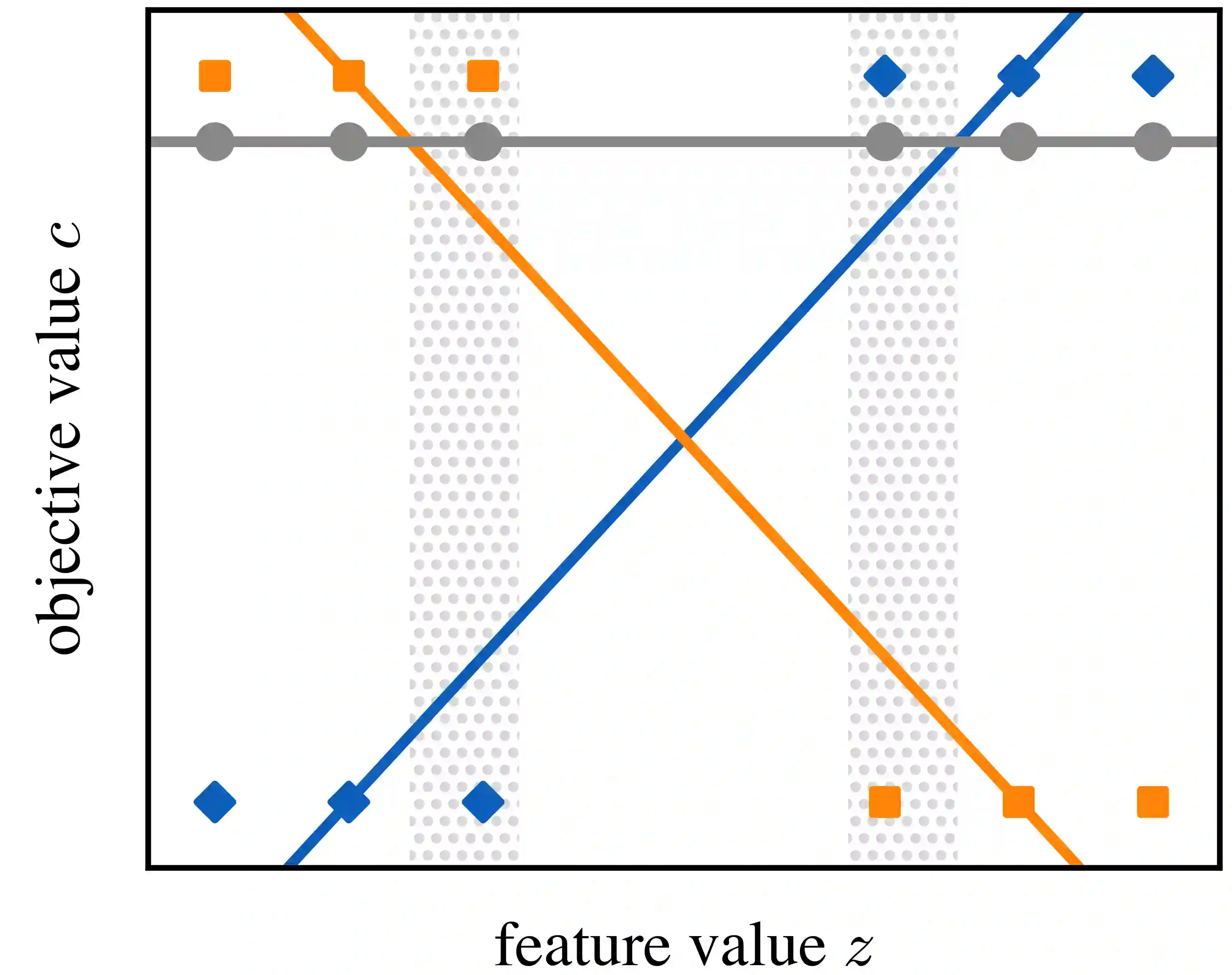
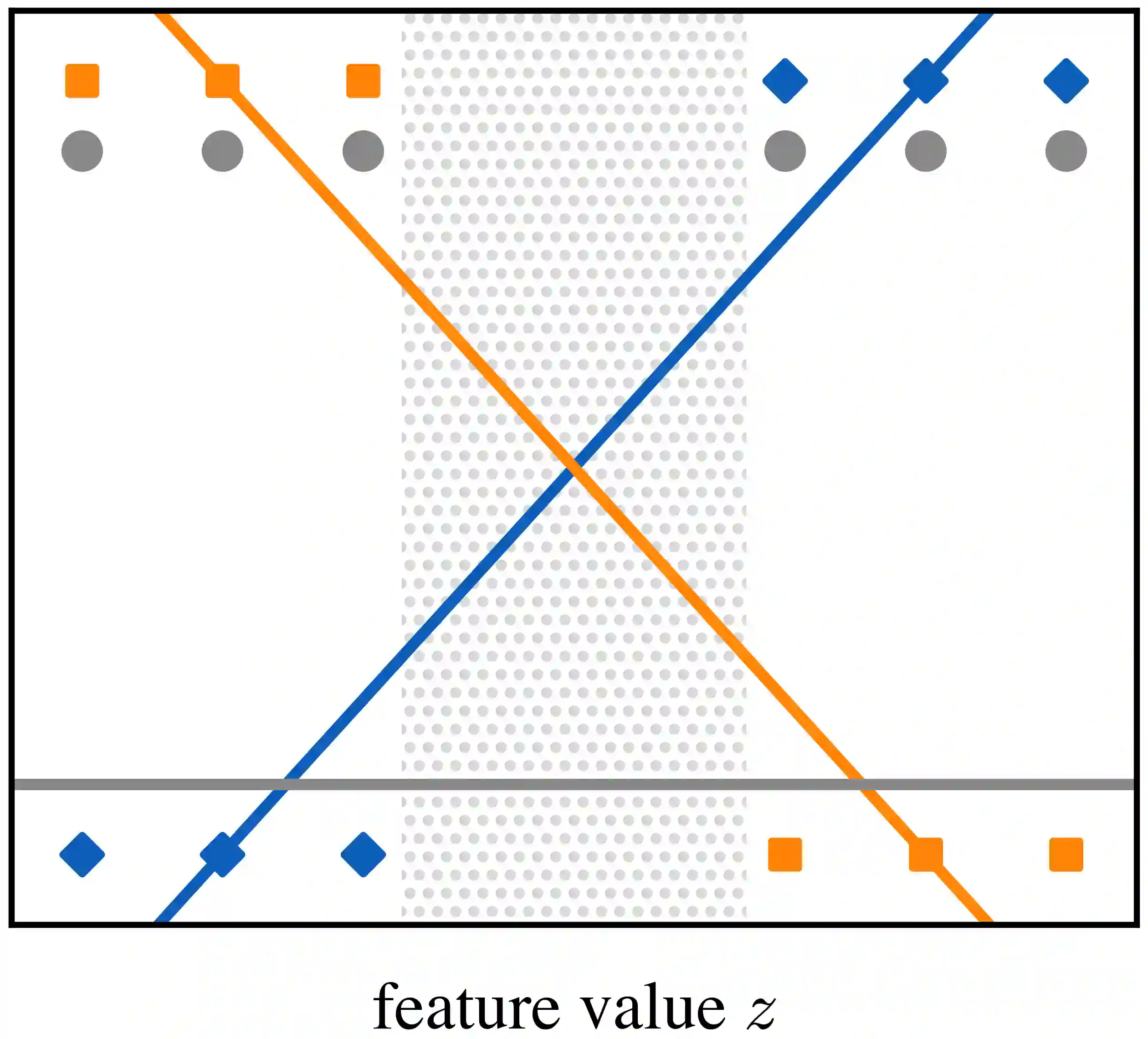
Optimization models used to make discrete decisions often contain uncertain parameters that are context-dependent and are estimated through prediction. To account for the quality of the decision made based on the prediction, decision-focused learning (end-to-end predict-then-optimize) aims at training the predictive model to minimize regret, i.e., the loss incurred by making a suboptimal decision. Despite the challenge of this loss function being possibly non-convex and in general non-differentiable, effective gradient-based learning approaches have been proposed to minimize the expected loss, using the empirical loss as a surrogate. However, empirical regret can be an ineffective surrogate because the uncertainty in the optimization model makes the empirical regret unequal to the expected