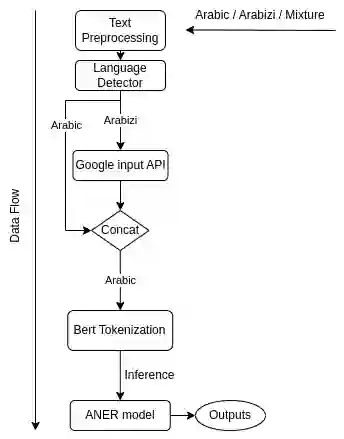
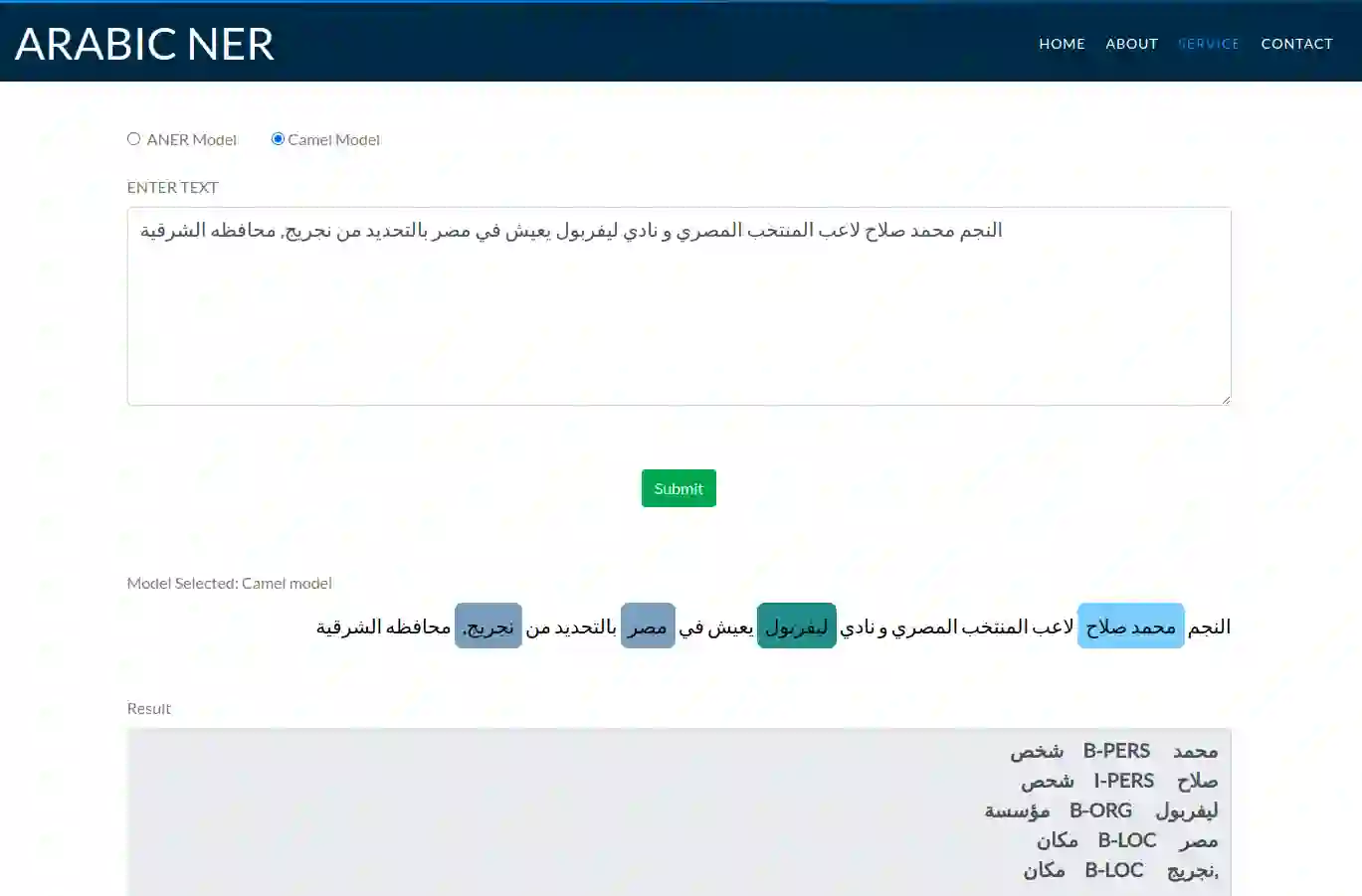
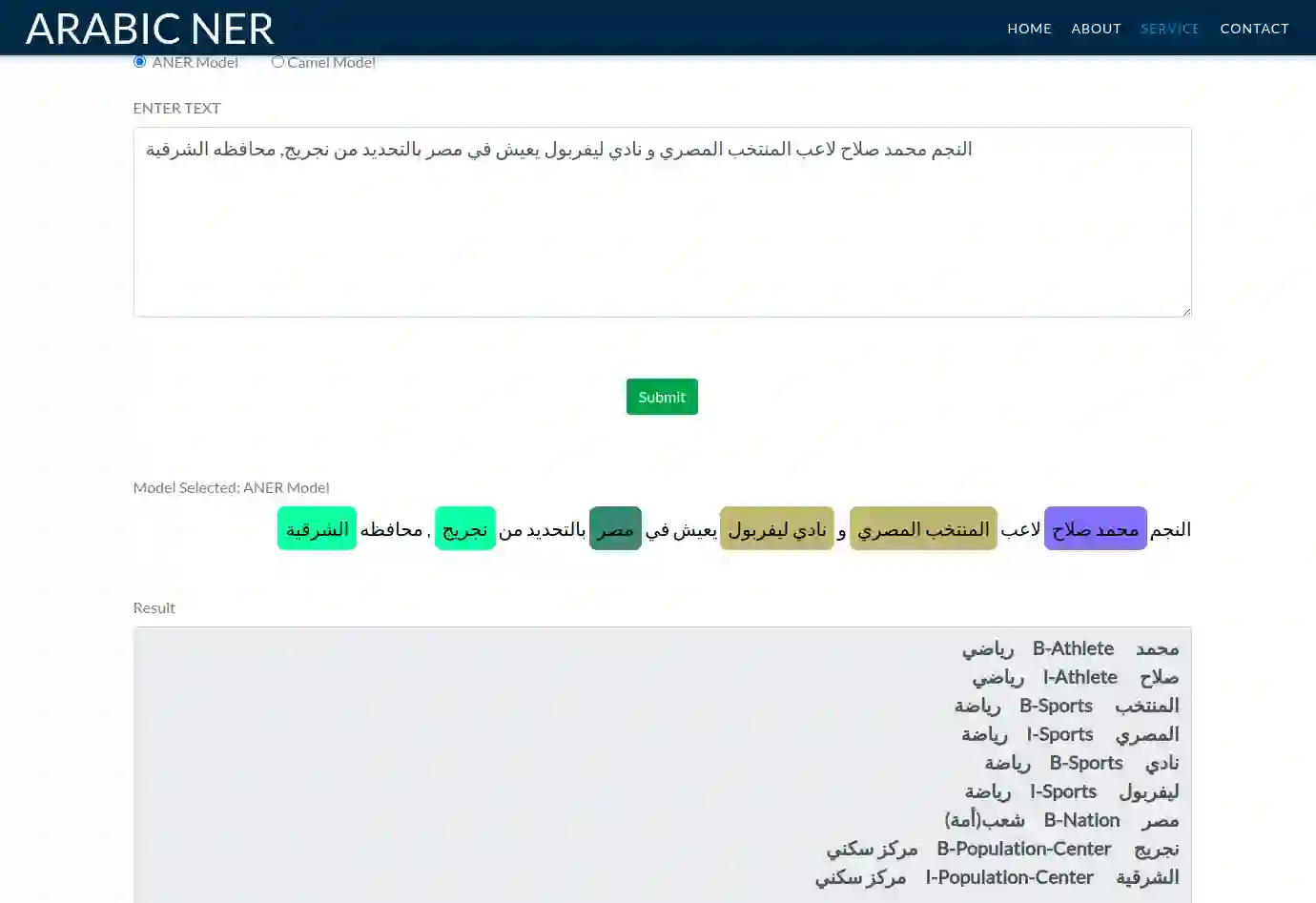
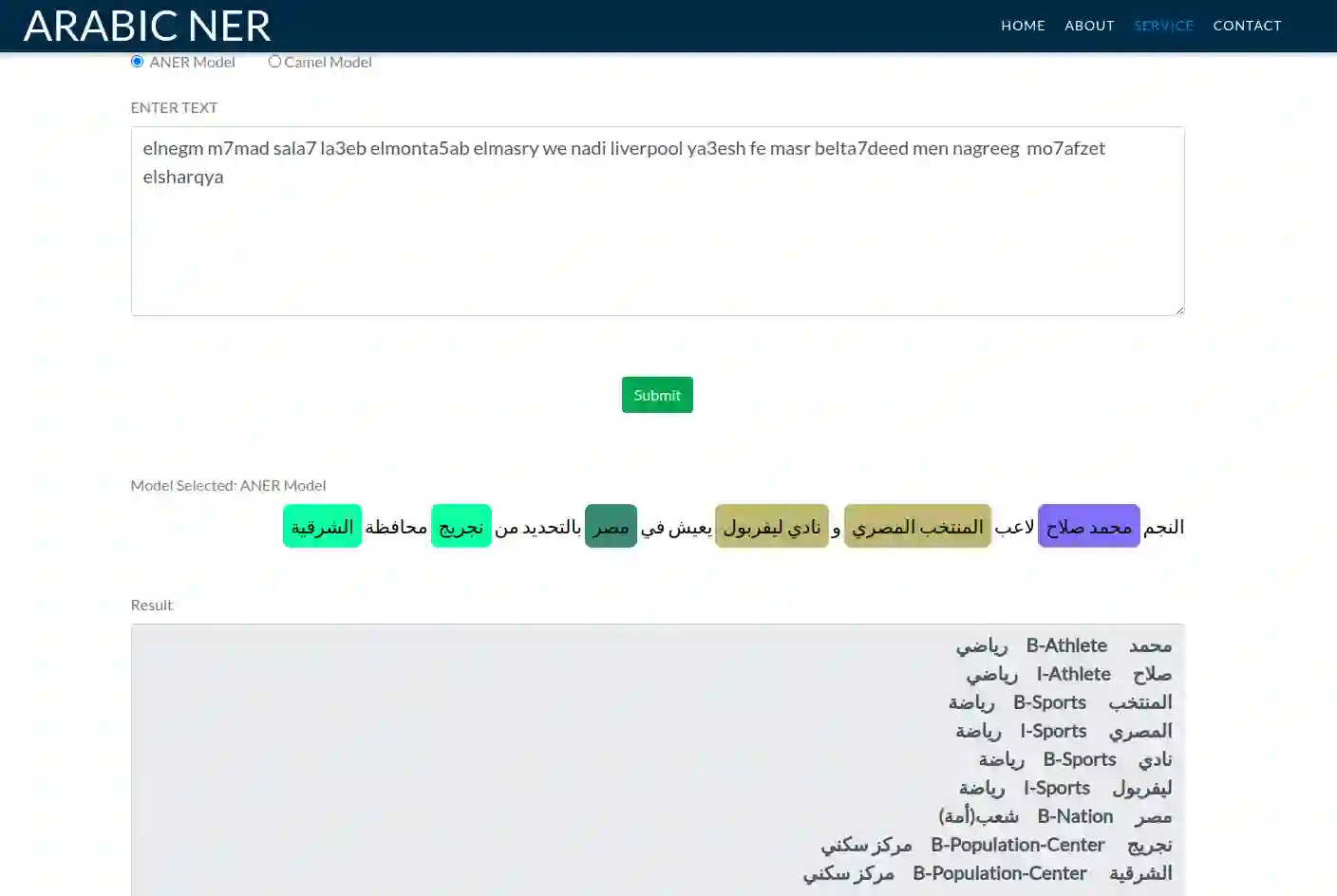
One of the main tasks of Natural Language Processing (NLP), is Named Entity Recognition (NER). It is used in many applications and also can be used as an intermediate step for other tasks. We present ANER, a web-based named entity recognizer for the Arabic, and Arabizi languages. The model is built upon BERT, which is a transformer-based encoder. It can recognize 50 different entity classes, covering various fields. We trained our model on the WikiFANE\_Gold dataset which consists of