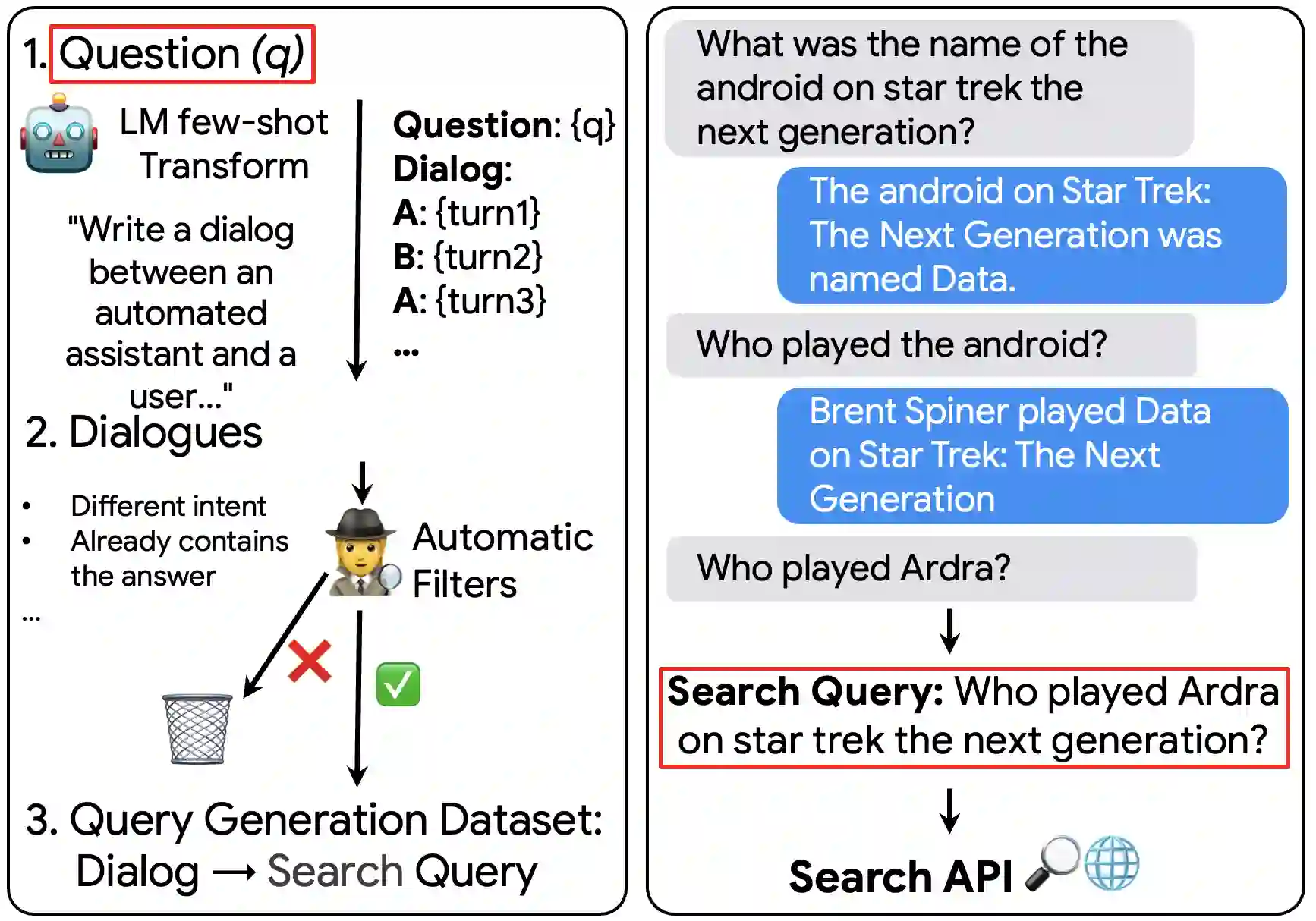
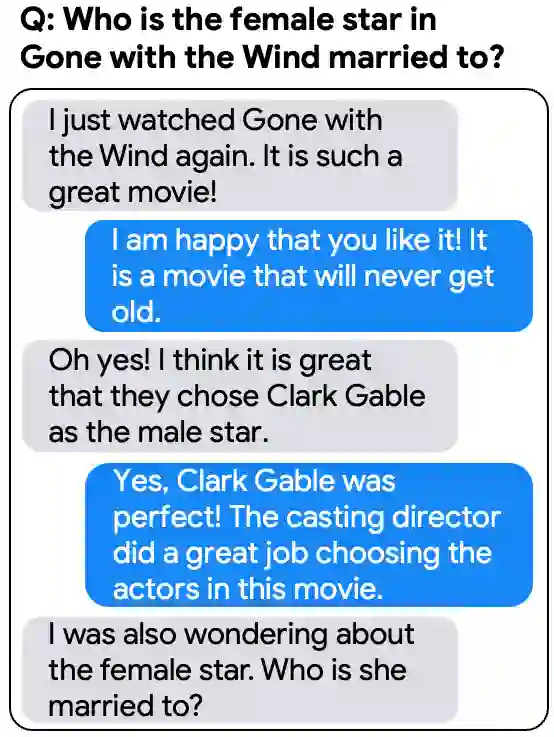
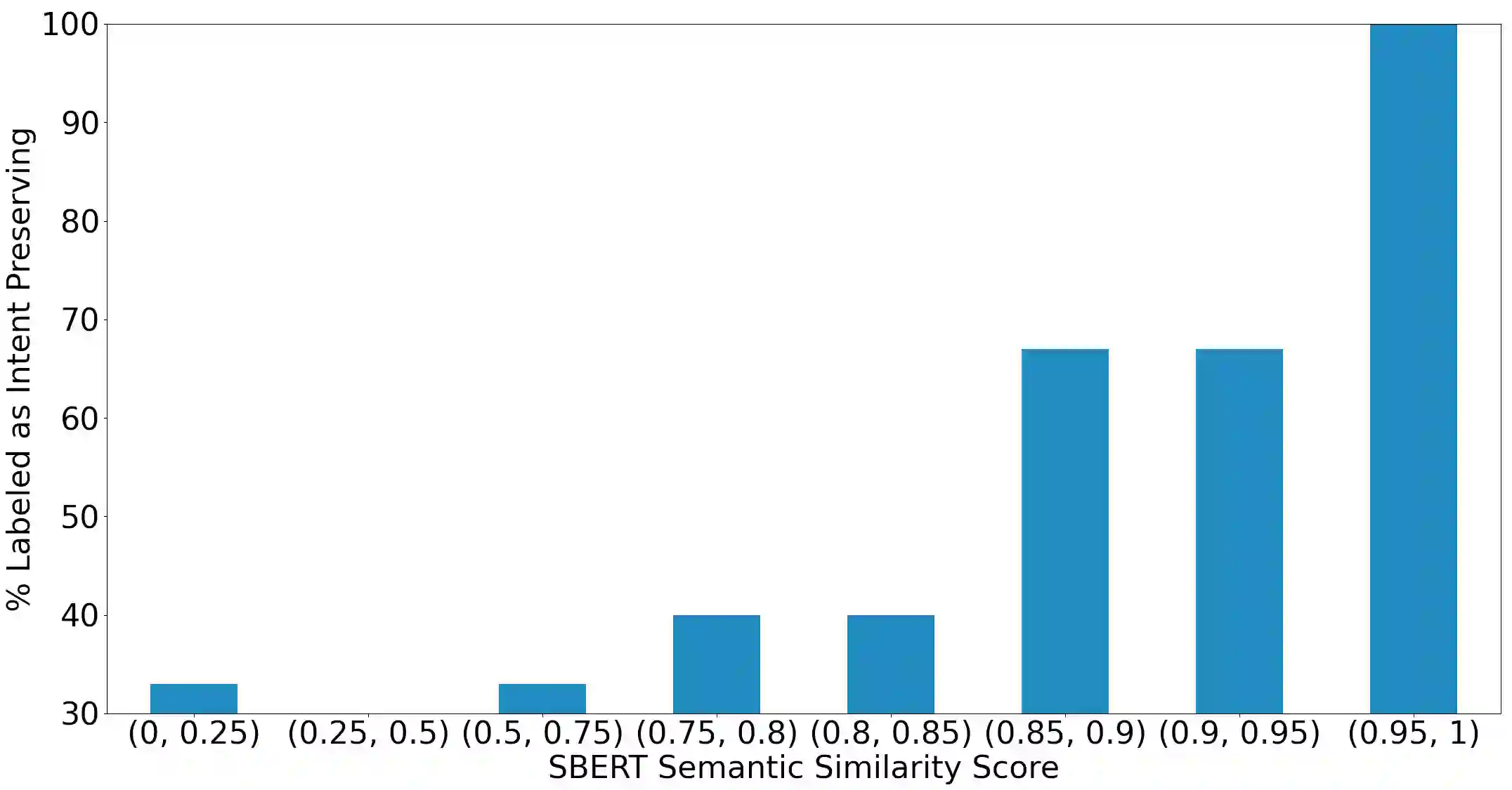
One of the exciting capabilities of recent language models for dialog is their ability to independently search for relevant information to ground a given dialog response. However, obtaining training data to teach models how to issue search queries is time and resource consuming. In this work, we propose q2d: an automatic data generation pipeline that generates information-seeking dialogs from questions. We prompt a large language model (PaLM) to create conversational versions of question answering datasets, and use it to improve query generation models that communicate with external search APIs to ground dialog responses. Unlike previous approaches which relied on human written dialogs with search queries, our method allows to automatically generate query-based grounded dialogs with better control and scale. Our experiments