regret in expectation. To illustrate the impact of this inequality, we evaluate the effect of aleatoric and epistemic uncertainty on the accuracy of empirical regret as a surrogate. Next, we propose three robust loss functions that more closely approximate expected regret. Experimental results show that training two state-of-the-art decision-focused learning approaches using robust regret losses improves test-sample empirical regret in general while keeping computational time equivalent relative to the number of training epochs.
翻译:用于离散决策的优化模型通常包含依赖于上下文的不确定参数,这些参数通过预测进行估计。为了考虑基于预测所做决策的质量,面向决策的学习(端到端预测-优化)旨在训练预测模型以最小化遗憾,即因做出次优决策而产生的损失。尽管该损失函数可能非凸且通常不可微,但有效的基于梯度的学习方法已被提出,利用经验损失作为替代来最小化期望损失。然而,经验遗憾可能是一种无效的替代,因为优化模型中的不确定性使得经验遗憾在期望上不等于期望遗憾。为了说明这种不平等的影响,我们评估了偶然不确定性和认知不确定性对经验遗憾替代准确性的影响。接下来,我们提出了三种更接近近似期望遗憾的稳健损失函数。实验结果表明,使用稳健遗憾损失训练两种最先进的面向决策的学习方法,通常在提高测试样本经验遗憾的同时,相对于训练轮数保持了相当的计算时间。