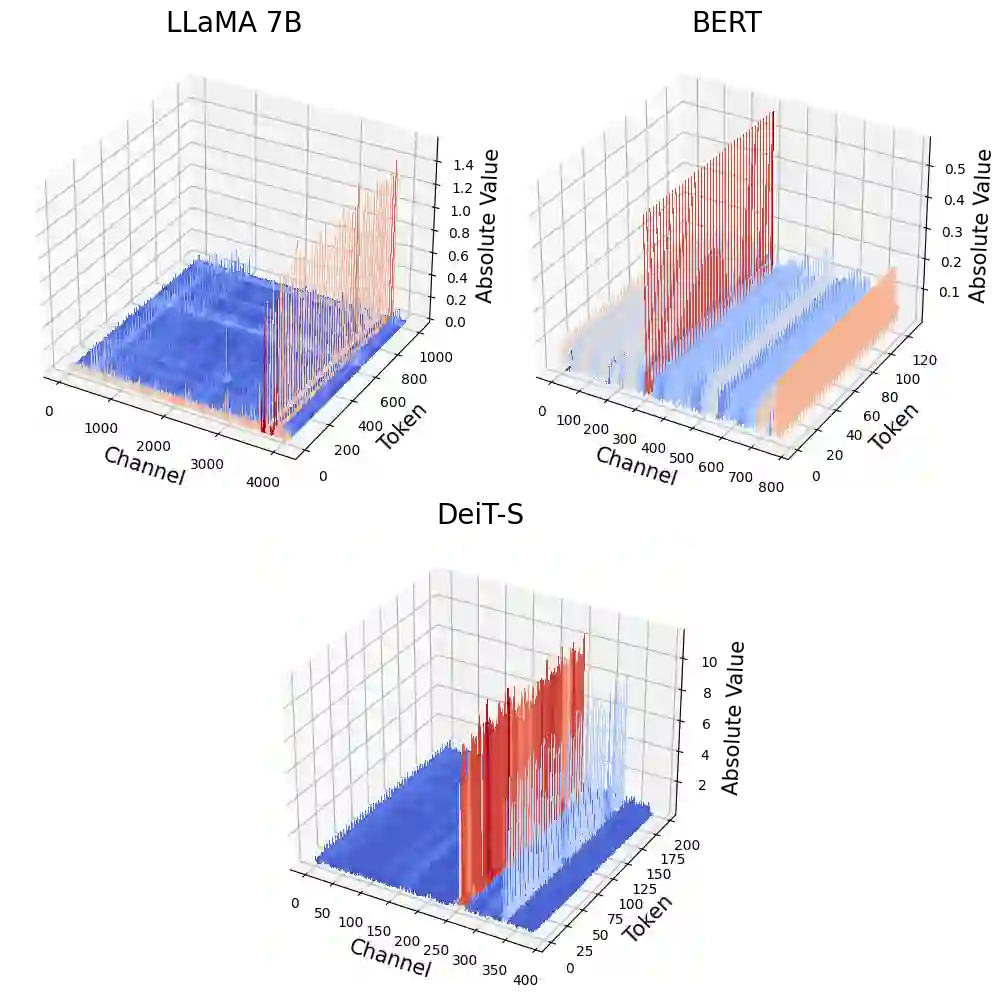
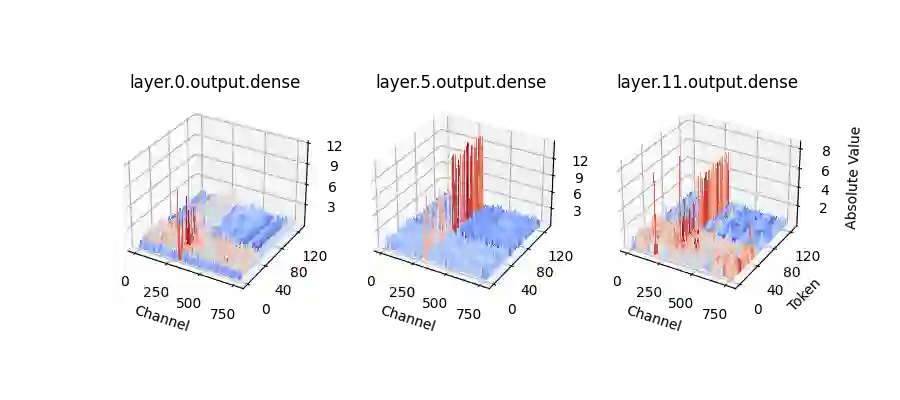
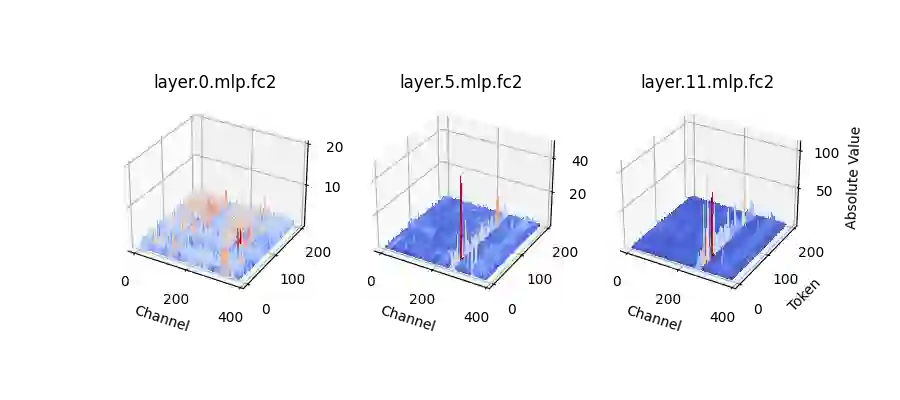
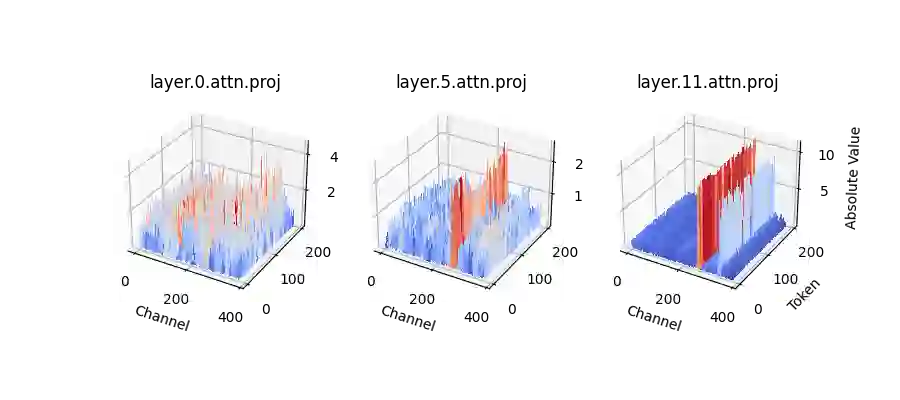
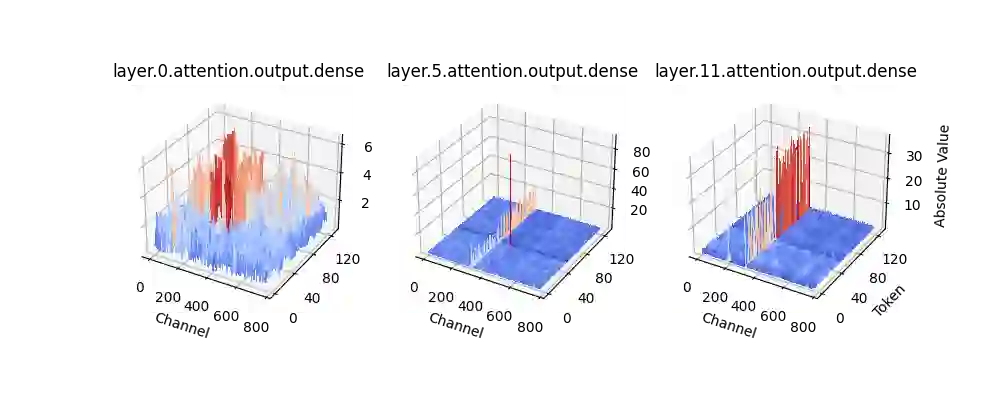
We propose LLM-FP4 for quantizing both weights and activations in large language models (LLMs) down to 4-bit floating-point values, in a post-training manner. Existing post-training quantization (PTQ) solutions are primarily integer-based and struggle with bit widths below 8 bits. Compared to integer quantization, floating-point (FP) quantization is more flexible and can better handle long-tail or bell-shaped distributions, and it has emerged as a default choice in many hardware platforms. One characteristic of FP quantization is that its performance largely depends on the choice of exponent bits and clipping range. In this regard, we construct a strong FP-PTQ baseline by searching for the optimal quantization parameters. Furthermore, we observe a high inter-channel variance and low intra-channel variance pattern in activation distributions, which adds activation quantization difficulty. We recognize this pattern to be consistent across a spectrum of transformer