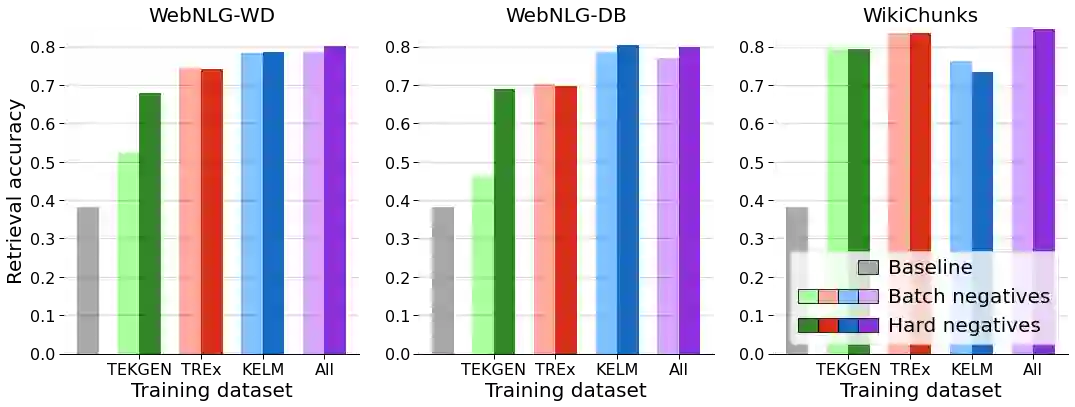
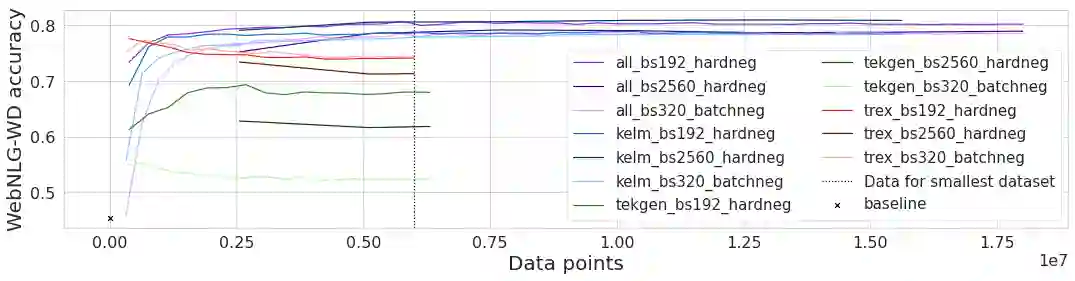
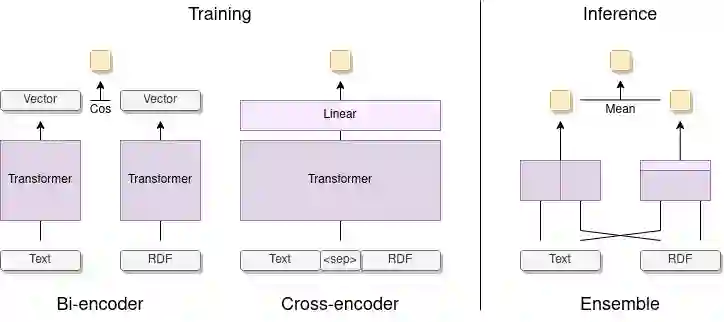
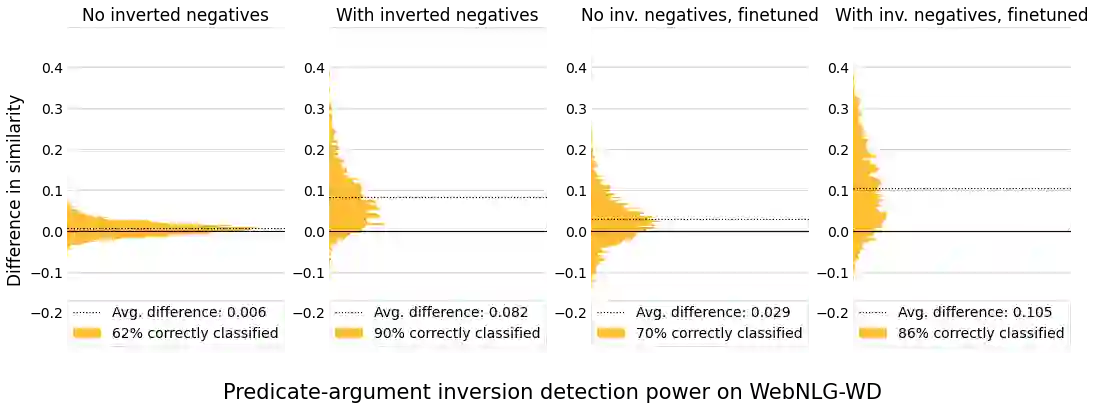
A key feature of neural models is that they can produce semantic vector representations of objects (texts, images, speech, etc.) ensuring that similar objects are close to each other in the vector space. While much work has focused on learning representations for other modalities, there are no aligned cross-modal representations for text and knowledge base (KB) elements. One challenge for learning such representations is the lack of parallel data, which we use contrastive training on heuristics-based datasets and data augmentation to overcome, training embedding models on (KB graph, text) pairs. On WebNLG, a cleaner manually crafted dataset, we show that they learn aligned representations suitable for retrieval. We then fine-tune on annotated data to create EREDAT (Ensembled Representations for Evaluation of DAta-to-Text), a similarity metric between English text and KB graphs. EREDAT outperforms or matches state-of-the-art metrics in terms of correlation with human judgments on WebNLG even though, unlike them, it does not require a reference text to compare against.
翻译:神经模型的一个关键特性在于,它们能够生成对象(文本、图像、语音等)的语义向量表示,确保相似对象在向量空间中彼此接近。尽管大量工作聚焦于其他模态的表示学习,但目前尚无针对文本与知识库元素的跨模态对齐表示。学习此类表示的挑战之一在于缺乏平行数据,我们通过基于启发式数据集的对比训练与数据增强来克服这一难题,从而训练基于(知识图谱、文本)对的嵌入模型。在更干净的人工构建数据集WebNLG上,我们证明这些模型能够学习到适用于检索的对齐表示。随后,我们在标注数据上进行微调,创建了EREDAT(用于数据到文本评估的集成表示),这是一种衡量英语文本与知识图谱之间相似度的指标。尽管EREDAT不需要参考文本进行对比,但它在WebNLG上与人类判断的相关性方面优于或匹配现有最先进指标。