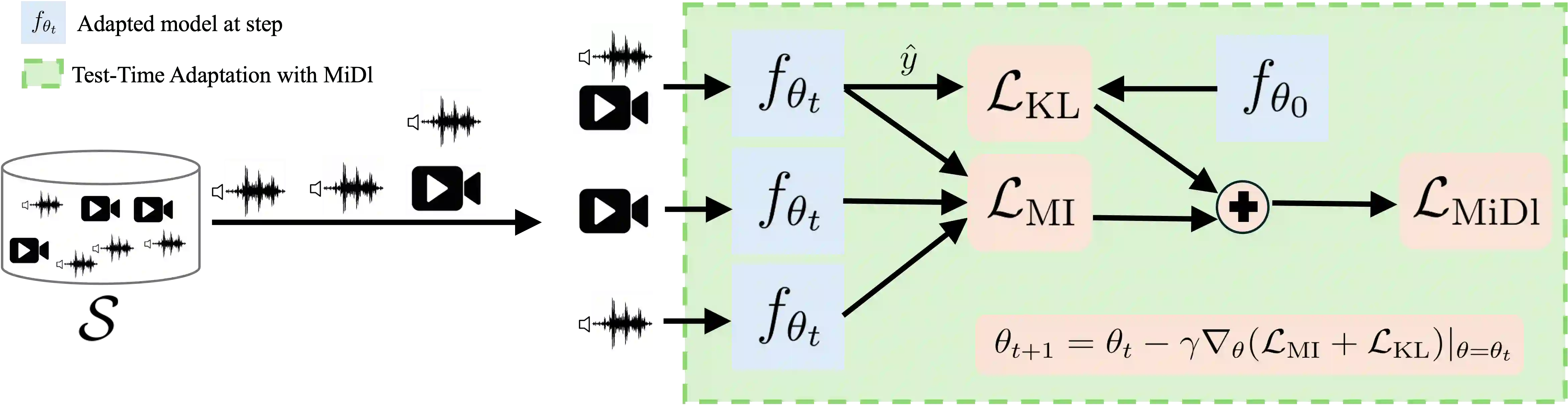
Understanding videos that contain multiple modalities is crucial, especially in egocentric videos, where combining various sensory inputs significantly improves tasks like action recognition and moment localization. However, real-world applications often face challenges with incomplete modalities due to privacy concerns, efficiency needs, or hardware issues. Current methods, while effective, often necessitate retraining the model entirely to handle missing modalities, making them computationally intensive, particularly with large training datasets. In this study, we propose a novel approach to address this issue at test time without requiring retraining. We frame the problem as a test-time adaptation task, where the model adjusts to the available unlabeled data at test time. Our method, MiDl~(Mutual information with self-Distillation), encourages the model to be insensitive to the specific modality source present during testing by minimizing the mutual information between the prediction and the available modality. Additionally, we incorporate self-distillation to maintain the model's original performance when both modalities are available. MiDl represents the first self-supervised, online solution for handling missing modalities exclusively at test time. Through experiments with various pretrained models and datasets, MiDl demonstrates substantial performance improvement without the need for retraining.
翻译:理解包含多种模态的视频至关重要,尤其是在第一人称视频中,通过融合多种感官输入可显著提升动作识别和时刻定位等任务的表现。然而,实际应用常因隐私考量、效率需求或硬件问题面临模态不完整的挑战。现有方法虽有效,但往往需要对模型进行完整重训练以处理缺失模态,导致计算开销巨大,尤其在训练数据集规模庞大时。本研究提出一种无需重训练的测试时处理方法。我们将该问题定义为测试时自适应任务,要求模型在测试阶段适应可用的无标注数据。我们提出的MiDl方法(基于互信息与自蒸馏)通过最小化预测结果与可用模态之间的互信息,迫使模型对测试时存在的特定模态来源不敏感。同时,我们引入自蒸馏策略,确保在两种模态均可用时维持模型的原始性能。MiDl是首个仅针对测试阶段、无需重训练的在线自监督解决方案。通过在多种预训练模型与数据集上的实验,MiDl在避免重训练的前提下展现出显著的性能提升。