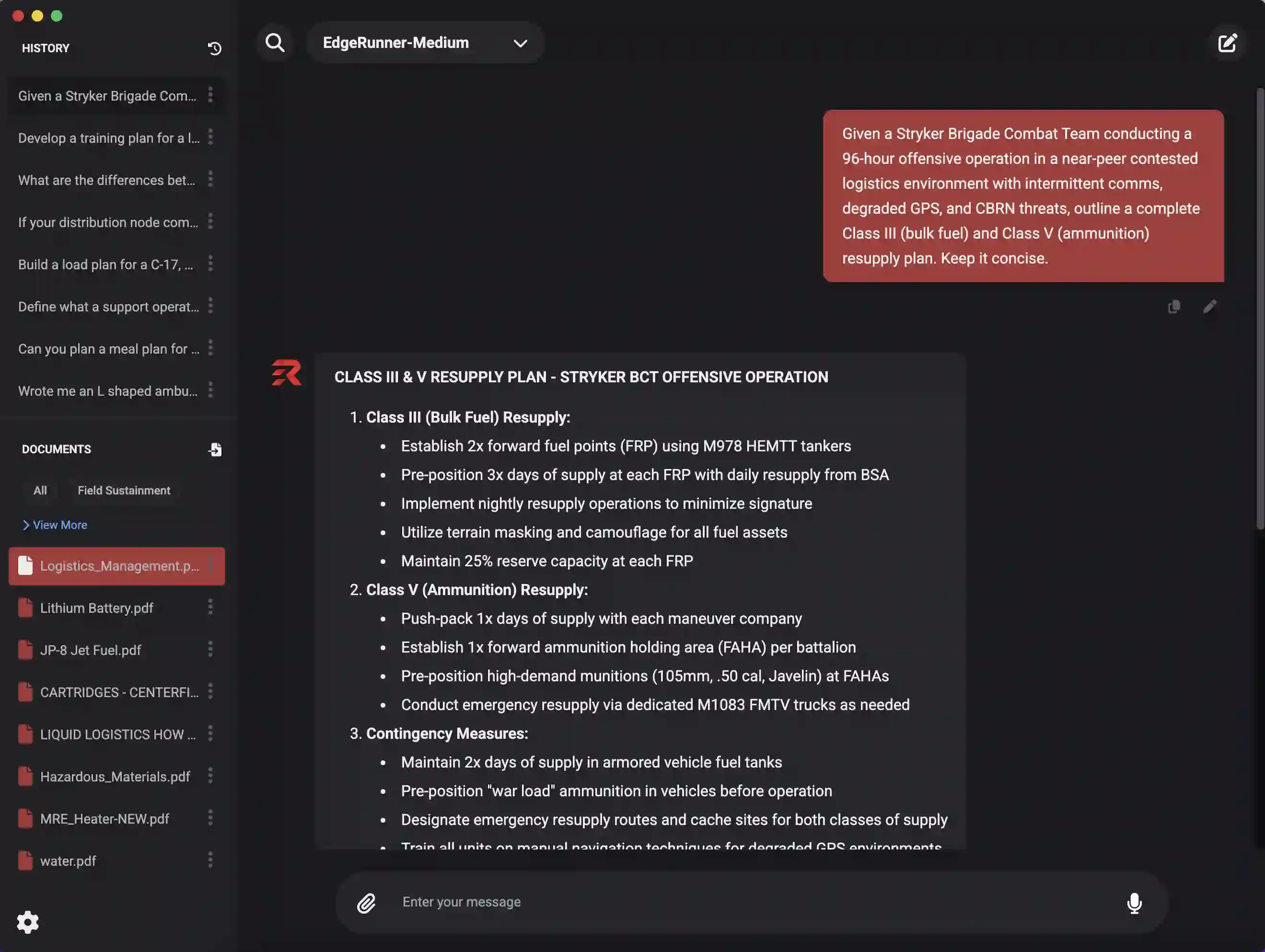
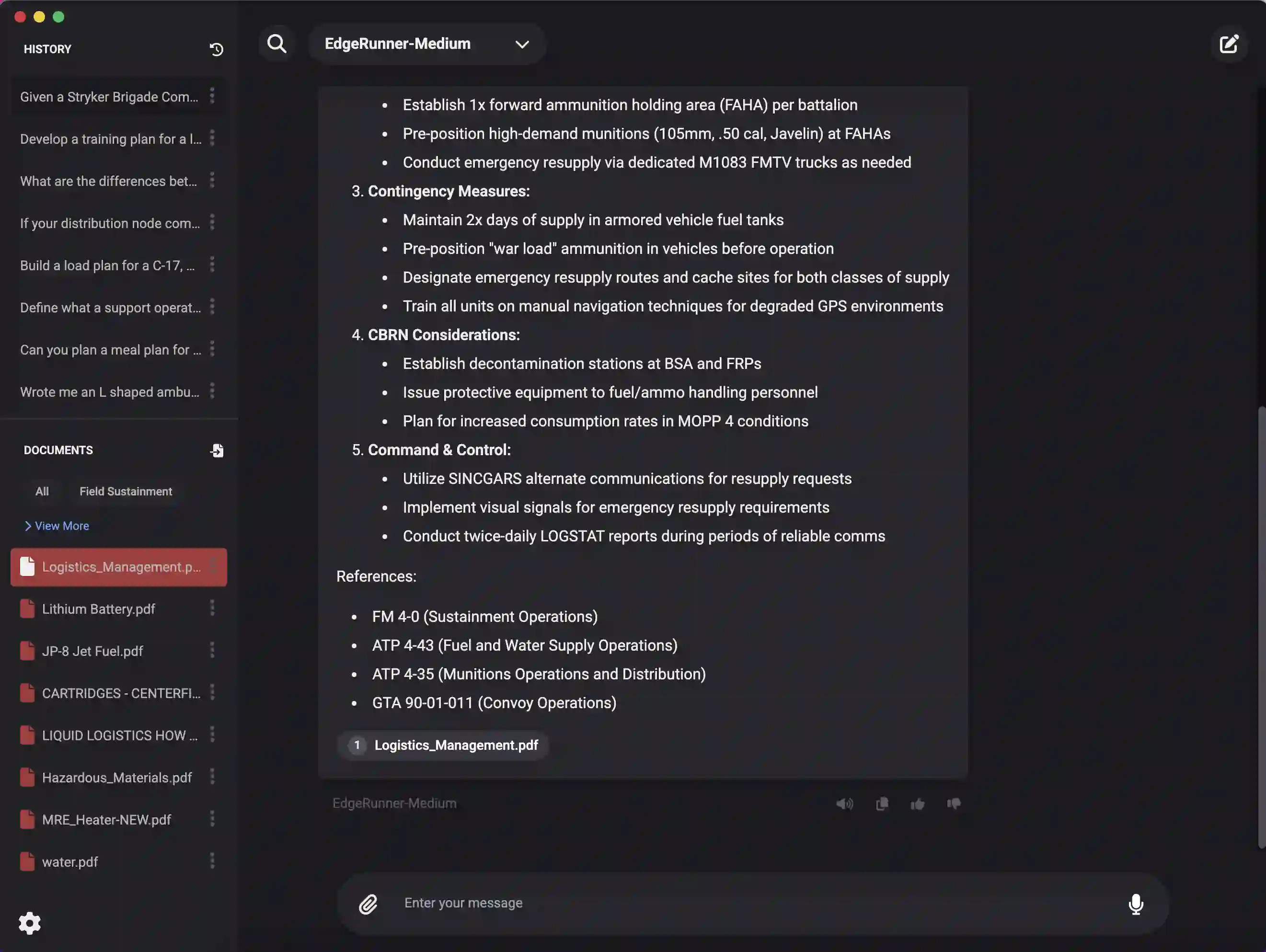
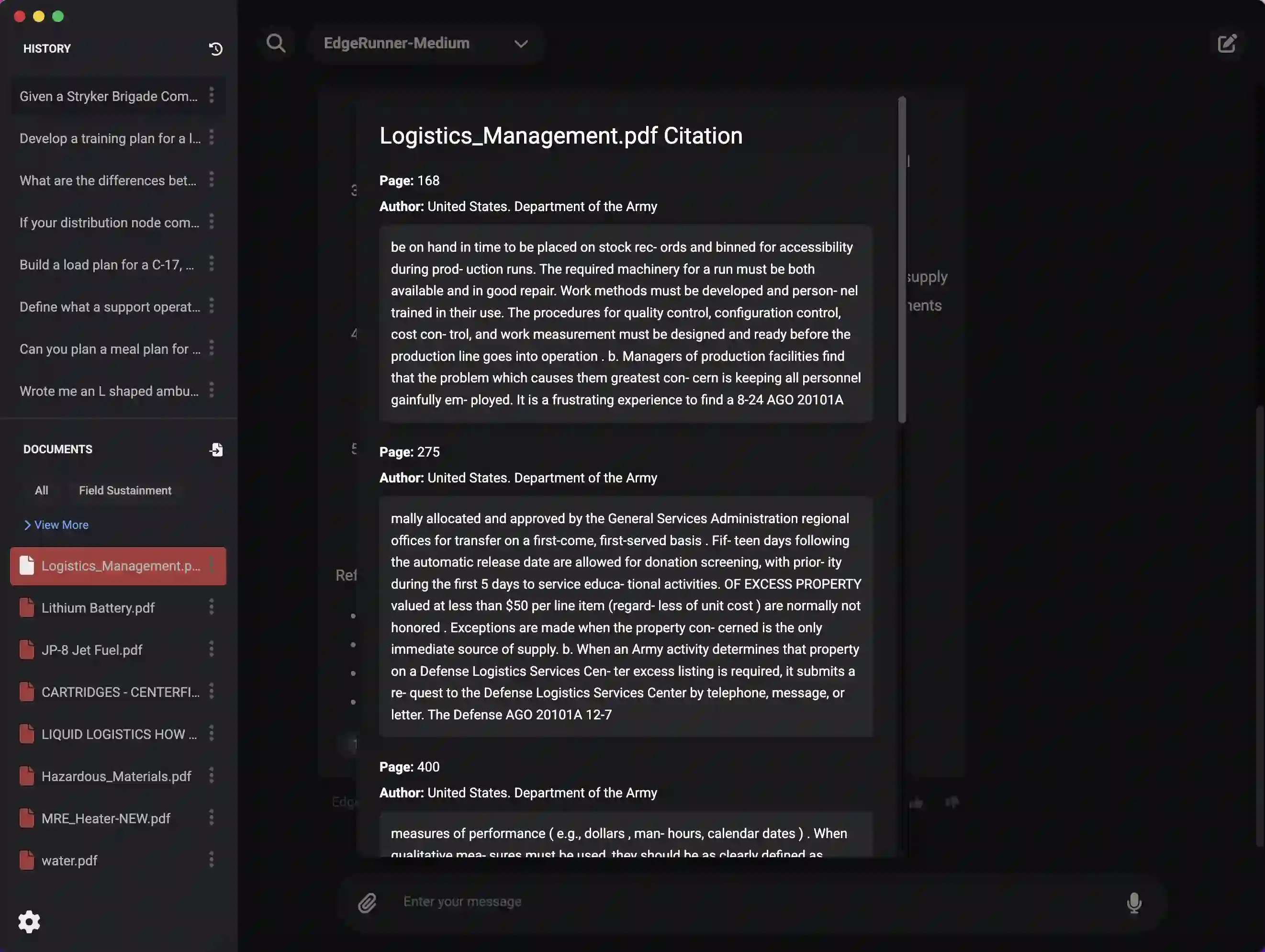
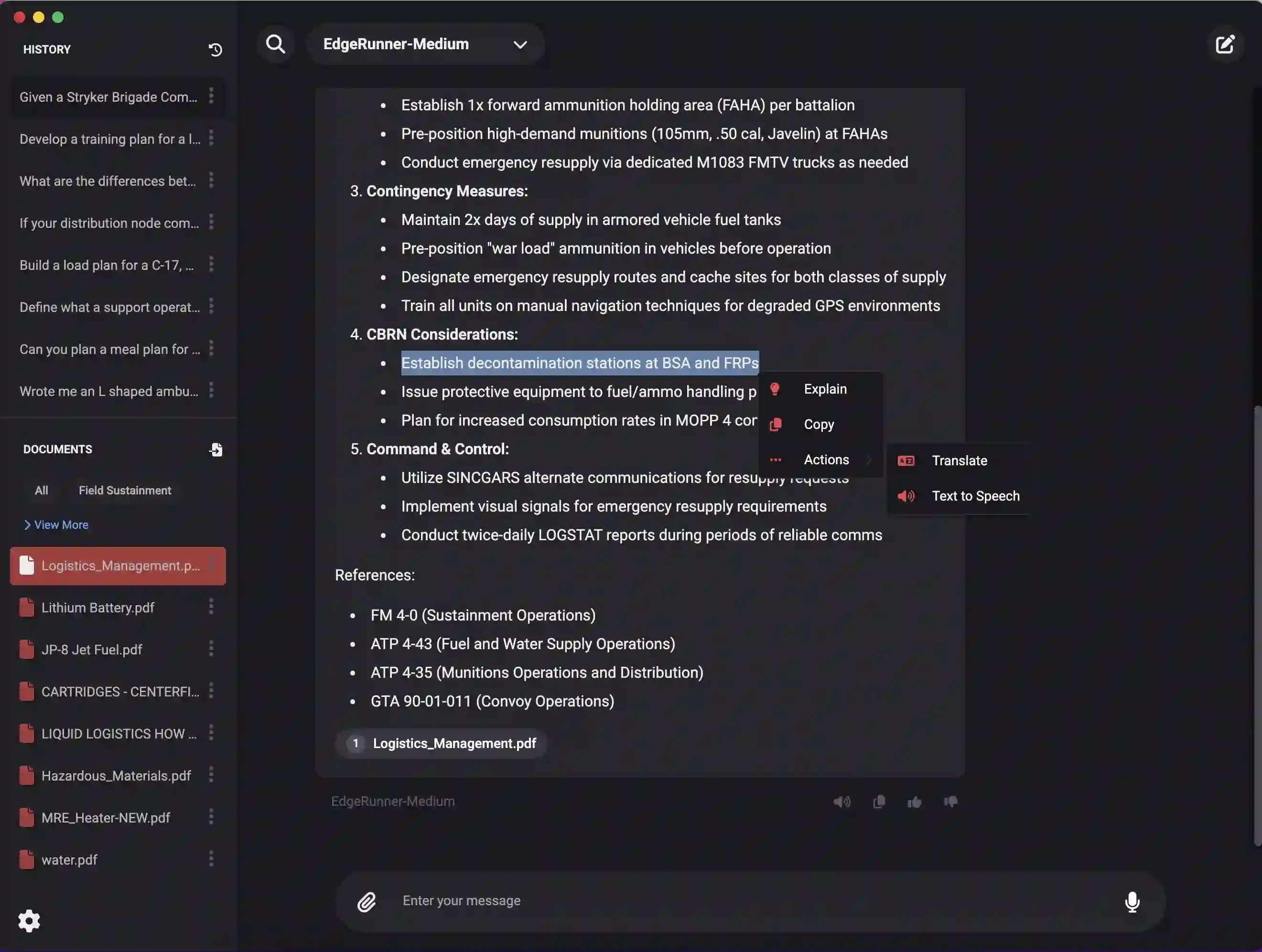
We present EdgeRunner 20B, a fine-tuned version of gpt-oss-20b optimized for military tasks. EdgeRunner 20B was trained on 1.6M high-quality records curated from military documentation and websites. We also present four new tests sets: (a) combat