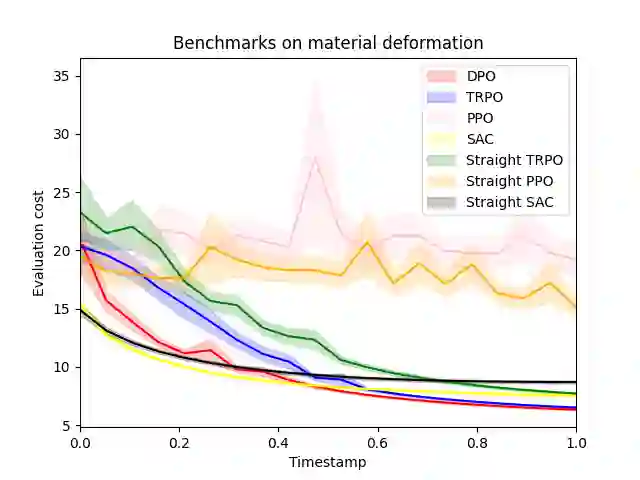
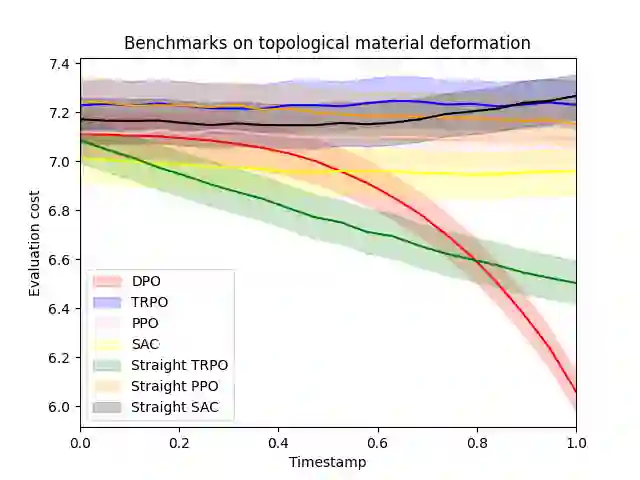
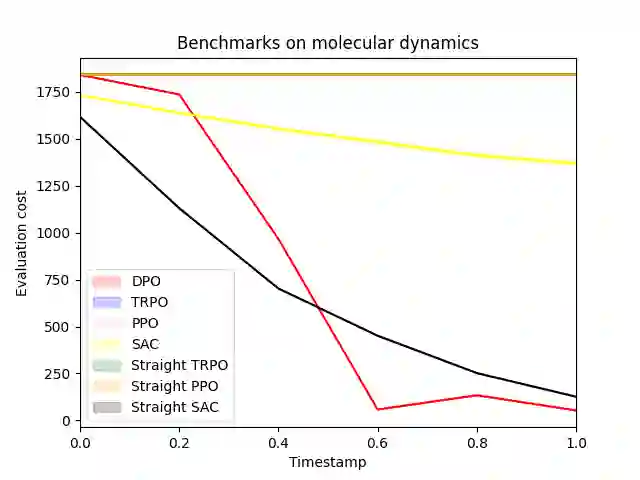
Reinforcement learning (RL) with continuous state and action spaces remains one of the most challenging problems within the field. Most current learning methods focus on integral identities such as value functions to derive an optimal strategy for the learning agent. In this paper, we instead study the dual form of the original RL formulation to propose the first differential RL framework that can handle settings with limited training samples and short-length episodes. Our approach introduces Differential Policy Optimization (DPO), a pointwise and stage-wise iteration method that optimizes policies encoded by local-movement operators. We prove a pointwise convergence estimate for DPO and provide a regret bound comparable with current theoretical works. Such pointwise estimate ensures that the learned policy matches the optimal path uniformly across different steps. We then apply DPO to a class of practical RL problems which search for optimal configurations with Lagrangian rewards. DPO is easy to implement, scalable, and shows competitive results on benchmarking experiments against several popular RL methods.
翻译:连续状态与动作空间的强化学习(RL)仍是该领域最具挑战性的问题之一。当前多数学习方法聚焦于价值函数等积分恒等式,以推导智能体的最优策略。本文转而研究原始强化学习公式的对偶形式,首次提出能够处理有限训练样本与短轨迹场景的差分强化学习框架。该方法引入差分策略优化(DPO),这是一种通过局部移动算子编码策略的逐点分阶段迭代方法。我们证明了DPO的逐点收敛估计,并给出了与当前理论工作相匹敌的遗憾界。该逐点估计确保所学策略在不同步骤间均匀逼近最优轨迹。进一步地,我们将DPO应用于一类搜索拉格朗日奖励下最优配置的实用RL问题。DPO易于实现、可扩展性强,并在多个基准实验中展现出相较多种主流RL方法的竞争力。