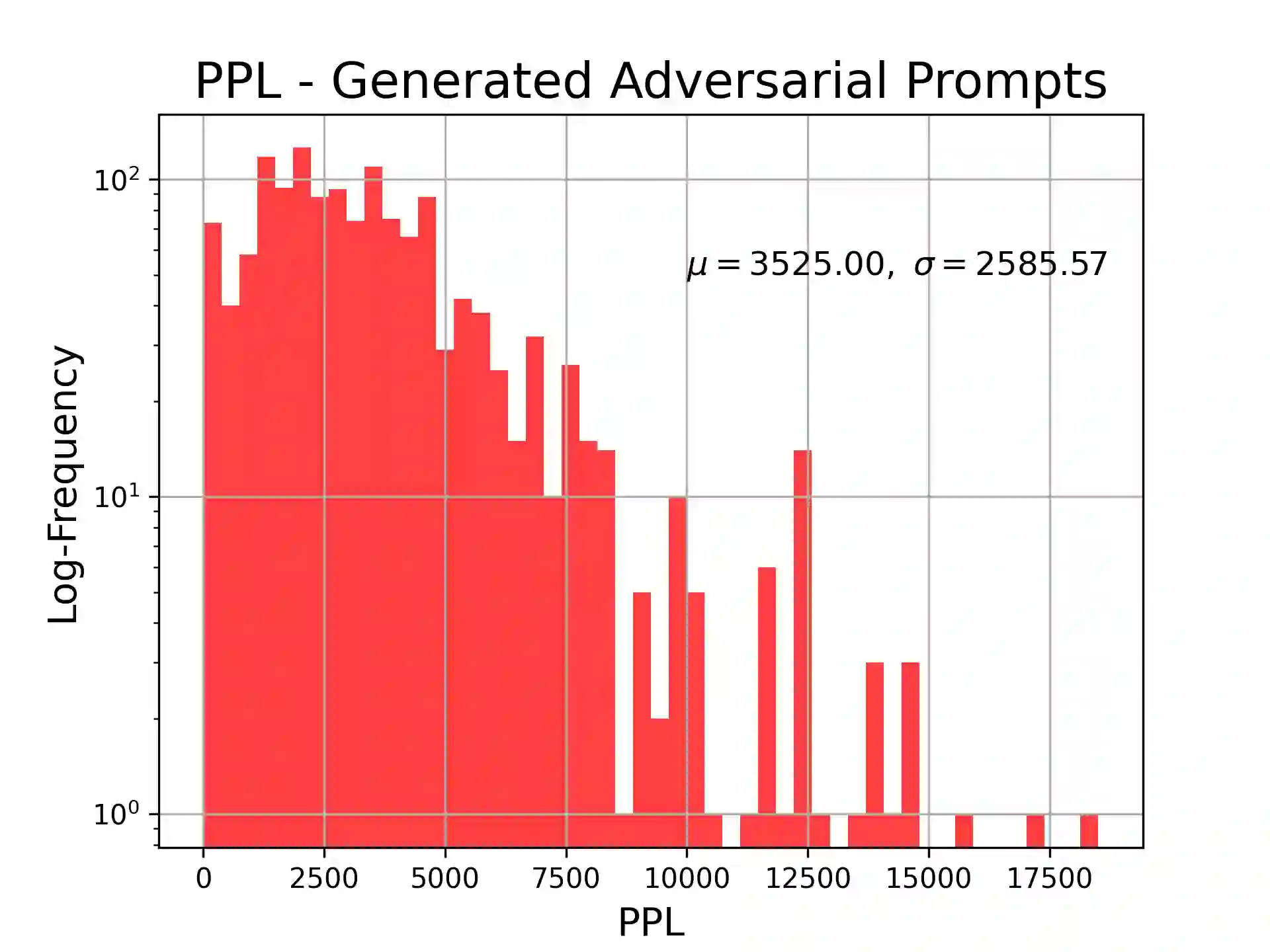
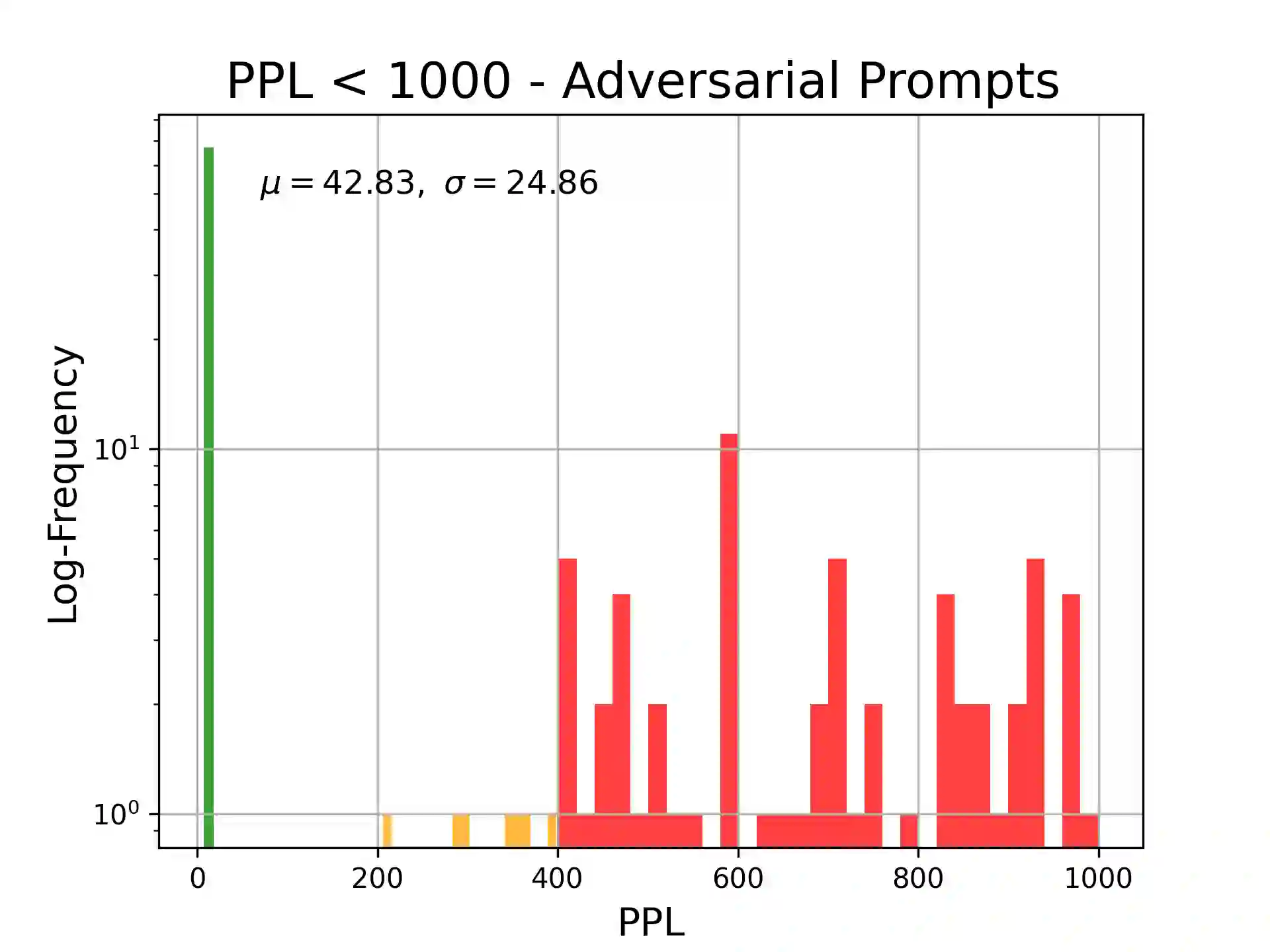
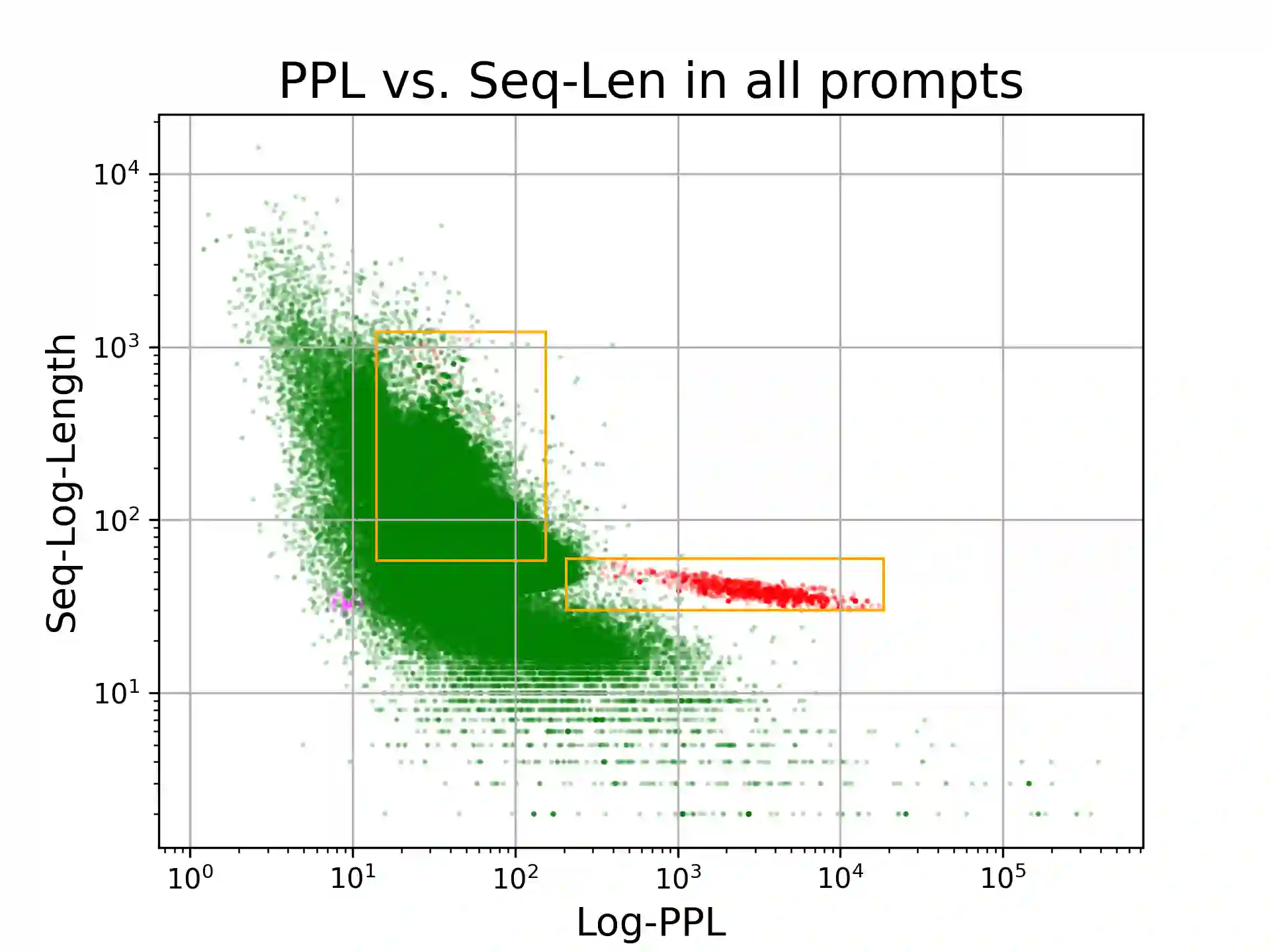
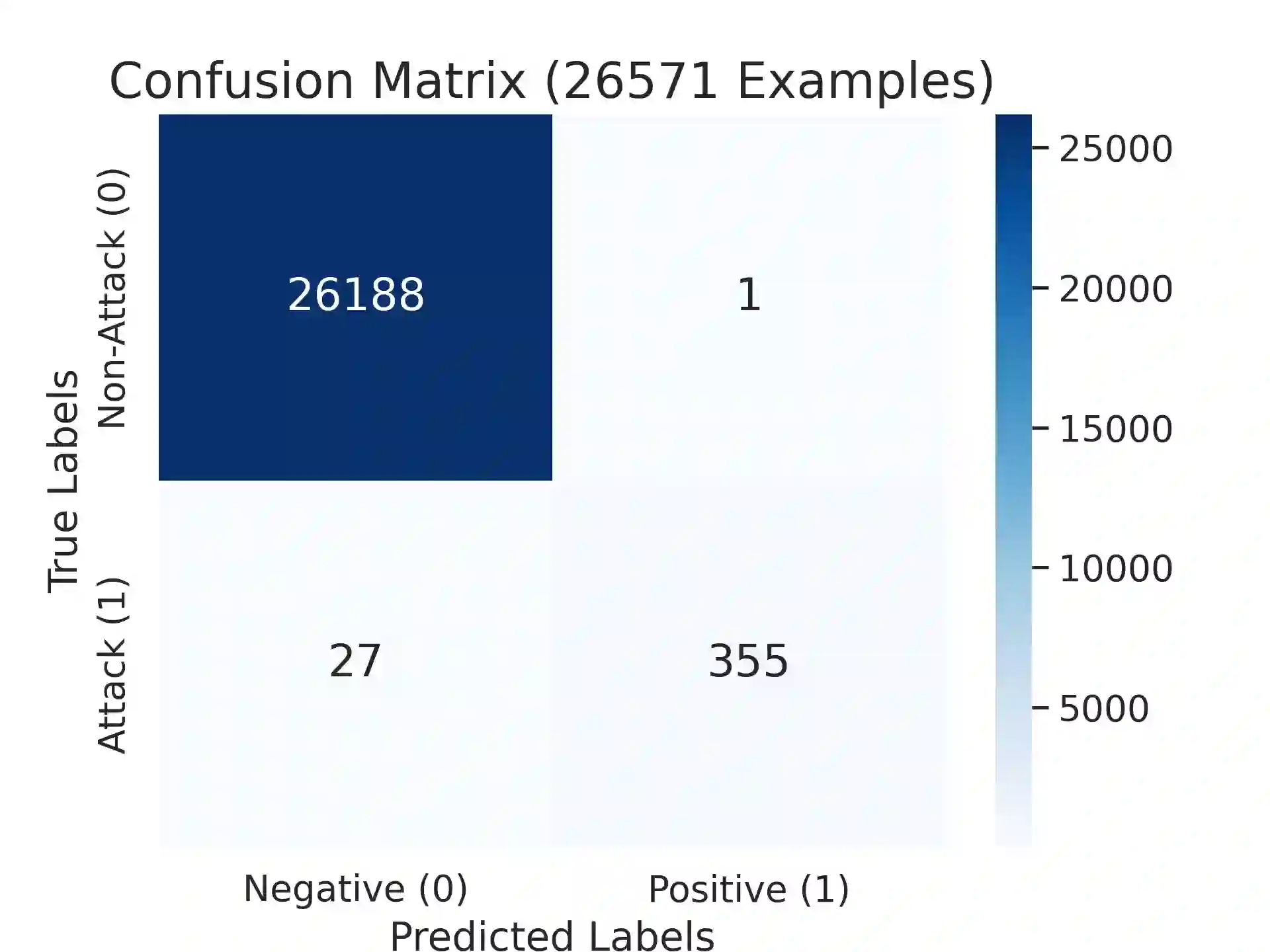
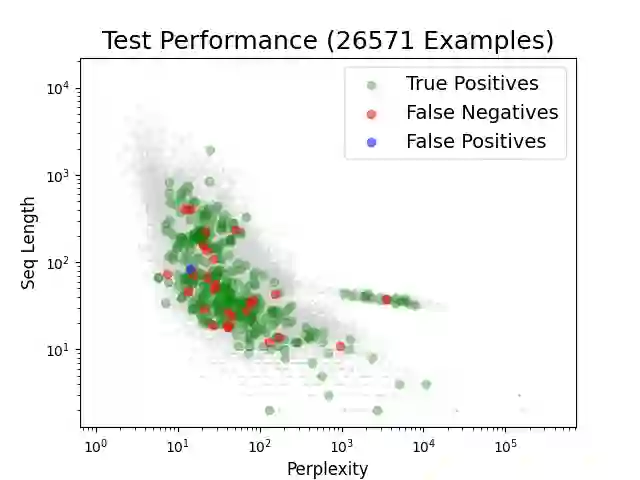
A novel hack involving Large Language Models (LLMs) has emerged, exploiting adversarial suffixes to deceive models into generating perilous responses. Such jailbreaks can trick LLMs into providing intricate instructions to a malicious user for creating explosives, orchestrating a bank heist, or facilitating the creation of offensive content. By evaluating the perplexity of queries with adversarial suffixes using an open-source LLM (GPT-2), we found that they have exceedingly high perplexity values. As we explored a broad range of regular (non-adversarial) prompt varieties, we concluded that false positives are a significant challenge for plain perplexity filtering. A Light-GBM trained on perplexity and token length resolved the false positives and correctly detected most adversarial attacks in the test set.
翻译:一种涉及大型语言模型(LLM)的新型黑客手段已经出现,它利用对抗性后缀欺骗模型生成危险响应。此类越狱攻击可诱使LLM为恶意用户提供制造爆炸物、策划银行抢劫或生成攻击性内容的复杂指令。通过使用开源LLM(GPT-2)评估含对抗性后缀查询的困惑度,我们发现其困惑度值异常偏高。当探索广泛类型的常规(非对抗性)提示时,我们得出结论:纯困惑度过滤面临假阳性这一重大挑战。基于困惑度与标记长度训练的Light-GBM模型解决了假阳性问题,并能正确检测测试集中的大多数对抗性攻击。