall, followed in order by FFTW3 and S3DFT. This picture might change with further improvements of the algorithm and/or when running on clusters that use network connections with higher latency, e.g. on cloud platforms.
翻译:三维离散傅里叶变换(3D-DFT)是用于解决不同领域问题的一种技术。目前,3D-DFT的常用实现基于快速傅里叶变换(FFT)算法。然而,有证据表明,分布式内存3D-FFT算法由于采用全到全通信模式,其可扩展性不佳。本文在Sedukhin等人[第30届国际计算机及其应用会议论文集,CATA 2015,第193-200页(2015年1月)]的工作基础上,重新探讨了通过替代方法改善3D-DFT可扩展性的可能性:该方法采用点对点通信,尽管算术复杂度更高。新算法通过Cannon算法的三种特殊变体,在体分解域上利用张量-矩阵乘法实现。我们已将其实现为名为S3DFT的C++库,并在于利希超级计算中心的JUWELS集群上进行了测试。共享内存张量-矩阵乘法的实现达到了理论单节点峰值性能的88%。分布式内存张量-矩阵乘法的一种变体展现出优异的可扩展性,而另外两种变体性能较差,这归因于其固有的通信模式。将S3DFT与Intel MKL和FFTW3库进行比较,结果表明目前iMKL整体性能最优,其次依次为FFTW3和S3DFT。随着算法的进一步改进,或在使用更高延迟网络连接的集群(如云平台)上运行时,这一局面可能发生变化。