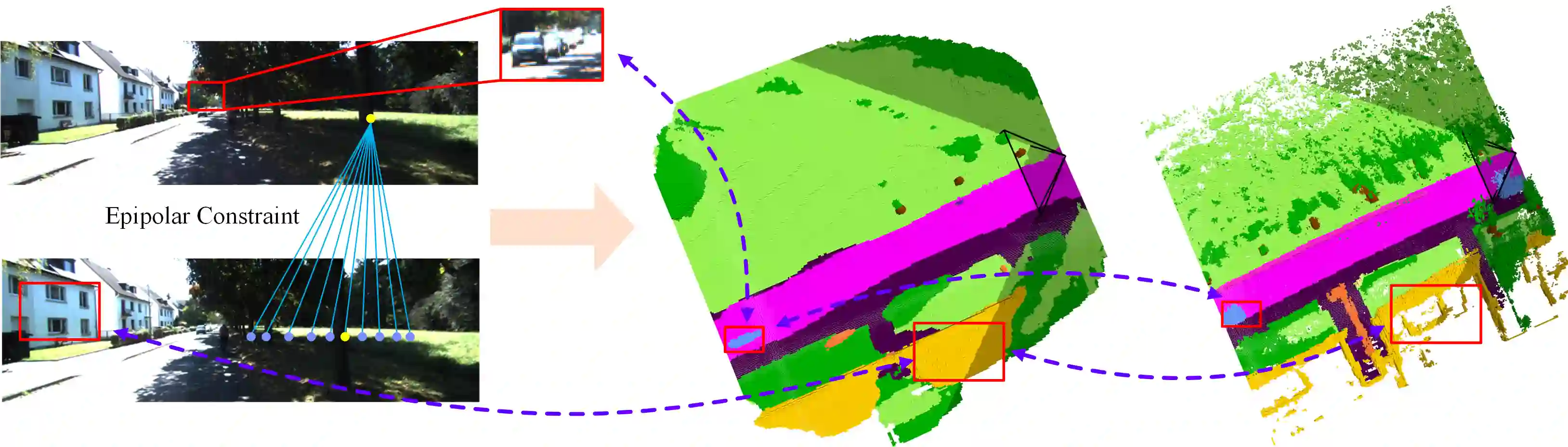
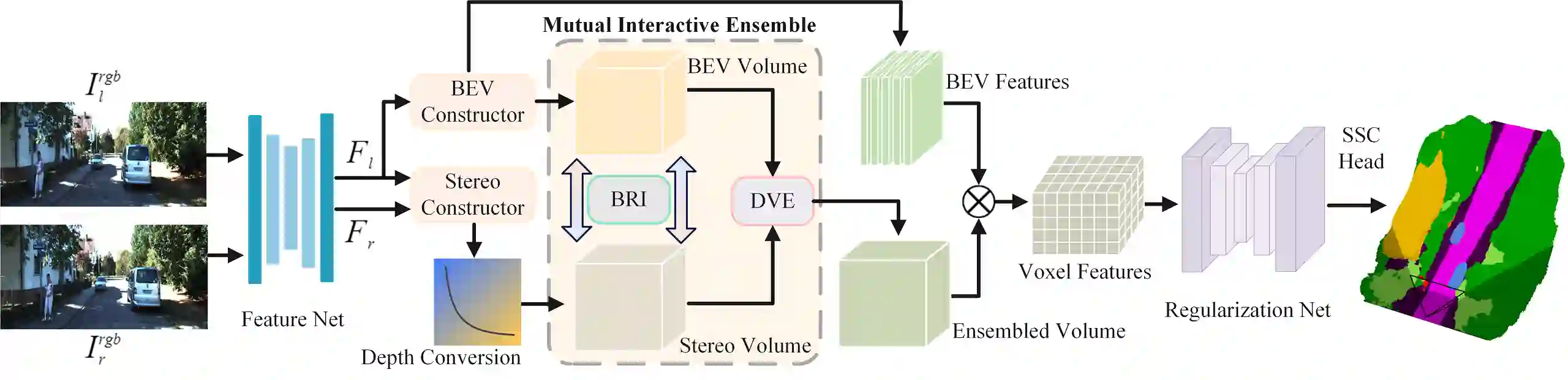
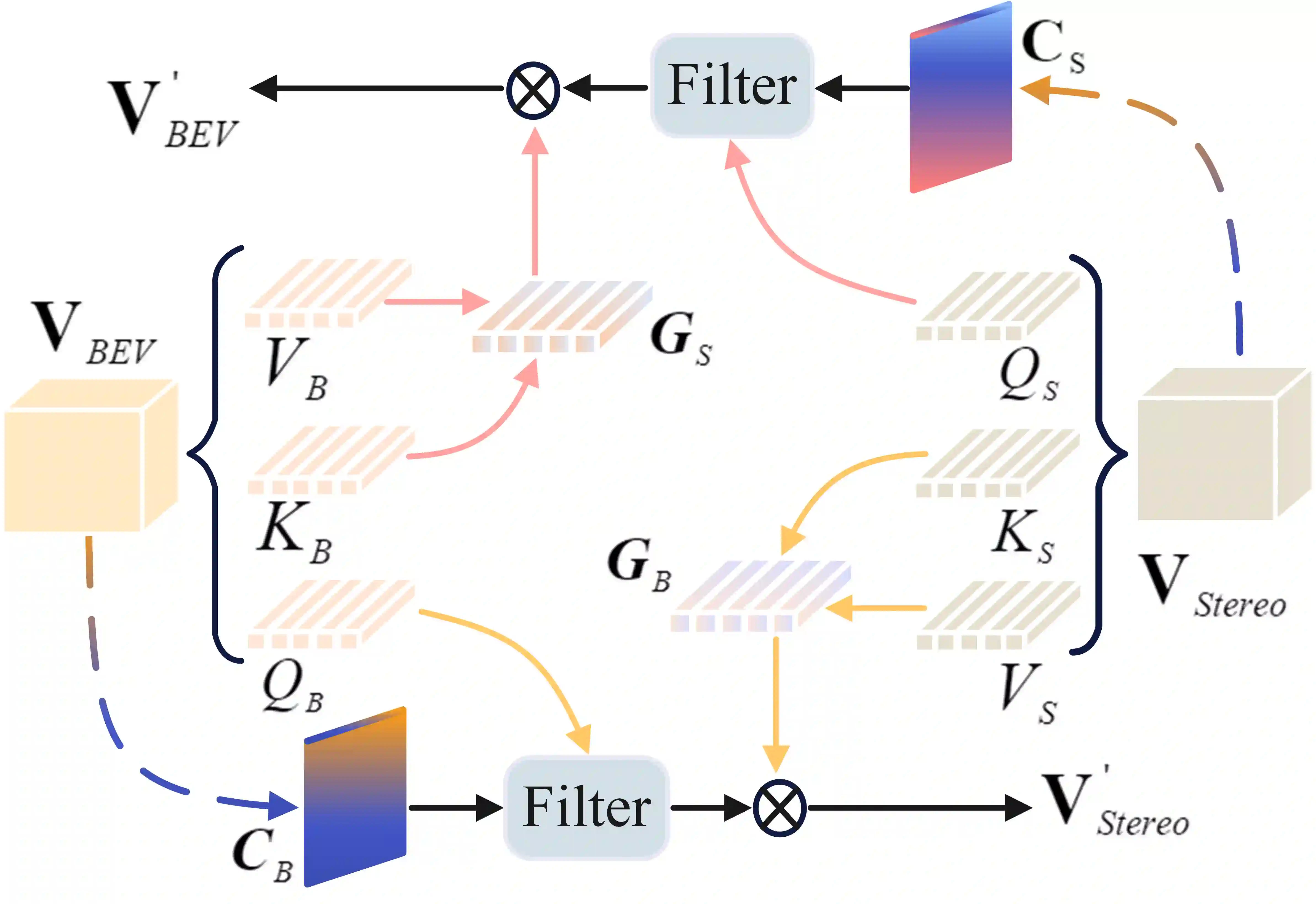
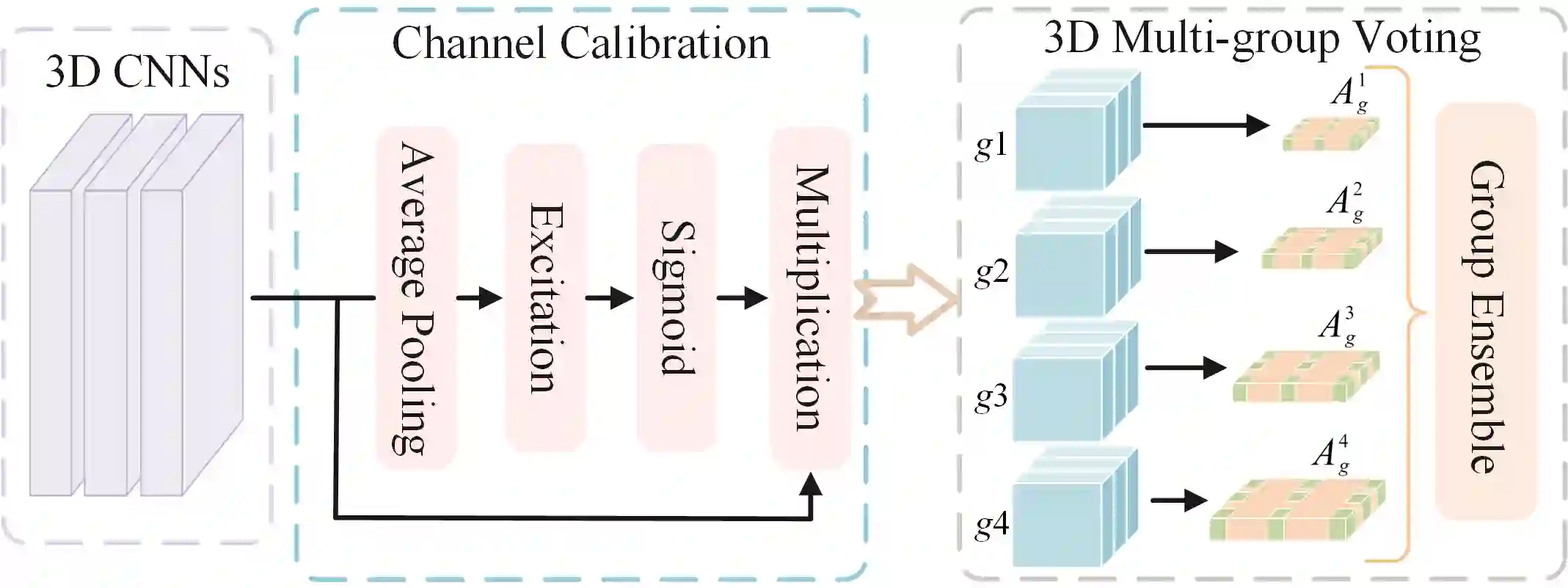
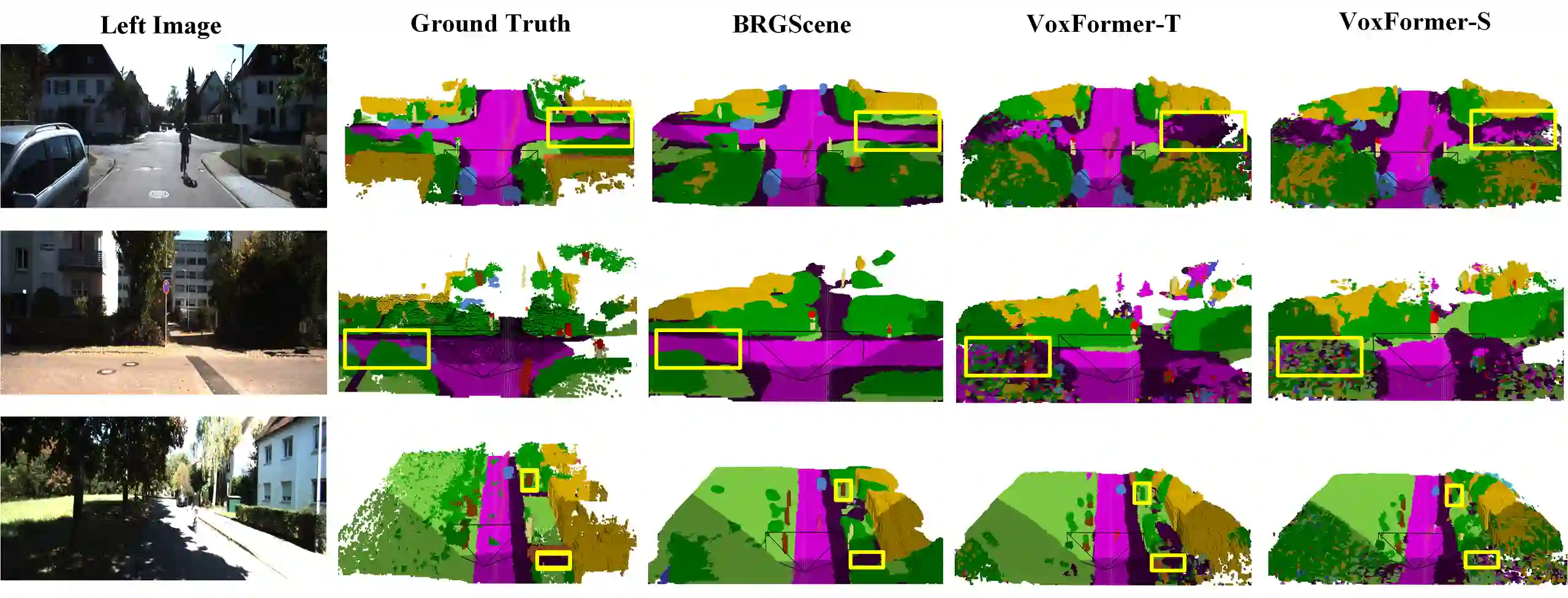
3D semantic scene completion (SSC) is an ill-posed perception task that requires inferring a dense 3D scene from limited observations. Previous camera-based methods struggle to predict accurate semantic scenes due to inherent geometric ambiguity and incomplete observations. In this paper, we resort to stereo matching technique and bird's-eye-view (BEV) representation learning to address such issues in SSC. Complementary to each other, stereo matching mitigates geometric ambiguity with epipolar constraint while BEV representation enhances the hallucination ability for invisible regions with global semantic context. However, due to the inherent representation gap between stereo geometry and BEV features, it is non-trivial to bridge them for dense prediction task of SSC. Therefore, we further develop a unified occupancy-based framework dubbed BRGScene, which effectively bridges these two representations with dense 3D volumes for reliable semantic scene completion. Specifically, we design a novel Mutual Interactive Ensemble (MIE) block for pixel-level reliable aggregation of stereo geometry and BEV features. Within the MIE block, a Bi-directional Reliable Interaction (BRI) module, enhanced with confidence re-weighting, is employed to encourage fine-grained interaction through mutual guidance. Besides, a Dual Volume Ensemble (DVE) module is introduced to facilitate complementary aggregation through channel-wise recalibration and multi-group voting. Our method outperforms all published camera-based methods on SemanticKITTI for semantic scene completion.
翻译:3D语义场景完成(SSC)是一项病态感知任务,要求从有限观测中推断出稠密3D场景。以往的基于相机的方法由于固有的几何模糊性和不完整观测,难以准确预测语义场景。本文利用立体匹配技术与鸟瞰视图(BEV)表示学习来解决SSC中的这些问题。立体匹配通过极线约束缓解几何模糊性,而BEV表示利用全局语义上下文增强对不可见区域的幻觉能力,两者相互补充。然而,由于立体几何与BEV特征之间存在固有的表示鸿沟,将其桥接用于SSC的稠密预测任务并非易事。为此,我们进一步开发了统一基于占用率的框架BRGScene,通过稠密3D体素有效桥接这两种表示,实现可靠的语义场景完成。具体而言,我们设计了新颖的互交互集成(MIE)模块,用于像素级可靠聚合立体几何与BEV特征。在MIE块中,采用双向可靠交互(BRI)模块,结合置信度重加权,通过相互引导促进细粒度交互。此外,引入双体积集成(DVE)模块,通过通道级重校准和多组投票实现互补聚合。我们的方法在SemanticKITTI数据集上的语义场景完成任务中,性能超越所有已发表的基于相机的方法。