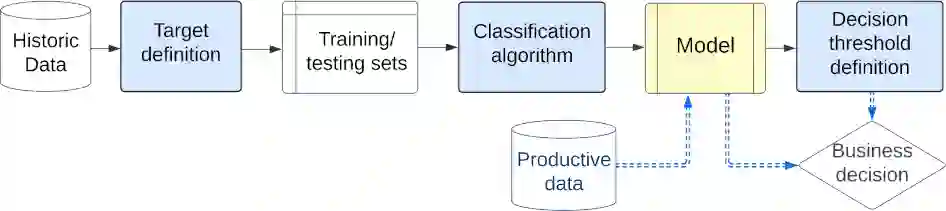
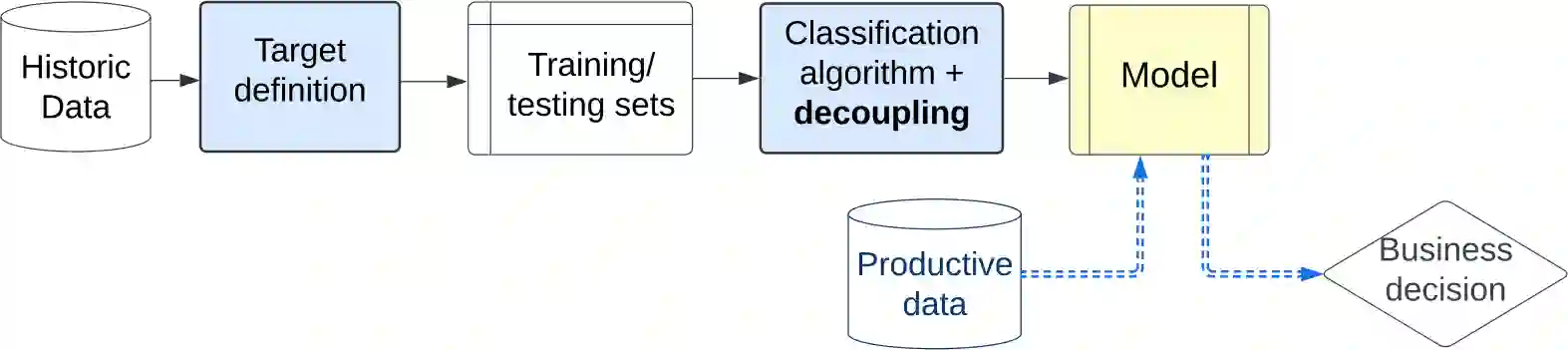
Machine learning models typically focus on specific targets like creating classifiers, often based on known population feature distributions in a business context. However, models calculating individual features adapt over time to improve precision, introducing the concept of decoupling: shifting from point evaluation to data distribution. We use calibration strategies as strategy for decoupling machine learning (ML) classifiers from score-based actions within business logic frameworks. To evaluate these strategies, we perform a comparative analysis using a real-world business scenario and multiple ML models. Our findings highlight the trade-offs and performance implications of the approach, offering valuable insights for practitioners seeking to optimize their decoupling efforts. In particular, the Isotonic and Beta calibration methods stand out for scenarios in which there is shift between training and testing data.
翻译:机器学习模型通常专注于特定目标,例如创建分类器,通常基于业务场景中已知的总体特征分布。然而,计算个体特征的模型会随时间调整以提高精度,从而引入解耦概念:从点评估转向数据分布。我们采用校准策略,作为在业务逻辑框架内将机器学习(ML)分类器与基于分数的行动解耦的方法。为了评估这些策略,我们利用真实业务场景和多种ML模型进行了比较分析。我们的研究结果凸显了该方法的权衡与性能影响,为寻求优化解耦工作的从业者提供了宝贵见解。特别是,在训练数据和测试数据之间存在分布偏移的场景中,等温校准和贝塔校准方法表现突出。