Wikipedia articles. We achieved an F1 score of 88.7\%, which beats CAMeL Tools' F1 score of 83\% on the ANERcorp dataset, which has only 4 classes. We also got an F1 score of 77.7\% on the NewsFANE\_Gold dataset which contains out-of-domain data from News articles. The system is deployed on a user-friendly web interface that accepts users' inputs in Arabic, or Arabizi. It allows users to explore the entities in the text by highlighting them. It can also direct users to get information about entities through Wikipedia directly. We added the ability to do NER using our model, or CAMeL Tools' model through our website. ANER is publicly accessible at \url{http://www.aner.online}. We also deployed our model on HuggingFace at https://huggingface.co/boda/ANER, to allow developers to test and use it.
翻译:自然语言处理(NLP)的主要任务之一是命名实体识别(NER)。它广泛应用于多个领域,也可作为其他任务的中间步骤。我们提出ANER,一个面向阿拉伯语和阿拉伯齐语的基于Web的命名实体识别器。该模型基于Transformer架构的编码器BERT构建,能够识别涵盖多种领域的50个不同实体类别。我们使用由维基百科文章构成的WikiFANE\_Gold数据集训练模型,取得了88.7%的F1分数,优于CAMeL工具在仅含4个类别的ANERcorp数据集上83%的F1分数。在包含新闻文章领域外数据的NewsFANE\_Gold数据集上,我们同样取得了77.7%的F1分数。该系统部署于用户友好的Web界面,接受用户输入的阿拉伯语或阿拉伯齐语文本,通过高亮标记帮助用户探索文本中的实体,并能直接引导用户通过维基百科获取实体信息。我们还通过网站提供了使用本模型或CAMeL工具模型进行NER的功能。ANER可通过\url{http://www.aner.online}公开访问,模型已部署在HuggingFace社区:https://huggingface.co/boda/ANER,便于开发者测试与使用。