demonstrate that: (1) For query generation on the QReCC dataset, models trained on our synthetically-generated data achieve 90%--97% of the performance of models trained on the human-generated data; (2) We can successfully generate data for training dialog models in new domains without any existing dialog data as demonstrated on the multi-hop MuSiQue and Bamboogle QA datasets. (3) We perform a thorough analysis of the generated dialogs showing that humans find them of high quality and struggle to distinguish them from human-written dialogs.
翻译:近年来,对话语言模型的一项令人振奋的能力是它们能独立搜索相关信息以支撑特定对话回复。然而,获取训练数据来教导模型如何发出搜索查询既耗时又消耗资源。在本工作中,我们提出q2d:一种自动数据生成流水线,能从问题生成信息寻求型对话。我们提示大型语言模型(PaLM)为问答数据集创建对话版本,并利用它改进与外部搜索API通信以支撑对话回复的查询生成模型。不同于以往依赖人工编写含搜索查询的对话的方法,我们的方法能够以更好的可控性和规模自动生成基于查询的支撑型对话。实验表明:(1)在QReCC数据集上,使用合成数据训练的查询生成模型能达到人类数据训练模型性能的90%-97%;(2)我们能在无任何现有对话数据的新领域成功生成训练对话模型的训练数据,这在多跳MuSiQue和Bamboogle问答数据集上得到验证;(3)我们对生成的对话进行了全面分析,表明人类认为其质量较高,且难以将其与人类编写的对话区分开来。