models designed for diverse tasks, such as LLMs, BERT, and Vision Transformer models. To tackle this, we propose per-channel activation quantization and show that these additional scaling factors can be reparameterized as exponential biases of weights, incurring a negligible cost. Our method, for the first time, can quantize both weights and activations in the LLaMA-13B to only 4-bit and achieves an average score of 63.1 on the common sense zero-shot reasoning tasks, which is only 5.8 lower than the full-precision model, significantly outperforming the previous state-of-the-art by 12.7 points. Code is available at: https://github.com/nbasyl/LLM-FP4.
翻译:[translated abstract in Chinese]
我们提出LLM-FP4方法,以训练后方式将大型语言模型中的权重和激活值均量化为4比特浮点值。现有训练后量化方案主要基于整数量化,且难以处理低于8比特的位宽。与整数量化相比,浮点量化更具灵活性,能更好地处理长尾或钟形分布,并已成为多种硬件平台的默认选择。浮点量化的一个特性是性能在很大程度上取决于指数位和裁剪范围的选择。为此,我们通过搜索最优量化参数构建了强大的浮点训练后量化基线。此外,我们发现激活分布呈现高通道间方差与低通道内方差的特征模式,这增加了激活量化的难度。我们观察到该模式在面向不同任务的Transformer模型族(如LLM、BERT和视觉Transformer模型)中具有一致性。为解决该问题,我们提出逐通道激活量化,并证明这些额外的缩放因子可重参数化为权重的指数偏置,仅产生可忽略不计的计算成本。该方法首次将LLaMA-13B的权重和激活值均量化至4比特,并在常识零样本推理任务中取得63.1的平均得分,仅比全精度模型低5.8分,较之前最优方法显著提升12.7分。代码开源地址:https://github.com/nbasyl/LLM-FP4。