arms, (b) combat medic, (c) cyber operations, and (d) mil-bench-5k (general military knowledge). On these military test sets, EdgeRunner 20B matches or exceeds GPT-5 task performance with 95%+ statistical significance, except for the high reasoning setting on the combat medic test set and the low reasoning setting on the mil-bench-5k test set. Versus gpt-oss-20b, there is no statistically-significant regression on general-purpose benchmarks like ARC-C, GPQA Diamond, GSM8k, IFEval, MMLU Pro, or TruthfulQA, except for GSM8k in the low reasoning setting. We also present analyses on hyperparameter settings, cost, and throughput. These findings show that small, locally-hosted models are ideal solutions for data-sensitive operations such as in the military domain, allowing for deployment in air-gapped edge devices.
翻译:本文介绍EdgeRunner 20B,这是基于gpt-oss-20b针对军事任务优化的微调版本。该模型使用从军事文档和网站精选的160万条高质量记录进行训练。我们同时提出四个新测试集:(a)战斗兵种、(b)战斗医疗、(c)网络作战、(d)mil-bench-5k(通用军事知识)。在这些军事测试集上,除战斗医疗测试集的高推理场景及mil-bench-5k测试集的低推理场景外,EdgeRunner 20B以超过95%的统计显著性达到或超越GPT-5的任务性能。相较于gpt-oss-20b,在ARC-C、GPQA Diamond、GSM8k、IFEval、MMLU Pro、TruthfulQA等通用基准测试中未出现统计显著性退化(仅GSM8k在低推理场景例外)。我们还提供了超参数设置、成本及吞吐量的分析。这些发现表明,小型本地化部署模型是军事等数据敏感领域的理想解决方案,可实现于物理隔离的边缘设备部署。